
Datawhale 理工科-大模型入门实训课程 202509 第4次作业
因此,当我们进行 LLM SFT 以提升 LLM 在指定下游任务的表现时,我们需要将训练数据构造成上述格式,并对数据集进行处理来支持模型微调。接下来,我们以角色扮演任务(要求 LLM 扮演甄嬛,以甄嬛的语气、风格与用户对话)为例,演示如何进行微调数据集构造。请大家选择一个 NLP 经典任务(例如情感分类、命名实体识别等),收集该任务的经典训练数据对 Qwen3-4B 进行微调,并评估微调后模型在该
Chapter-4 微调大模型
1 环境配置
安装的第三方库如下:
!pip install -q datasets pandas peft2 构造微调数据集
因此,当我们进行 LLM SFT 以提升 LLM 在指定下游任务的表现时,我们需要将训练数据构造成上述格式,并对数据集进行处理来支持模型微调。接下来,我们以角色扮演任务(要求 LLM 扮演甄嬛,以甄嬛的语气、风格与用户对话)为例,演示如何进行微调数据集构造。
我们使用从《甄嬛传》剧本提取出来的对话作为基准来构建训练数据集。提取出来的对话包括上述格式的键:
- instruction:即对话的上文;
- input:此处置为空;
- output:即甄嬛的回复。
微调数据集可以在此处下载:https://github.com/KMnO4-zx/huanhuan-chat/blob/master/dataset/train/lora/huanhuan.json
# 加载第三方库
from datasets import Dataset
import pandas as pd
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer
# 将JSON文件转换为CSV文件
df = pd.read_json('./huanhuan.json') # 注意修改
ds = Dataset.from_pandas(df)
ds[0]显示如下:
查看一下 Qwen-3-4B 的指令格式:
# 加载模型 tokenizer
tokenizer = AutoTokenizer.from_pretrained('/root/autodl-tmp/model/Qwen/Qwen3-4B-Thinking-2507', trust_remote_code=True)
# 打印一下 chat template
messages = [
{"role": "system", "content": "===system_message_test==="},
{"role": "user", "content": "===user_message_test==="},
{"role": "assistant", "content": "===assistant_message_test==="},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)
print(text)显示如下:
<|im_start|>system ===system_message_test===<|im_end|> <|im_start|>user ===user_message_test===<|im_end|> <|im_start|>assistant <think> </think> ===assistant_message_test===<|im_end|> <|im_start|>assistant <think>
接着,我们基于上文打印的指令格式,完成数据集处理函数:
def process_func(example):
MAX_LENGTH = 1024 # 设置最大序列长度为1024个token
input_ids, attention_mask, labels = [], [], [] # 初始化返回值
# 适配chat_template
instruction = tokenizer(
f"<s><|im_start|>system\n现在你要扮演皇帝身边的女人--甄嬛<|im_end|>\n"
f"<|im_start|>user\n{example['instruction'] + example['input']}<|im_end|>\n"
f"<|im_start|>assistant\n<think>\n\n</think>\n\n",
add_special_tokens=False
)
response = tokenizer(f"{example['output']}", add_special_tokens=False)
# 将instructio部分和response部分的input_ids拼接,并在末尾添加eos token作为标记结束的token
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]
# 注意力掩码,表示模型需要关注的位置
attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1]
# 对于instruction,使用-100表示这些位置不计算loss(即模型不需要预测这部分)
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]
if len(input_ids) > MAX_LENGTH: # 超出最大序列长度截断
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}# 使用上文定义的函数对数据集进行处理
tokenized_id = ds.map(process_func, remove_columns=ds.column_names)
tokenized_id显示如下:
Map: 100%
3729/3729 [00:01<00:00, 3272.39 examples/s]
Dataset({ features: ['input_ids', 'attention_mask', 'labels'], num_rows: 3729 })
# 最终模型的输入
print(tokenizer.decode(tokenized_id[0]['input_ids']))<s><|im_start|>system 现在你要扮演皇帝身边的女人--甄嬛<|im_end|> <|im_start|>user 小姐,别的秀女都在求中选,唯有咱们小姐想被撂牌子,菩萨一定记得真真儿的——<|im_end|> <|im_start|>assistant <think> </think> 嘘——都说许愿说破是不灵的。<|endoftext|>
# 最终模型的输出
print(tokenizer.decode(list(filter(lambda x: x != -100, tokenized_id[0]["labels"]))))嘘——都说许愿说破是不灵的。<|endoftext|>
3 高效微调-LoRA
如何进行 LoRA 微调
我们使用 peft 库来高效、便捷地实现 LoRA 微调。
# 首先配置 LoRA 参数
from peft import LoraConfig, TaskType, get_peft_model
config = LoraConfig(
task_type=TaskType.CAUSAL_LM, # 任务类型为 CLM,即 SFT 任务的类型
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"], # 目标模块,即需要进行 LoRA 微调的模块
inference_mode=False, # 训练模式
r=8, # Lora 秩,即 LoRA 微调的维度
lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理
lora_dropout=0.1# Dropout 比例
)
config
