




- @weixin_40262196
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
2024年全球生成人工智能全景图【中文】
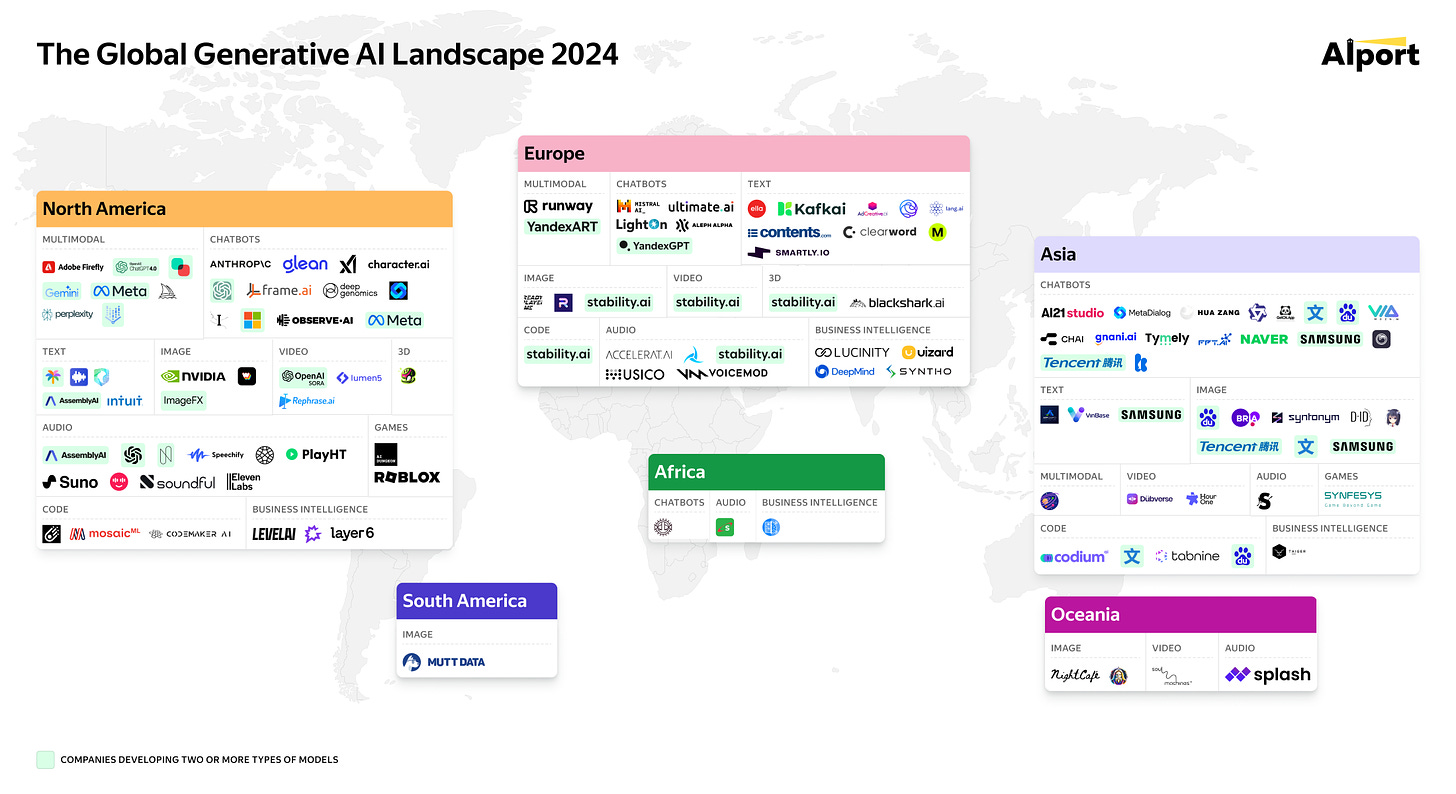
2024年全球生成人工智能全景图。如果您想要更详尽的内容可以参考。

2024-05-31。
2024年全球生成人工智能全景图。如果您想要更详尽的内容可以参考。
谷歌发布了Gemini家族的新成员Gemma 2,提供了90亿和270亿参数的两个版本,具有卓越的性能和高效的推理能力。该模型以视觉为中心,探索了多种不同的视觉编码器及其组合,并设计了一种动态且可感知空间的新型连接器,将视觉特征与LLM整合在一起。: 本研究提出了一种基于大语言模型的创新评估方法,通过分析4407家上市公司年报,构建全面的数字化转型指标,发现数字化转型显著提升公司财务表现。: Ch
为了评估其泛化性能,他们在简单的大小为 3-6 个节点的因果无关公理链上进行了训练,然后测试了泛化性能的多个不同方面,包括长度泛化性能(大小 7-15 的链)、名称泛化性能(更长的变量名)、顺序泛化性能(带有反向的边或混洗节点的链)、结构泛化性能(带有分支的图谱)。要创建训练数据集,该团队的做法是在特定的变量设置 X、Y、Z、A 下枚举所有可能的元组 {(P, H, L)}_N,其中 P 是前提,
有效的转移和无监督的深度学习医学图像分析方法TowardsNovelMethodsforEffectiveTransferLearningand UnsupervisedDeepLearningforMedicalImageAnalysis(https://biblio.ugent.be/publication/8521037/file/8521039.pdf)
2024-05-28。
本文提出CHOPINLLM,通过结合原始数据值和文本表示进行预训练和微调,提高多模态语言模型对图表的理解能力,并建立新的评估基准。: 斯坦福大学的研究致力于通过心智理论和大型语言模型,开发能够在复杂社会环境中自适应运行的自主智能体,推动多智能体强化学习的发展。: 本文研究大语言模型自解释的可靠性,发现反事实解释能生成真实、信息丰富且易验证的结果,提供传统解释方法的替代方案。: 提出了一种基于反事实
OpenAI发布了针对应用开发者的GPT-4o mini模型,取代了旧版的GPT-3.5模型。: 研究开发了一个基于游戏Baba Is You的新基准,测试了三种多模态大型语言模型,发现它们在需要操控和组合游戏规则时表现不佳。: 谷歌AI发布了一篇关于FLAMe的论文,这是一种基础大型自动评估模型,旨在为复杂多样的大型语言模型提供可靠且高效的评估方法。: 研究表明,通过Prover-Verifie