




- @u013607702
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
回调(callback)是一个python中常用的技术,在langchain中回调作为一个主要模块主要应用在运行过程管理、查看日志、计算token等场景。

我们使用的聊天包装器输出的是一个AIMessage类型的消息体,而我们在组建chain链的时候,往往需要输出str或者其他格式的输出,因此这里会引入输出解析器的概念,它的作用把langchain的输出进行格式转化

1. 安装和引入openai库2. 创建OpenAi对象3. 调用openai的内置方法,输入消息和模型选择4. 没有梯子国内也可实现openai访问5. 使用免费模型的方法

1. 安装和引入openai库2. 创建OpenAi对象3. 调用openai的内置方法,输入消息和模型选择4. 没有梯子国内也可实现openai访问5. 使用免费模型的方法
数据增强是指“利用大模型以外的数据来增强应用的数据获取和提供能力”。数据增强之所以存在的一个根本原因在于——大模型自身无法包含所有数据。不管是ChatGPT或者其他大模型,他们都是预训练模型,这就意味着他们总有一个截止日期,不可能包含昨天或者今天互联网上产生的最新数据。而且在一些场景下,比如TOB业务中,企业会有自己的私有数据,甚至模型部署也是本地化的,而集成企业内部数据是一个非常重要的工作,这些

上一节课我们已经完成了数据的加载和转换,下面我们来看数据的词嵌入和存储是如何做的;我们来看一个完整的数据增强业务过程,尤其注意检索器retriever的构造和使用方法

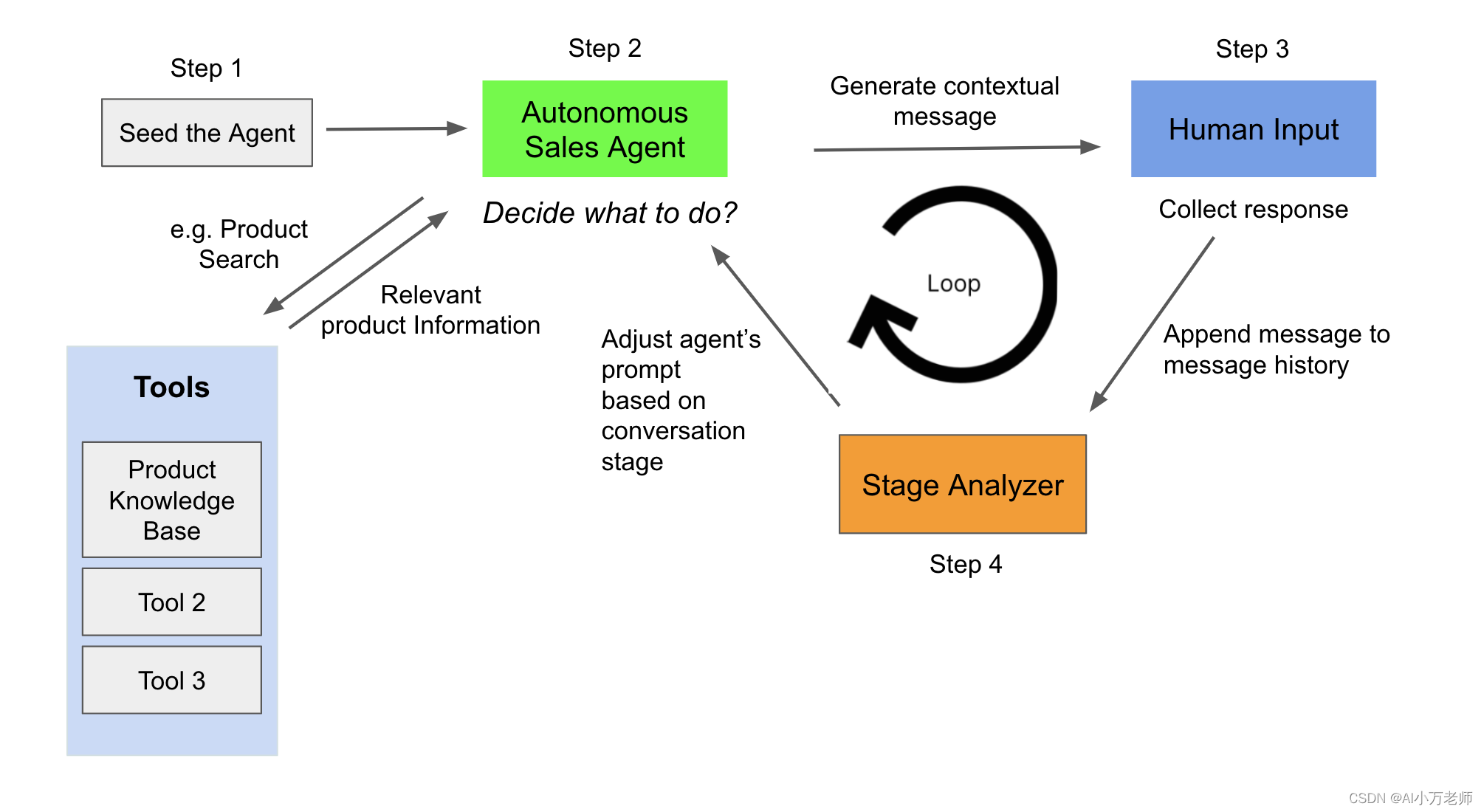
上节课,我们介绍了salesGPT项目的初步的整体结构,poetry脚手架工具和里面的run.py。在run.py这个运行文件里,引用的最主要的类就是SalesGPT类,今天我们就来看一下这个SalesGPT类,这两节课程应该是整个项目最复杂、也是最有技术含量的部分了。

上节课我们介绍了如何利用langchain去加载互联网页面内容(中文信息)、向量化和利用大语言模型进行查询,这节课我们讲一下Langchain的记忆模块。我们利用langchain构造最多的就是聊天机器人,而要进行聊天的业务功能,就必须使得大语言模型能够获得上下文,这样对话才能继续。

这个项目想做的事情并不复杂,就是利用大模型技术打造一个可以和用户交流、向用户推销产品的机器人。这个机器人把销售过程分为如下步骤,下面是这些步骤和样例内容,如下图所示:Introduction: 您好,我是来自XYZ公司的ChatGPT。我们是一家专注于提供创新解决方案的公司。Qualification: 您好,我想确认一下您是否是负责公司决策的相关人员?Value Proposition: 我们的
上节课,我们介绍了一个用streamlit和langchain打造的问答机器人,但是这个机器人有一个问题就是它只能一问一答,而且这个机器人是没有记忆的,你问他连续的问题他就傻帽了,所以,今天我们介绍一下如何打造一个类似chatGPT界面,有上下文感知、可以和你连续聊天的机器人,当然,我们也限定这个机器人只能聊旅游相关的问题。。
