- @weixin_42608414
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
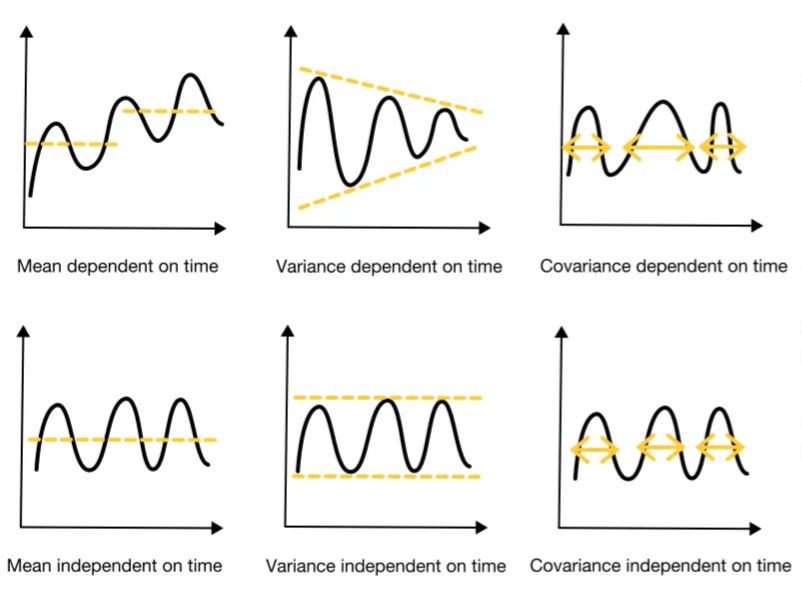
在时间序列预测中,当时间序列数据具有恒定统计特性(均值、方差和协方差)并且这些统计特性与时间无关时,则被称为数据是平稳的。由于恒定的统计特性,平稳时间序列比非平稳时间序列更容易建模。因此,许多时间序列预测模型都假设数据是平稳的。平稳性可以通过视觉评估或统计方法来检查。统计方法检查数据中是否存在单根(unit root)。两个最常用的单根检验是 ADF 和 KPSS。我们可以在Python的第三方库
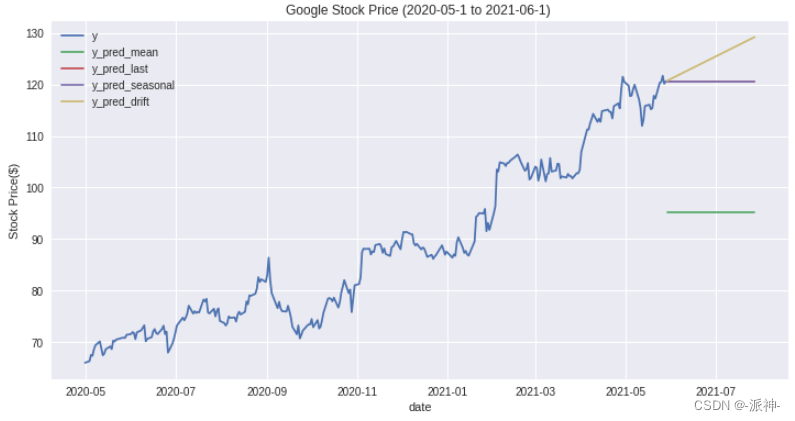
今天我们解释4种最简单的朴素预测法:均值法,最后值法,季节性最后值法,漂移法,朴素预测法虽然很简单但有时候也会有较好的预测效果,如季节性周期变化很明显的时候我们可以使用季节性最后值法,当遇到类似随机游走型的时间序列如股票数据时使用漂移法有时候也会有较好的预测效果。有兴趣的读者可以自己尝试一下使用yfinance 包来下载美国的股票数据如:特斯拉,苹果,谷歌的股票代码:tsla、aapl、goog来
Keras是目前最受欢迎的深度学习库之一,它人工智能的产品化做出了巨大贡献。 它使用简单,只需几行代码即可构建强大的神经网络。 在这篇文章中,您将了解如何使用Keras构建神经网络,通过将用户评论分类(正面和负面)来做情感分析,我们将使用著名的imdb评论数据集。我们只需要将模型进行一些改进就可以应用于其他机器学习问题。请注意,我们不会详细介绍Keras或Deep Learning。 本文旨在..
