- @weixin_43902588
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
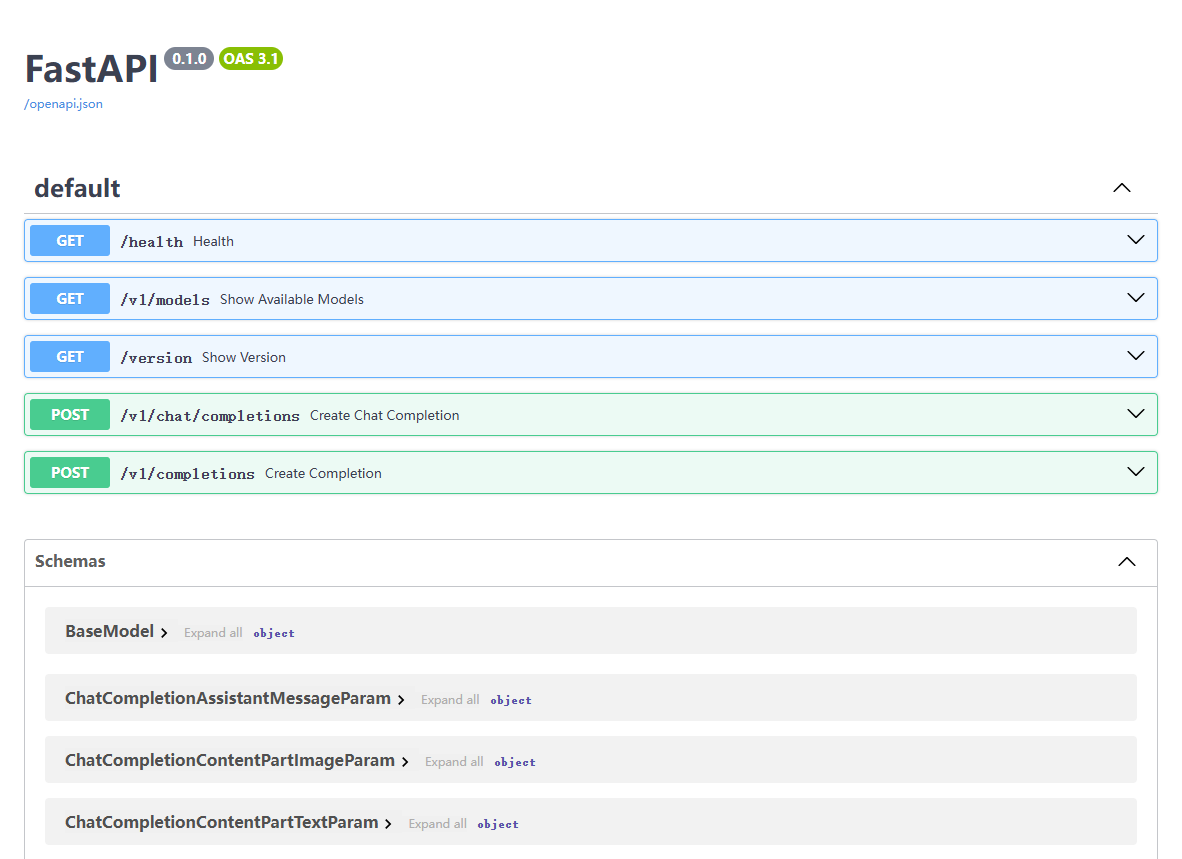
【代码】红帽 AI 推理服务(vLLM)- 运行本地的模型。

本文主要说明能够云原生备份容灾的开源项目 Velero 及其红帽扩展项目 OADP 的概念和架构篇。

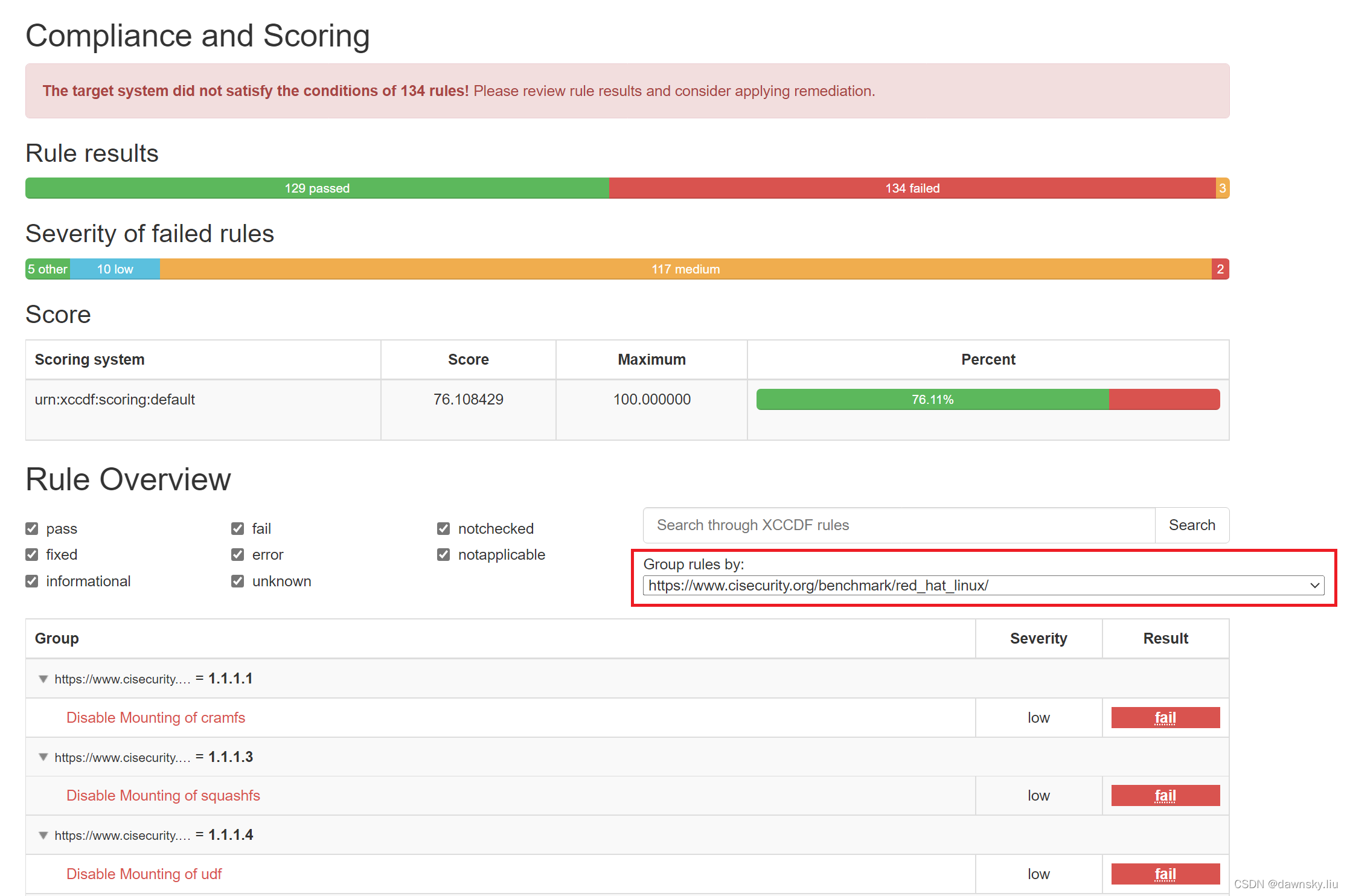
