
写文章




- @weixin_44052271
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
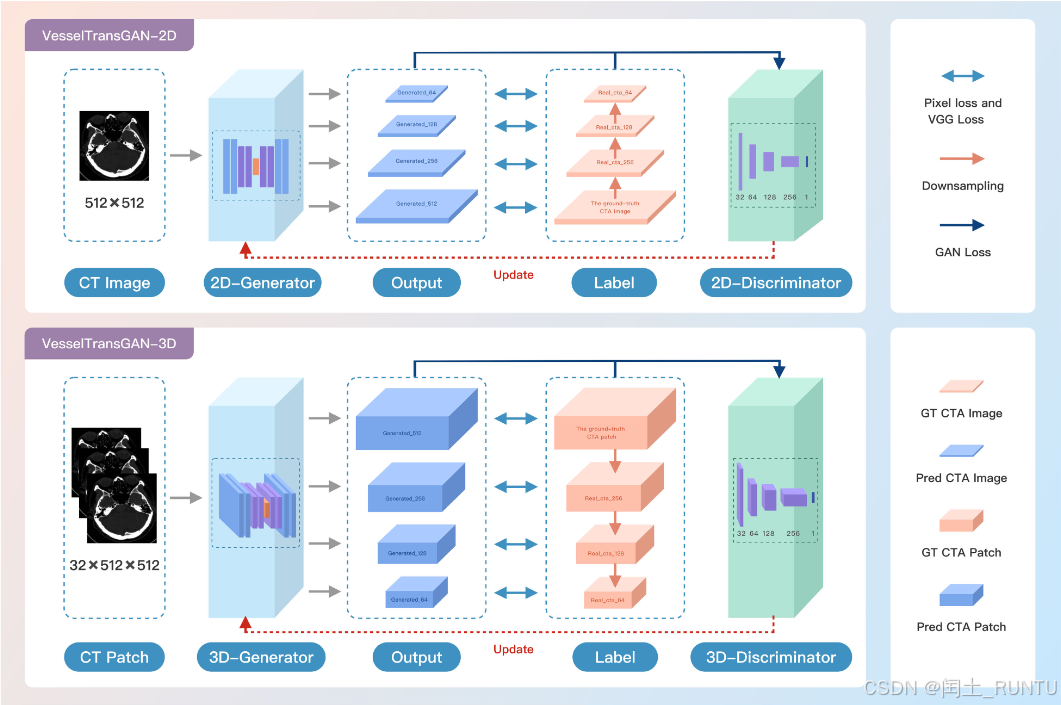
VesselTransGAN:无对比剂CTA成像方案
这同样是一个使用GAN生成CTA图像的工作。与之前分享的一篇工作不同的是,该工作聚焦于颅底小血管,理论上来说更加困难。论文发表在IEEE Access。代码地址:https://github.com/Flora-huay/VesselTranGAN。
Pycharm关于HuggingFace的accelerate库调试程序
点击创建Debug配置文件;
损失函数理解(二)——交叉熵损失
通过上面的分析,我们给出了信息量的定义。显然不是,因为如果是加和的话,实力悬殊队伍的比赛结果相对来说是确定的,大概率是实力强的队伍赢得比赛,所以它的不确定性是低的,但此时它的熵却是高的,所以熵并不是信息量的简单加和。至此,我们通过信息量和熵引出交叉熵,并介绍了交叉熵是如何用于损失计算的,希望能够对有需要的伙伴提供帮助,如果文中有歧义或者有错误的地方,欢迎大家在评论区指出!表示每个事件发生的概率,即
到底了