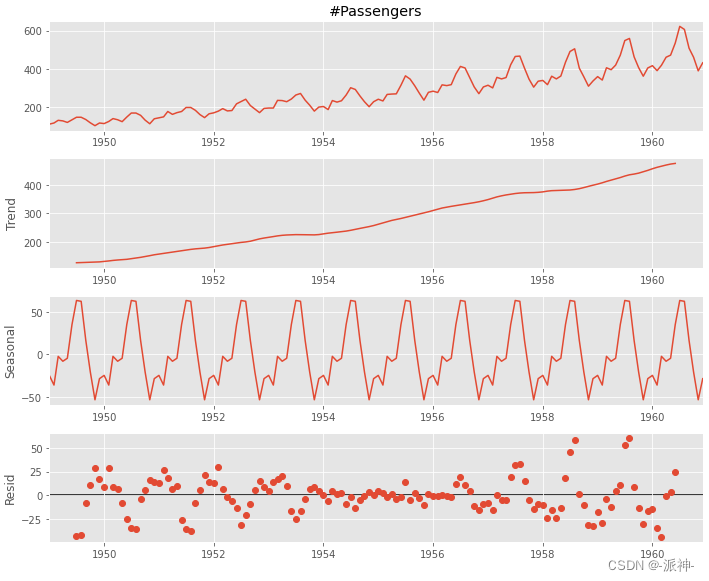
为了对时间序列数据进行准确预测必须了解时间序列数据的主要成分,如何找到数据中的主要成分,如何快速分解时间序列,本文会帮助读者了解时间序列数据预测的相关内容。
今天我们用LangChain对接了大型语言模型(LLMs), 并让LMMs可以针对性的学习用户给定的特定数据,这些数据可以是文本文件,数据库,知识库等结构化或者非结构化的数据。当用户询问的问题超出范围时,机器人不会给出任何答案,只会给出相关的提示信息显示用户的问题超出了范围,这样可以有效限制机器人自由发挥,使机器人不能让它随便乱说。

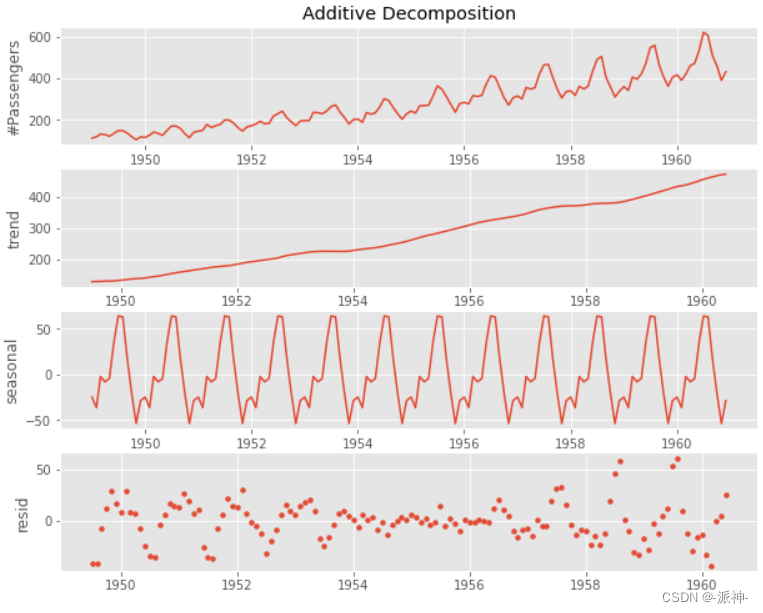
在本章中我们学习了时间序列数据的加法分解和乘法分解的基本步骤,我们一步步通过手动的方法计算了趋势、去趋势项、季节项、残差项等特征项,手动分解的目的是让读者能进一步了解各个特征项的计算逻辑,最后我们使用了statsmodels的seasonal_decompose方法来自动分解,并对比了手动分解与自动分解的结果,并确认他们是一致的。.........
本文主要介绍了指数平滑预测法的一些基本方法如简单指数平滑,趋势法、阻尼趋势法,季节性法。需要说明的是本文主要参考了并将书中原来用R语言实现的算法用Python实现了一下,在python代码中调用的指数平滑算法包主要来自于statsmodels包。通过对的学习并结合对statsmodels包的练习可以更加深刻的解指数平滑的原理。...