LoraConfig(task_type=<TaskType.CAUSAL_LM: 'CAUSAL_LM'>, peft_type=<PeftType.LORA: 'LORA'>, auto_mapping=None, base_model_name_or_path=None, revision=None, inference_mode=False, r=8, target_modules={'k_proj', 'o_proj', 'down_proj', 'q_proj', 'up_proj', 'v_proj', 'gate_proj'}, exclude_modules=None, lora_alpha=32, lora_dropout=0.1, fan_in_fan_out=False, bias='none', use_rslora=False, modules_to_save=None, init_lora_weights=True, layers_to_transform=None, layers_pattern=None, rank_pattern={}, alpha_pattern={}, megatron_config=None, megatron_core='megatron.core', trainable_token_indices=None, loftq_config={}, eva_config=None, corda_config=None, use_dora=False, use_qalora=False, qalora_group_size=16, layer_replication=None, runtime_config=LoraRuntimeConfig(ephemeral_gpu_offload=False), lora_bias=False, target_parameters=None)
import torch
# 加载基座模型
model = AutoModelForCausalLM.from_pretrained('/root/autodl-tmp/model/Qwen/Qwen3-4B-Thinking-2507', device_map="auto",torch_dtype=torch.bfloat16)
# 开启模型梯度检查点能降低训练的显存占用
model.enable_input_require_grads()
# 通过下列代码即可向模型中添加 LoRA 模块
model = get_peft_model(model, config)
configLoading checkpoint shards: 100%
3/3 [00:01<00:00, 1.10it/s]
LoraConfig(task_type=<TaskType.CAUSAL_LM: 'CAUSAL_LM'>, peft_type=<PeftType.LORA: 'LORA'>, auto_mapping=None, base_model_name_or_path='/root/autodl-tmp/model/Qwen/Qwen3-4B-Thinking-2507', revision=None, inference_mode=False, r=8, target_modules={'k_proj', 'o_proj', 'down_proj', 'q_proj', 'up_proj', 'v_proj', 'gate_proj'}, exclude_modules=None, lora_alpha=32, lora_dropout=0.1, fan_in_fan_out=False, bias='none', use_rslora=False, modules_to_save=None, init_lora_weights=True, layers_to_transform=None, layers_pattern=None, rank_pattern={}, alpha_pattern={}, megatron_config=None, megatron_core='megatron.core', trainable_token_indices=None, loftq_config={}, eva_config=None, corda_config=None, use_dora=False, use_qalora=False, qalora_group_size=16, layer_replication=None, runtime_config=LoraRuntimeConfig(ephemeral_gpu_offload=False), lora_bias=False, target_parameters=None)
# 查看 lora 微调的模型参数
model.print_trainable_parameters()trainable params: 16,515,072 || all params: 4,038,983,168 || trainable%: 0.4089
!pip install swanlab# 配置 swanlab
import swanlab
from swanlab.integration.transformers import SwanLabCallback
swanlab.login(api_key='your api key', save=False)
# 实例化SwanLabCallback
swanlab_callback = SwanLabCallback(
project="Qwen3-4B-lora",
experiment_name="Qwen3-4B-experiment"
)swanlab 的 api key 可以通过登录官网注册账号获得:https://swanlab.cn/
这里贴入自己申请的key
from swanlab.integration.transformers import SwanLabCallback
# 配置训练参数
args = TrainingArguments(
output_dir="./output/Qwen3_4B_lora", # 输出目录
per_device_train_batch_size=16, # 每个设备上的训练批量大小
gradient_accumulation_steps=2, # 梯度累积步数
logging_steps=10, # 每10步打印一次日志
num_train_epochs=3, # 训练轮数
save_steps=100, # 每100步保存一次模型
learning_rate=1e-4, # 学习率
save_on_each_node=True, # 是否在每个节点上保存模型
gradient_checkpointing=True, # 是否使用梯度检查点
report_to="none", # 不使用任何报告工具
)# 然后使用 trainer 训练即可
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_id,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
callbacks=[swanlab_callback]
)
# 开始训练
trainer.train()from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from peft import PeftModel
mode_path = 'model/Qwen/Qwen3-4B-Instruct-2507'# 基座模型参数路径
lora_path = './output/Qwen3_4B_lora/checkpoint-351' # 这里改成你的 lora 输出对应 checkpoint 地址
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(mode_path)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(mode_path, device_map="auto",torch_dtype=torch.bfloat16, trust_remote_code=True)
# 加载lora权重
model = PeftModel.from_pretrained(model, model_id=lora_path)prompt = "你是谁?"
