
写文章




- @weixin_43284996
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
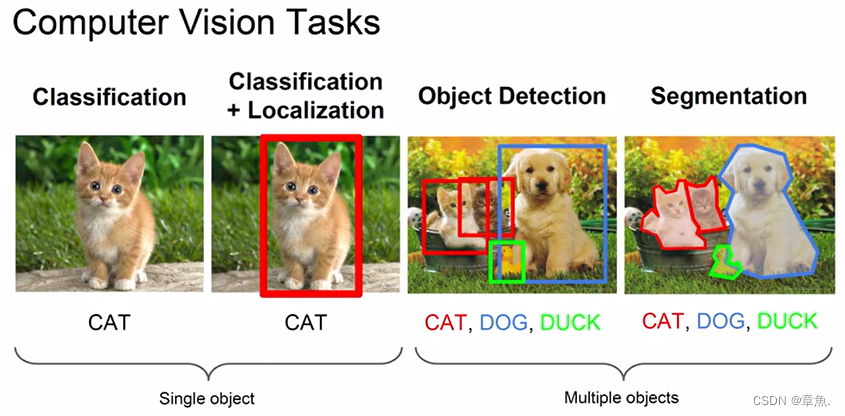
目标检测前言——YOLO
目标检测,也叫目标提取,是一种基于目标几何和统计特征的图像分割。它将目标的分割和识别合二为一,其准确性和实时性是整个系统的一项重要能力。
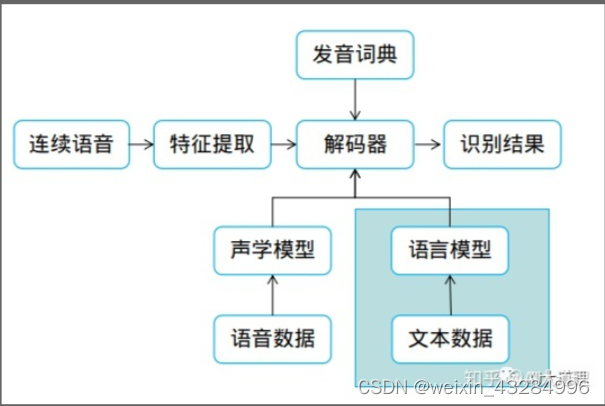
N-gram语言模型
N-Gram是大词汇连续语音识别中常用的一种语言模型。该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。
目标检测前言——YOLO
目标检测,也叫目标提取,是一种基于目标几何和统计特征的图像分割。它将目标的分割和识别合二为一,其准确性和实时性是整个系统的一项重要能力。
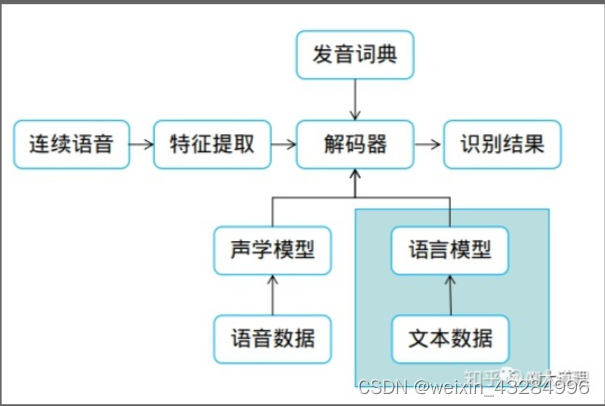
N-gram语言模型
N-Gram是大词汇连续语音识别中常用的一种语言模型。该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。
到底了