CIS(互联网安全中心)提供各种网络安全相关服务。它制作了基准以保护系统免受当今不断变化的网络威胁。这些基准以PDF的形式免费提供给CIS成员,这些内容是可读的但不能直接被扫描工具使用。CIS为付费会员提供了一些XCCDF1格式的基准,可以被工具使用。不过这些基准不包含改变服务器状态以达到合规性所需的自动化和补救步骤。为此Red Hat向用户生产“scap-security-guidelines”
《[OpenShift / RHEL / DevSecOps 汇总目录](https://blog.csdn.net/weixin_43902588/article/details/105060359)》文本已在OpenShift 4.10环境中进行验证。
说明:本文已经在支持 OpenShift Local 4.19的环境中验证。
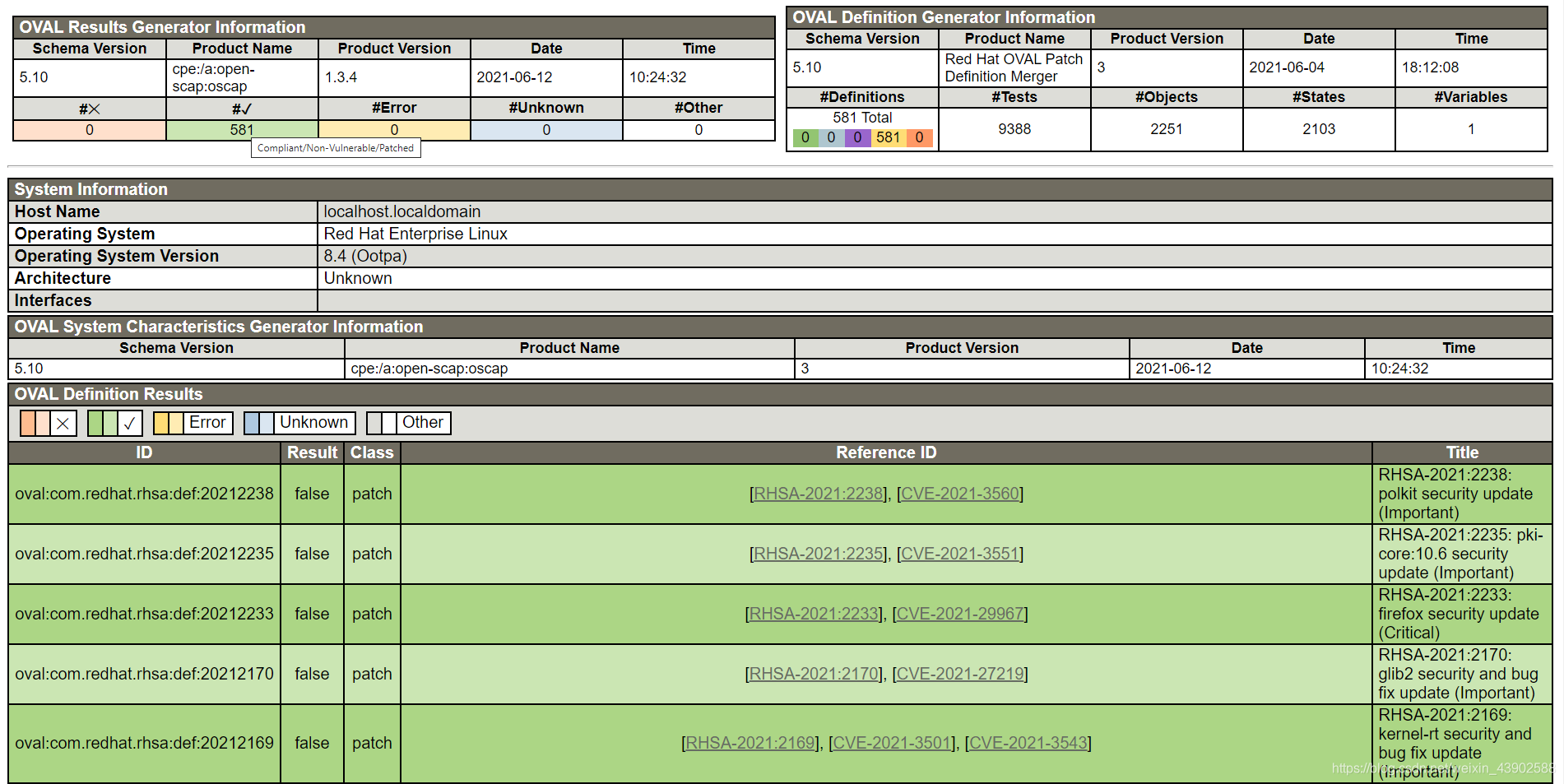
已在 RHEL 8.4 上验证本文的前置条件:RHEL8 - 配置基于安装 ISO 文件的 YUM Repo文章目录准备环境扫描容器镜像CVE漏洞下载OVAL文件扫描容器镜像查看容器镜像扫描结果扫描容器镜像合规扫描镜像符合PCI-DSS规范情况修复违规风险参考准备环境安装scap扫描工具。$ yum install -y openscap-utils scap-security-guide wge
