




- @weixin_42092125
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
连接 Milvus 服务,初始化 BGE-M3 嵌入模型如果同名 Collection 已存在就先删掉(方便重复运行)按 Schema 创建新 Collection,同时支持稀疏和密集两种向量字段分别为两种向量字段创建索引import osos.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 国内镜像,加速模型下载# 🔧 【按你的环境修改这里
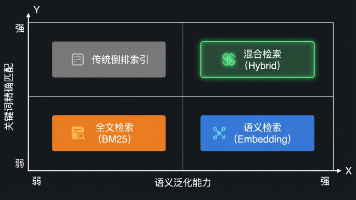
本文介绍了Milvus向量数据库的核心概念和应用场景。主要内容包括: Milvus作为生产级向量数据库的优势,相比FAISS等工具具备分布式、持久化等特性,适合高并发场景。 通过图书馆类比解释Milvus的核心架构:Collection(图书馆)、Partition(分区)、Entity(书本)的层级关系。 详细对比了四种向量索引类型(FLAT、IVF、HNSW、DiskANN)的特点和适用场景,

摘要: 本文深入解析AI知识检索的核心技术——向量数据库,解决大模型的知识冻结和上下文限制问题。通过将文本转化为高维向量坐标,实现语义相似度检索。文章对比了暴力搜索与HNSW索引的效率差异,详细介绍了FAISS、Milvus等主流工具的特性与适用场景,并提供了30行代码搭建向量检索系统的实战方案。从向量化原理到数据库选型,完整呈现AI知识检索链路,帮助开发者快速构建高效的RAG系统。

RAG,全称(检索增强生成),是目前 AI 应用领域最火热的技术范式之一。用一句话来概括它的精髓:💡RAG 就是让 LLM 学会了"开卷考试"——它既能利用训练时学到的通识知识,也能在回答时临时"翻阅"指定的外部资料。学到这里,你已经掌握了 RAG 的核心概念和基础实现。是什么:RAG = 检索(Retrieval)+ 增强(Augmented)+ 生成(Generation),通过外部知识库弥