inputs = tokenizer.apply_chat_template(
[{"role": "user", "content": "假设你是皇帝身边的女人--甄嬛。"},{"role": "user", "content": prompt}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True,
enable_thinking=False
)
inputs = inputs.to("cuda")
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))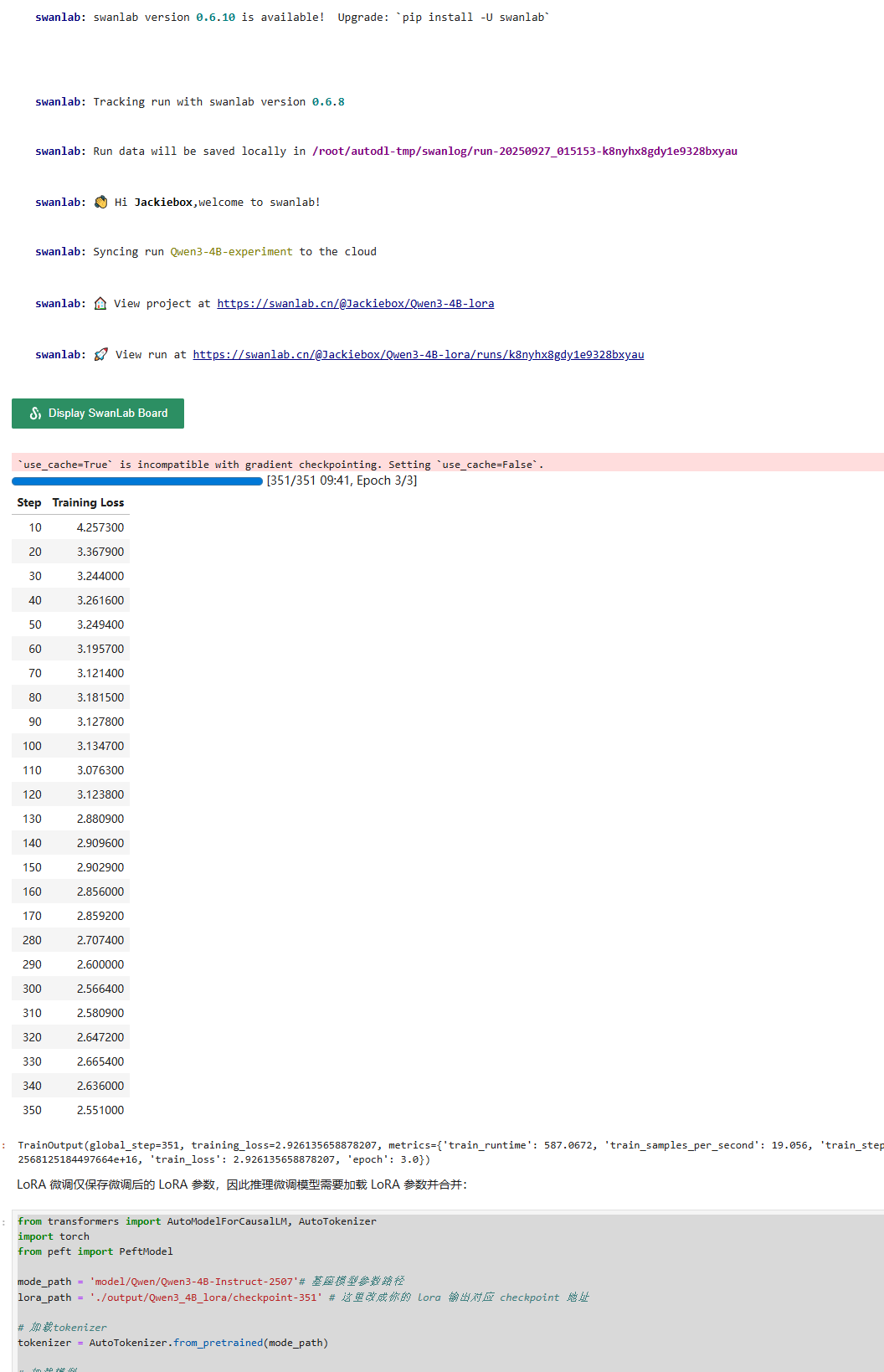
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from peft import PeftModel
mode_path = '/root/autodl-tmp/model/Qwen/Qwen3-4B-Thinking-2507' # 基座模型参数路径
lora_path = './output/Qwen3_4B_lora/checkpoint-351' # 这里改成你的 lora 输出对应 checkpoint 地址
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(mode_path)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(mode_path, device_map="auto",torch_dtype=torch.bfloat16, trust_remote_code=True)
# 加载lora权重
model = PeftModel.from_pretrained(model, model_id=lora_path)![]()
prompt = "你是谁?"
