




- @u012194696
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
高维数据异常检测引言在实际场景中,很多数据集都是多维度的。随着维度的增加,数据空间的大小(体积)会以指数级别增长,使数据变得稀疏,这便是维度诅咒的难题。维度诅咒不止给异常检测带来了挑战,对距离的计算,聚类都带来了难题。例如基于邻近度的方法是在所有维度使用距离函数来定义局部性,但是,在高维空间中,所有点对的距离几乎都是相等的(距离集中),这使得一些基于距离的方法失效。在高维场景下,一个常用的方法是子
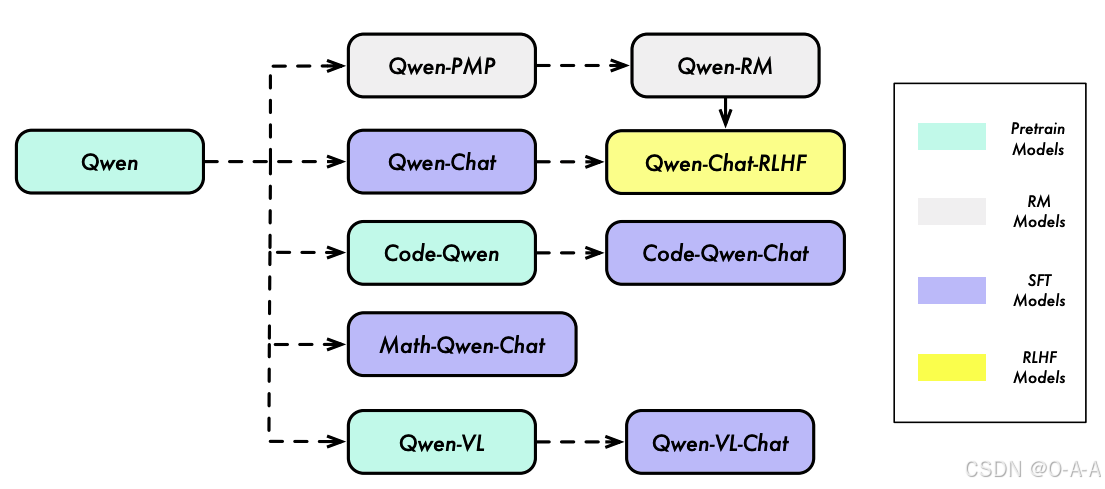
后训练数据(post-training data)的构建旨在增强模型在广泛领域的能力,包括编码、数学、逻辑推理、指令遵循和多语言理解,以及确保模型的生成结果符合人类价值观,使其有用、诚实和无害。Qwen 1 发布于 2023 年 8 月,Qwen 是一个全面的大型语言模型系列,涵盖了具有不同参数数量的不同模型,包括 Qwen 基础预训练语言模型和 Qwen-Chat,后者是通过人类对齐技术微调的聊
原文链接DeepSeek LLM 发布于 2023 年 11 月,收集了 2 万亿个词元用于预训练。在模型层面沿用了 LLaMA 的架构,将余弦退火学习率调度器替换为多步学习率调度器,在保持性能的同时便于持续训练。DeepSeek LLM 从多种来源收集了超过 100 万个实例,用于监督微调(SFT)。此外,利用直接偏好优化(DPO)来提升模型的对话性能。数据构建的主要目标是全面提升数据集的丰富性

原文链接DeepSeek LLM 发布于 2023 年 11 月,收集了 2 万亿个词元用于预训练。在模型层面沿用了 LLaMA 的架构,将余弦退火学习率调度器替换为多步学习率调度器,在保持性能的同时便于持续训练。DeepSeek LLM 从多种来源收集了超过 100 万个实例,用于监督微调(SFT)。此外,利用直接偏好优化(DPO)来提升模型的对话性能。数据构建的主要目标是全面提升数据集的丰富性
DeepSeek-V2 发布于 2024 年 5 月,为多领域专家(MoE)语言模型,包含总共 2360 亿个参数,其中每个词元激活 210 亿个参数,并支持 12.8 万个词元的上下文长度。DeepSeek-V2 采用包括多头潜在注意力(Multi-Head Latent Attention,MLA)和 DeepSeekMoE 在内的创新架构。MLA 通过将键值(KV)缓存显著压缩为一个潜在向量

DeepSeek-V3 发布于 2024 年 12 月,采用了 DeepSeek-V2 中的多头潜在注意力(MLA)和 DeepSeekMoE 架构,此外,DeepSeek-V3 开创了一种无辅助损失的负载均衡策略,并设定了多词元预测训练目标以获得更强的性能。DeepSeek-V3 总参数量达 6710 亿个,每个词元激活 370 亿个参数,DeepSeek-V3 在 14.8 万亿个多样化且高质