说明:本文已经在 OpenShift 4.18 + OpenShift AI 2.19 的环境中验证。
说明:本文已经在 OpenShift 4.19 + OpenShift AI 2.21 的环境中验证。
OpenShift 4 - 为 Etcd 数据库整理碎片
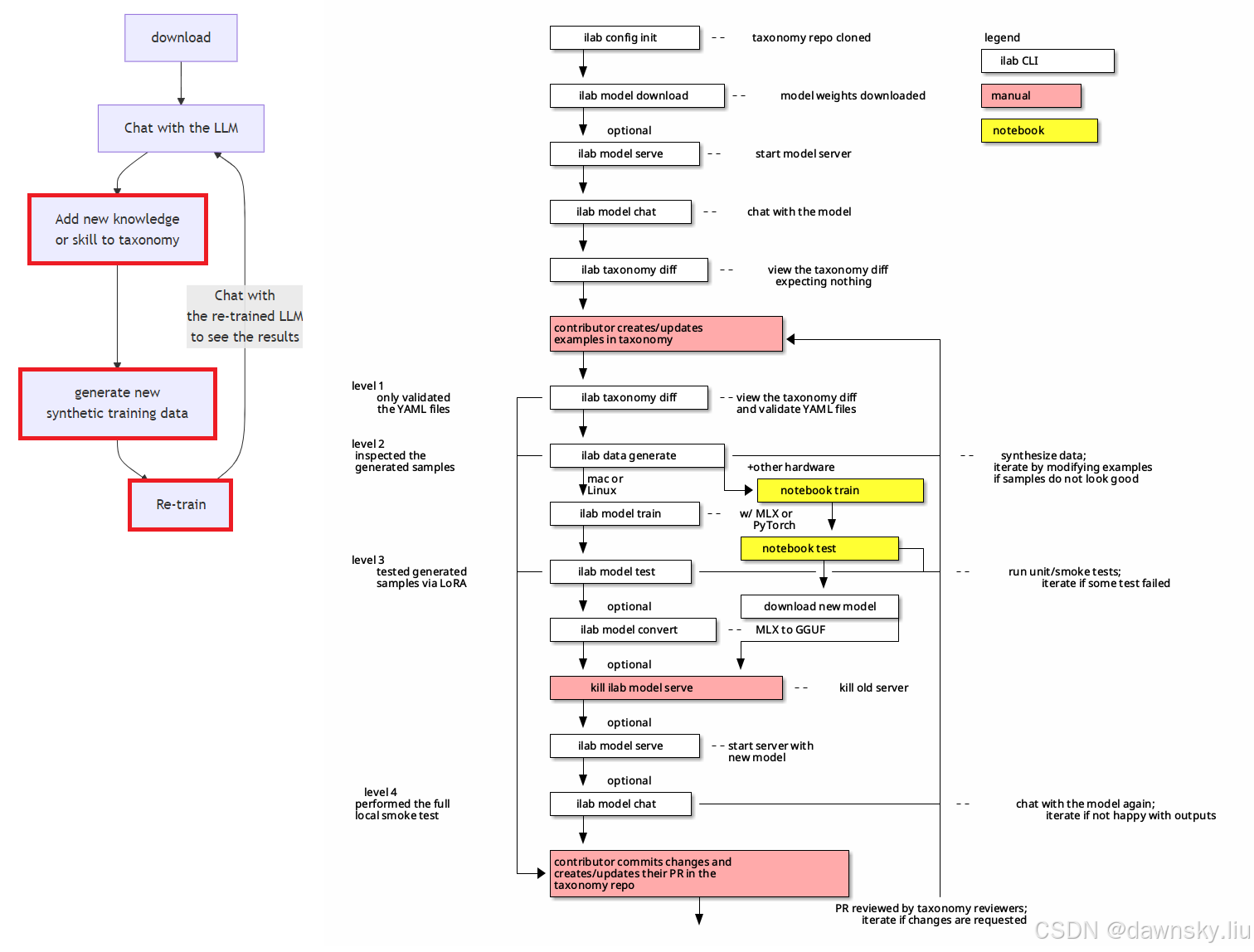
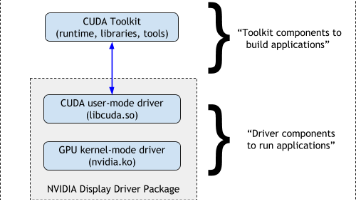
已在 InstructLab 0.24.1 验证。