今天我们主要介绍了STL的分解的主要参数,和分解的过程,并观察了分解以后残差的分布和均值并确认了残差服从以0为均值的近似正太分布,这说明STL分解是正确的。其次我们还介绍了趋势程度、季节性程度以及季节性波峰的计算方法,这有助于确定数据是否具有良好的可预测性。...
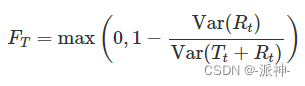
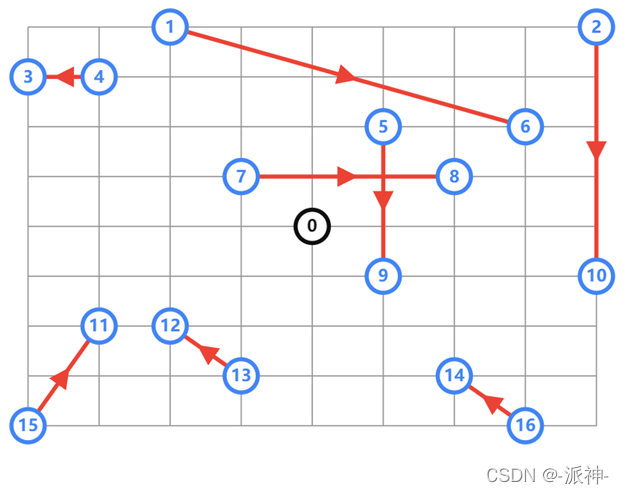
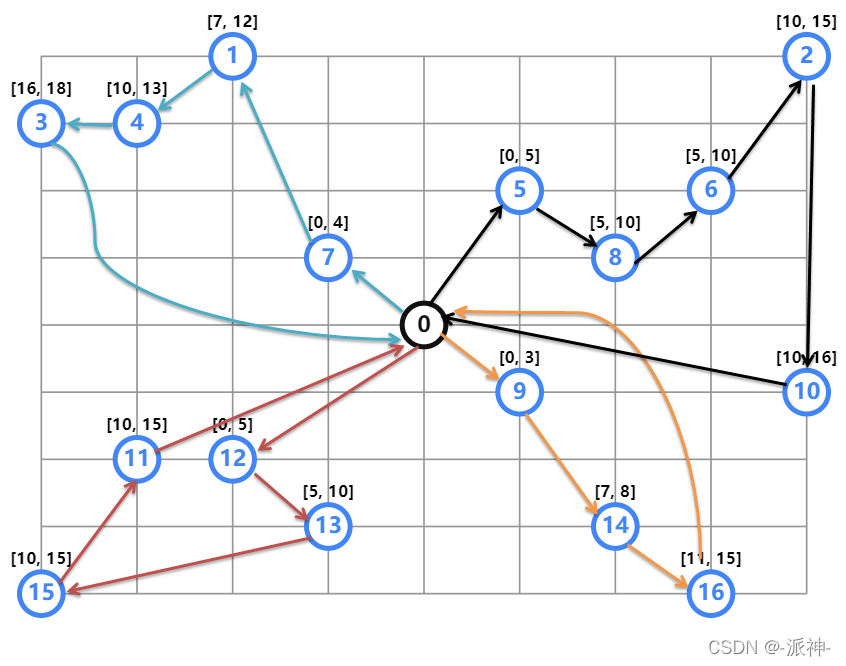
之前解释了TSP、VRP、带容量限制的VRP、取货送货VRP ,今天我们再来介绍一种带时间限制的VPR,所谓带时间限制的VRP顾名思义是指车辆需要访问的每一个地点都有一个时间创建,车辆必须在指定的时间窗口内到底指定的地点,这个时间窗口对于我们的算法来说是一个硬约束是不可用违法的。带时间限制的 VRP 示例这里的地点和之前我们介绍的CVRP案例中的地点相同,只不过我们在此基础上我们在每一个地点上方都
之前我们已经介绍了TSP、VRP、CVRP,今天我们再介绍另一种VRP的应用场景:带提货和送货的VRP,之前的CVRP是只提货不送货的场景。带取货和送货的 VRP 示例这里我们的每辆车需要在不同的地点提取货物并在其他地点交付货物。我们的要求是为车辆分配路线以提取和交付所有货物,同时最小化所有访问路线的总长度。下图显示了网格上的取货和送货地点,类似于上一个VRP 示例中的地点,这里从取货地点到交货地