




- @u012970976
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
生成式 AI 正在成为新的信息入口。过去用户通过搜索引擎、电商平台、社交媒体了解品牌,现在越来越多用户会直接向 AI 提问:某个场景下有哪些品牌值得考虑?哪个产品适合我?某个行业有哪些代表品牌?如何监测一个品牌在 AI 回答中的出现情况、推荐情况和解释情况?本文从技术视角拆解品牌 AI 心智指数的基础计算框架,重点说明提及率、推荐率、综合得分、品牌别名合并、无效回答剔除等关键环节。本文适合品牌数据
2026毕业旅行运动鞋品牌AI心智指数报告》的表面结果是:新百伦综合得分第一,耐克提及率最高,阿迪达斯位列第三,李宁、安踏进入前五,萨洛蒙、亚瑟士、Hoka One One、迈乐代表功能型品牌进入AI推荐视野。生成式AI正在成为新的信息分发层。用户不再只是搜索关键词,而是提出完整问题。AI不再只是返回网页,而是直接生成答案。品牌不再只是争夺搜索排名,而是争夺AI回答里的答案位置。这就是AI心智指数

端午将至,粽子再次成为节日消费中的主角。与日常零食不同,粽子礼盒承载的不只是口味选择,也包含节令仪式、亲友往来、企业福利、地域记忆和传统文化表达。消费者在选择粽子礼盒时,往往不只是问“哪家好吃”,还会问“送长辈选什么更稳妥”“企业端午礼盒怎么选”“南方口味和北方口味有什么区别”“老字号和新品牌哪个更适合送礼”。在生成式AI逐渐成为信息入口的背景下,这类问题也正在被越来越多用户直接抛给AI。AI在回

这次“AI年轻人生活搭子指数”的意义,不只是发现瑞幸综合第一、喜茶提及率第一,也不只是讨论哪个品牌更受AI推荐。把AI回答本身当作一个新的信息分发层来测量。过去我们测搜索排名,测内容曝光,测点击率,测转化率。品牌是否进入AI答案品牌在AI答案中处于什么位置品牌是否被明确推荐品牌被推荐的理由是否准确品牌和哪些场景绑定品牌在不同AI平台中的表现是否稳定品牌和竞品在AI回答中如何共现这就是GEO时代的品

集体通信是现代分布式人工智能培训工作(如推荐系统和自然语言处理)的一个关键性能组成部分。NCCL 具有拓扑意识,经过优化,可通过 PCIe 、 NVLink 、以太网和 InfiniBand 互连实现高带宽和低延迟。和通过自定义网络连接,在流行的云环境中实现高性能 NCCL 操作。NCCL 版本一直致力于提高集体沟通绩效。这篇文章主要关注 NCCL 2.12 版本带来的改进。
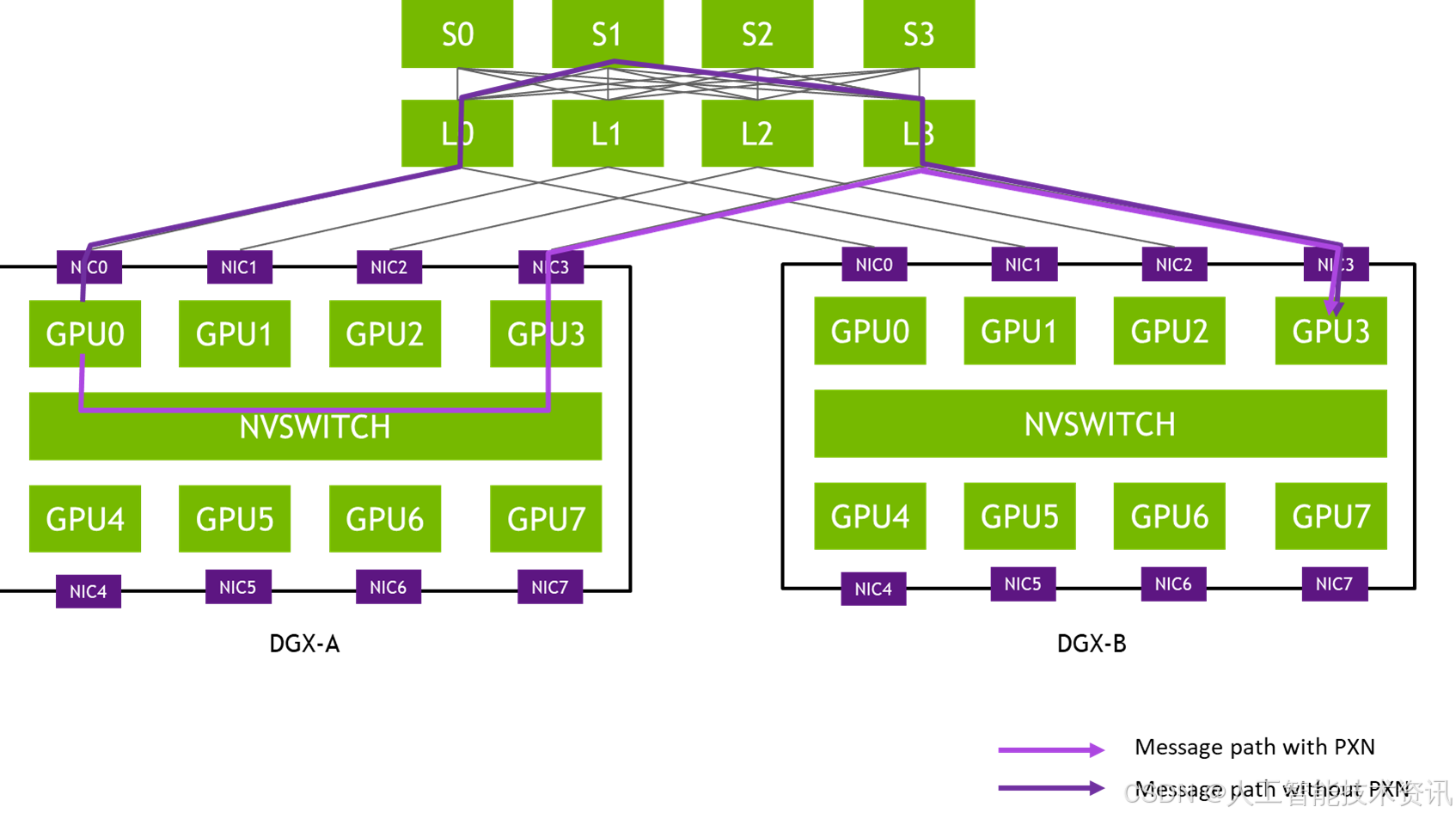
集体通信是现代分布式人工智能培训工作(如推荐系统和自然语言处理)的一个关键性能组成部分。NCCL 具有拓扑意识,经过优化,可通过 PCIe 、 NVLink 、以太网和 InfiniBand 互连实现高带宽和低延迟。和通过自定义网络连接,在流行的云环境中实现高性能 NCCL 操作。NCCL 版本一直致力于提高集体沟通绩效。这篇文章主要关注 NCCL 2.12 版本带来的改进。