




- @u011808788
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
【代码】【python】使用python脚本进行gif压缩。
要搭建自己的 Agentic AI,
底层用 MCP:先把公司里的数据库、Slack、Jira 全部变成 MCP Server,让 AI 能连得上。中间层用 Skills:编写各种 Skills(如“自动报修 Skill”、“周报生成 Skill”),把业务逻辑教给 AI。顶层用 A2A:搞一堆不同角色的 Agent(客服、运维、财务),用 A2A 协议把它们连成一个网,让它们自己开会解决问题。
学习pandas时候如果没有合适的数据集,可以用一些自带的数据集做数据分析。seaborn是个非常好用的数据分析包,其中包含了非常多的自带数据集,这些数据集存放在线上github中,用户load时自动从网络中加载,返回pandas的dataframe对象。
芯片间接口是一种功能模块,用于在同一封装内组装的两个硅芯片之间提供数据接口。芯片间接口利用极短的通道连接封装内的两个芯片,从而实现远超传统芯片间接口的功率效率和极高的带宽效率。芯片间接口通常由物理层 (PHY) 和控制器模块组成,可在两个芯片的内部互连结构之间提供无缝连接。芯片间 PHY 采用高速 SerDes 架构 或高密度并行架构实现,这些架构经过优化,可支持多种先进的 2D、2.5D 和 3

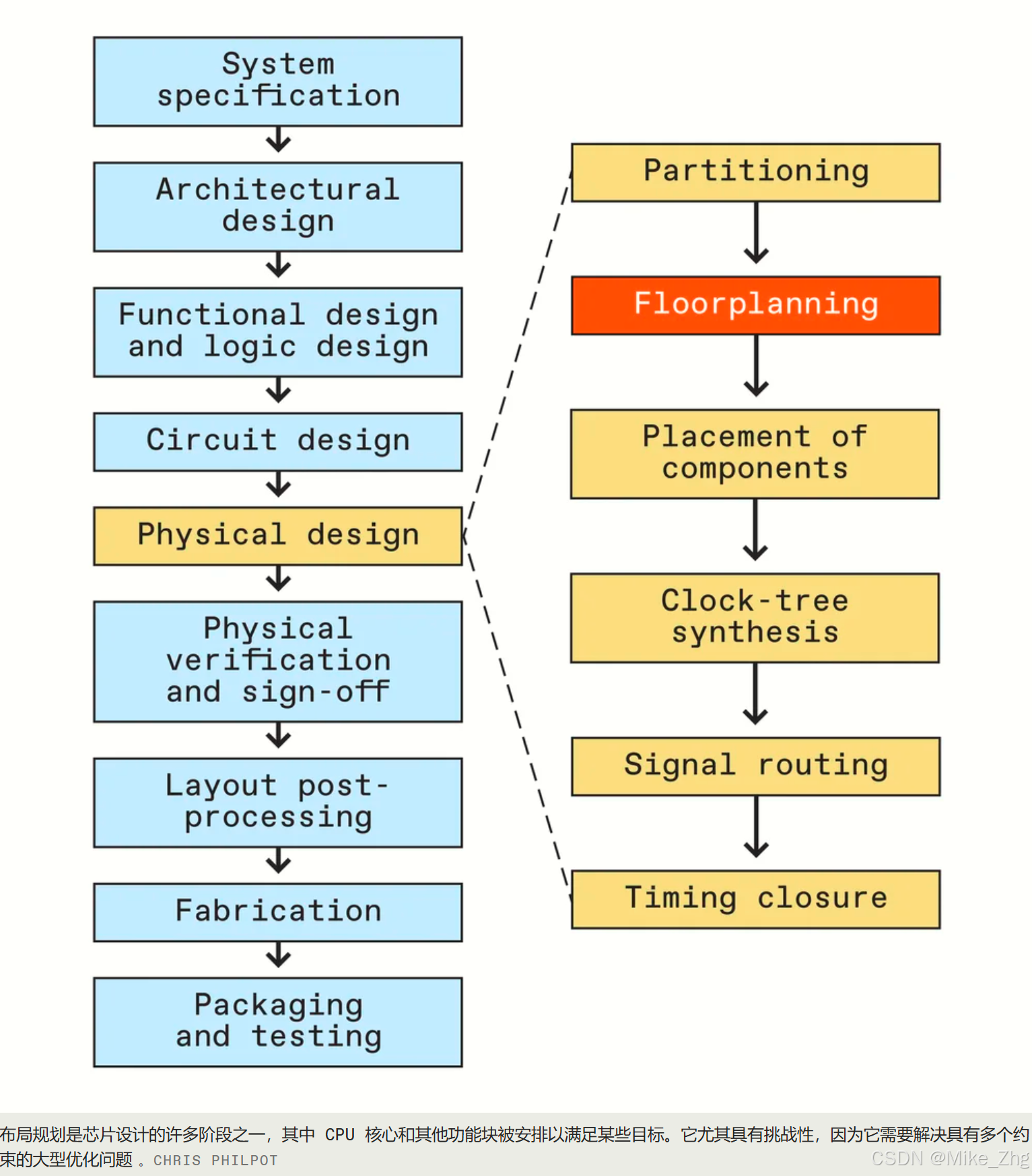
传统搜索和机器学习的结合可能是未来的发展方向自1971 年Federico Faggin仅用直尺和彩色铅笔绘制出第一款商用微处理器Intel 4004以来,芯片设计已经取得了长足的进步。如今的设计师拥有大量软件工具来规划和测试新的集成电路。但随着芯片变得越来越复杂(有些芯片包含数千亿个晶体管),设计师必须解决的问题也越来越多。而这些工具并不总是能胜任这项任务。现代芯片工程是一个由九个阶段组成的迭代
在芯片设计中,是一种非常经典且高可靠的系统级复位管理策略。这种机制的核心目的,是为了。
RAG 系统会把你的 Innovus user guide、PDK、design rule 文档切成很多 chunk,然后对每个 chunk 生成 embedding 向量,存进索引里。Qwen3 Embedding 系列是专门面向 text embedding、retrieval 和 reranking 的模型系列,并且提供 0.6B、4B、8B 等不同大小。这说明在 RAGFlow 里,emb
当然,通用 reranker 不一定真正懂 TSMC N5 rule 的专业含义,但它通常比单纯 cosine 更擅长判断 query 和 chunk 的逐词、逐条件匹配关系。典型 reranker 模型内部会让 query token 和 chunk token 互相交互。它和第一轮向量检索没有本质区别,只是使用场景变了:不是从全库 ANN 检索,而是在已有候选里重新计算向量分数。所以 rera
它不负责生成答案,也不负责给全库建索引。