




- @walking_visitor
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
目录为什么要进行数据预处理什么是数据预处理如何进行数据预处理min-max规范化在数据挖掘概述章节中,提到了跨行业数据挖掘分析标准化流程CRISP-DW,其中有数据理解、和数据准备环节,数据预处理即是针对这两个环节的处理。为什么要进行数据预处理首先思考一下,为什么要进行数据预处理,不能直接拿来用吗?从数据挖掘命题自身出发,在确定了业务目标后,核心在于建立数据挖掘模型,不同的数据挖掘模型所需要的数据
DataFrame.corr(method='pearson',min_periods=1)参数说明:method:可选值为{‘pearson’, ‘kendall’, ‘spearman’}pearson:Pearson相关系数来衡量两个数据集合是否在一条线上面,即针对线性数据的相关系数计算,针对非线性...
数据抽样方式可分为概率抽样和非概率抽样,抽样的目的是减少数据量,以小群体样本来进行分析,得出针对全体或某一类的适用结论。抽样样本的好坏需要依据研究的具体问题而定,不同的研究问题,对抽样样本的要求会有所差异,样本的抽样方式也有所不同。概率抽样定义:采用随机的方式,在所有样本中,每个样本都有可能被采样到。这里注意随机与随便的区别,随机是没有主观意识存在的,每个样本都有一定概率被抽中,而随便抽样,则带有
数据的离散程度即衡量一组数据的分散程度如何,其衡量的标准和方式有很多,而具体选择哪一种方式则需要依据实际的数据要求进行抉择。首先针对不同的衡量方式的应用场景大体归纳如下:极差:极差为数据样本中的最大值与最小值的差值,是所有方式中最为简单的一种,它反应了数据样本的数值范围,是最基本的衡量数据离散程度的方式,受极值影响较大。如在数学考试中,一个班学生得分的极差为60,放映了学习最好的学生与学习...
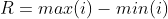
即一组数据距离数据中心的靠近程度
目录什么是数据挖掘分析数据挖掘能够干什么描述评估预测分类聚类关联数据挖掘的一般流程业务理解阶段数据理解阶段数据准备阶段建模阶段评估阶段部署阶段什么是数据挖掘分析数据挖掘是指从大量的数据中通过算法搜索隐藏于其中信息的过程---百度百科从百科的定义中,有几个关键字标签:大量数据、算法、搜索、信息对应到日常工作中,也就是:提出需要解决的问题、圈定数据范围、设计算法模型、找出解决办法数据挖掘能够干什么总得
目录为什么要进行数据预处理什么是数据预处理如何进行数据预处理min-max规范化在数据挖掘概述章节中,提到了跨行业数据挖掘分析标准化流程CRISP-DW,其中有数据理解、和数据准备环节,数据预处理即是针对这两个环节的处理。为什么要进行数据预处理首先思考一下,为什么要进行数据预处理,不能直接拿来用吗?从数据挖掘命题自身出发,在确定了业务目标后,核心在于建立数据挖掘模型,不同的数据挖掘模型所需要的数据
本指导只针对windows 平台的CPU版的TensorFlow安装,GPU版本的安装不在本文范围之内 TensorFlow安装说明:官方提供了多种安装途径,本文说明的安装方式为基于anconda平台,在线进行安装。因TensorFlow需要依赖一些库,因此强烈建议在具备上网的环境下,基于anconda进行在线安装,可以避免在入坑的道路上减少极其缺乏的自信心。本文目录:...
今天在用pandas插入oracle数据库时,提示“ORA-01438:值大于为此列允许的精度“错误,经网上查找资料后解决了此错误错误说明ORA-01438,发生此错误的原因在于我们插入的数据长度超过了字段指定的字段长度,比如插入的数据为102329204123.33829492,小数点前长度为12,小数点后长度为8,若字段字符类型指定为Number(19,12),那么在插入时则就会报错。...
数据的离散程度即衡量一组数据的分散程度如何,其衡量的标准和方式有很多,而具体选择哪一种方式则需要依据实际的数据要求进行抉择。首先针对不同的衡量方式的应用场景大体归纳如下:极差:极差为数据样本中的最大值与最小值的差值,是所有方式中最为简单的一种,它反应了数据样本的数值范围,是最基本的衡量数据离散程度的方式,受极值影响较大。如在数学考试中,一个班学生得分的极差为60,放映了学习最好的学生与学习...