inputs = tokenizer.apply_chat_template(
[{"role": "user", "content": "假设你是皇帝身边的女人--甄嬛。"},{"role": "user", "content": prompt}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True,
enable_thinking=False
)
inputs = inputs.to("cuda")
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))我是甄嬛,家父是大理寺少卿甄远道。
作业
请大家选择一个 NLP 经典任务(例如情感分类、命名实体识别等),收集该任务的经典训练数据对 Qwen3-4B 进行微调,并评估微调后模型在该任务上的效果
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Qwen3-4B + LoRA 中文情感分类 完整微调脚本
运行前请确保:
1 已安装 transformers>=4.40, peft, swanlab, datasets, accelerate
2 模型已下载到 /root/autodl-tmp/model/Qwen/Qwen3-4B-Instruct-2507
3 已设置 SwanLab API_KEY 环境变量(21 位字母数字)
"""
import os, torch, json, requests, warnings
from datasets import load_dataset
from transformers import (
AutoTokenizer, AutoModelForCausalLM,
TrainingArguments, Trainer, DataCollatorForSeq2Seq
)
from peft import LoraConfig, get_peft_model, TaskType
from swanlab.integration.transformers import SwanLabCallback
import swanlab
warnings.filterwarnings("ignore")
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# ---------- 0 超参数 ----------
MODEL_PATH = "/root/autodl-tmp/model/Qwen/Qwen3-4B-Instruct-2507"
DATA_URL = "https://huggingface.co/datasets/seamew/ChnSentiCorp/resolve/main/ChnSentiCorp.jsonl"
MAX_LEN = 256
BATCH_SIZE = 4
GRAD_ACC = 4
EPOCHS = 1
LR = 2e-4
LORA_R = 64
LORA_ALPHA = 32
LORA_DROPOUT = 0.05
# ---------- 1 下载数据 ----------
data_path = "ChnSentiCorp.jsonl"
if not os.path.exists(data_path):
print("Downloading ChnSentiCorp...")
with requests.get(DATA_URL, stream=True) as r:
r.raise_for_status()
with open(data_path, "wb") as f:
for chunk in r.iter_content(chunk_size=8192):
f.write(chunk)
raw_ds = load_dataset("json", data_files=data_path, split="train").train_test_split(0.1)
# ---------- 2 加载 tokenizer & 模型 ----------
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
local_files_only=True
)
# ---------- 3 LoRA ----------
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=LORA_R,
lora_alpha=LORA_ALPHA,
lora_dropout=LORA_DROPOUT,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"]
)
model = get_peft_model(model, lora_config)
model.enable_input_require_grads()
model.print_trainable_parameters()
# ---------- 4 数据格式 ----------
def fmt(example):
prompt = f"Instruction:判断这条评论的情感倾向\nInput:{example['input']}\nOutput:"
full = prompt + example['output'] + tokenizer.eos_token
return tokenizer(full, truncation=True, max_length=MAX_LEN)
def map_ds(ds):
ds = ds.map(fmt, remove_columns=ds.column_names)
ds = ds.shuffle(seed=42)
return ds
train_ds = map_ds(raw_ds["train"])
eval_ds = map_ds(raw_ds["test"])
# ---------- 5 SwanLab ----------
swanlab.login(api_key=os.getenv("SWANLAB_API_KEY"), save=False)
swanlab_callback = SwanLabCallback(project="Qwen3-4B-lora-sentiment")
# ---------- 6 Trainer ----------
args = TrainingArguments(
output_dir="./qwen3_lora_sentiment",
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=BATCH_SIZE,
gradient_accumulation_steps=GRAD_ACC,
num_train_epochs=EPOCHS,
learning_rate=LR,
bf16=True,
logging_steps=10,
evaluation_strategy="epoch",
save_strategy="epoch",
report_to="none", # 由 swanlab 接管
load_best_model_at_end=True,
)
trainer = Trainer(
model=model,
args=args,
train_dataset=train_ds,
eval_dataset=eval_ds,
data_collator=DataCollatorForSeq2Seq(tokenizer, pad_to_multiple_of=8),
callbacks=[swanlab_callback],
)
# ---------- 7 训练 ----------
trainer.train()
# ---------- 8 快速评估 ----------
from sklearn.metrics import accuracy_score
def compute_metrics(eval_preds):
preds, labels = eval_preds
preds = preds.argmax(dim=-1)
mask = labels != -100
preds = preds[mask].cpu().numpy()
labels = labels[mask].cpu().numpy()
return {"accuracy": accuracy_score(labels, preds)}
trainer.compute_metrics = compute_metrics
print(trainer.evaluate())更多推荐
 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)