




- @weixin_44457930
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
入职新公司,主要做具身智能,因为之前对强化学习了解的比较少,所以现在开始系统性地学习强化学习。之所以要记笔记,是因为授课老师的PPT都是英文,复习的时候很难快速把知识点装回到脑袋里,只有把学到的知识用自己语言整理一遍,并记录成文档,才更方便复习。
入职新公司,主要做具身智能,因为之前对强化学习了解的比较少,所以现在开始系统性地学习强化学习。之所以要记笔记,是因为授课老师的PPT都是英文,复习的时候很难快速把知识点装回到脑袋里,只有把学到的知识用自己语言整理一遍,并记录成文档,才更方便复习。
import cv2 as cv#读取图像,支持 bmp、jpg、png、tiff 等常用格式img = cv.imread("玫瑰.jpg") # 路径得改,否则报错#创建窗口并显示图像cv.namedWindow("Image")# 给窗口命名cv.imshow("Image",img)# 将图片展示在窗口中cv.waitKey(0)#释放窗口cv.destroyAllWindows()错误信
入职新公司,主要做具身智能,因为之前对强化学习了解的比较少,所以现在开始系统性地学习强化学习。之所以要记笔记,是因为授课老师的PPT都是英文,复习的时候很难快速把知识点装回到脑袋里,只有把学到的知识用自己语言整理一遍,并记录成文档,才更方便复习。
入职新公司,主要做具身智能,因为之前对强化学习了解的比较少,所以现在开始系统性地学习强化学习。之所以要记笔记,是因为授课老师的PPT都是英文,复习的时候很难快速把知识点装回到脑袋里,只有把学到的知识用自己语言整理一遍,并记录成文档,才更方便复习。
上篇文章,我们完成了数据集的制作,得到了一个拥有近两万条样本的数据集,随后进行了模型选型,筛选出了 Qwen2.5-1.5B-Instruct 作为我们的基座模型,这篇文章,我们来完成剩下的工作,包括模型的微调与部署。
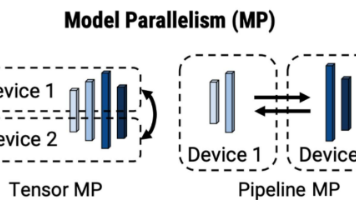
现代大模型(如GPT-3、LLaMA等)的参数量达千亿级别,单卡GPU无法存储完整模型,在训练时,除了模型参数占用显存,梯度和优化器状态同样占用显存,因此有必要使用分布式的方式进行模型的训练和推理。此外,训练大模型需要海量计算(如GPT-3需数万GPU小 时),分布式训练可加速训练过程。DeepSpeed之ZeRO系列:将显存优化进行到底特征张量并行 (Tensor Parallelism)ZeR
Agent 在早几年被翻译成代理,但这与它的实际功能并不贴切,因此这两年称呼其为 “智能体” 比较多,它是指能自主感知环境、做出决策并执行动作以达成目标的实体,通过利用大语言模型的推理能力,能够自主对复杂的人类任务进行目标规划、任务拆解、工具调用、过程迭代,并在没有人类干预的情况下完成任务。Agent 的核心在于其自主性:无需人类全程操控,能主动解决问题。LangGraph 是一个由LangCha
本项目是制作一款专注于劳动纠纷的法律助手,使用RAG技术实现。
当前(2025.5),生成模型最常用的微调手段就是LoRA微调,它是局部微调的一种,而全量微调限于数据和算力等因素,很少去使用。LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。模型种类:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等几乎
