




- @u010593516
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
内网无互联网环境,通过镜像文件导入docker镜像

本文介绍了如何部署Qwen3-Embedding-8B模型的详细步骤。首先确认ollama版本需0.9.0+,若版本过低会导致模型加载失败。通过卸载旧版本、下载新版ollama完成升级。其次提供两种模型获取方式:在线拉取或离线导入模型文件。完成部署后需确认模型导入成功,最后在dify平台进行模型配置。文章包含完整的命令行操作流程和注意事项,为部署Qwen3-Embedding-8B模型提供了清晰的
本文描述一个读取excel文件批量导入dify知识库QA分段的解决方案
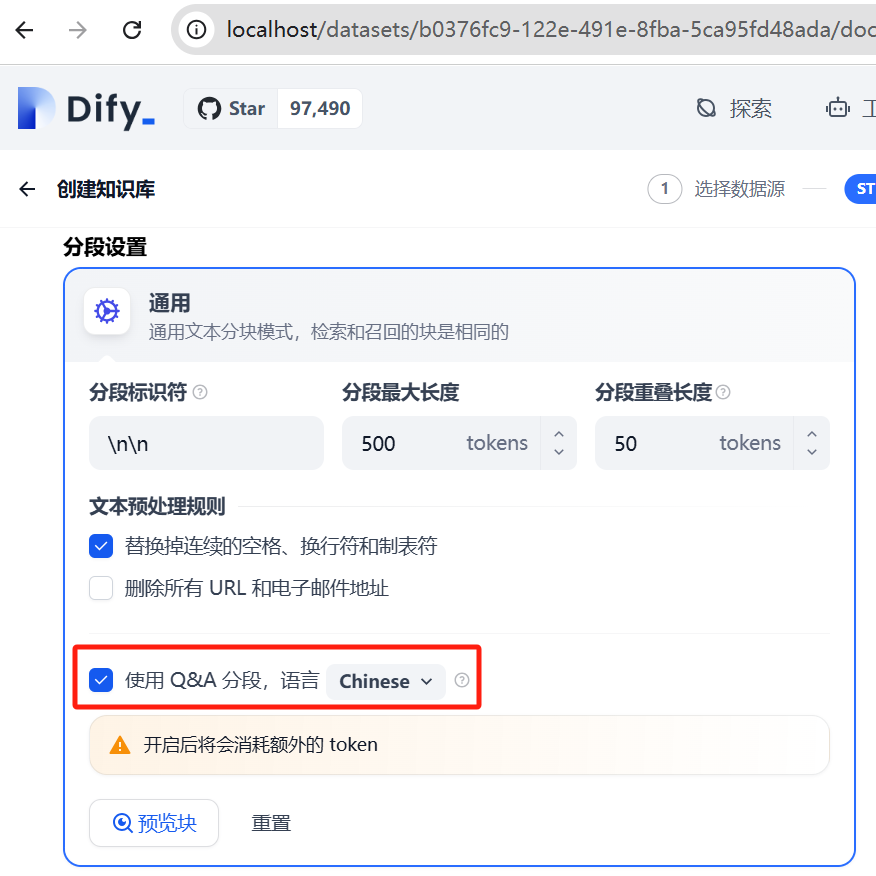
通过引入dify-import项目,支持读取高质量的txt制度类文件批量导入父子分段dify知识库并通过语言模型的推理产生相关关键字生成字段。
kylin Linux环境下,离线升级docker 镜像的命令行执行程序的方法。主要内容包括:1)在有互联网机器下载最新程序并传输到离线服务器;2)确认并启动Docker容器;3)复制编辑配置文件;4)进入容器交互模式启动虚拟环境;5)修改配置后运行程序。适用于Kylin Linux环境下的dify 0.1.0-release版本升级,新版本增加了对制度类txt文件知识库父子分段支持。
升级ollama到0.9.0后,重新加载model。原因:ollama版本过低,参考。
使用dify的workflow引入腾讯云的speech to text 大模型技术,实现mp3文件的语音转文字服务测试。

本文介绍了NL2SQL微调数据集的准备工作。重点讲解了samples.jsonl文件建立自然语言问题与数据库表的关联方法,以及通过sql_output文件夹进行向量化处理的步骤。详细说明了build_training_ds.py程序生成training_dataset.jsonl文件的格式,该文件包含正负样本标注数据,每个问题配有1个正样本和19个负样本。这些数据将用于后续的LORA微调项目处理。
本文介绍了2025年羊城工匠杯nl2sql比赛的开发环境配置方法。主要使用VSCode和DBeaver工具,其中VSCode通过SSH连接WSL的Ubuntu系统。配置步骤包括:安装Ubuntu24.04 WSL、拉取项目代码、通过pyenv管理Python版本(推荐3.10.17)、创建虚拟环境并安装依赖包(如langchain、openai等)。文章提供了详细的安装命令和配置指引,帮助参赛者快

本文介绍了NL2SQL比赛的参赛项目架构设计,包含数据准备和批量执行两大模块。数据准备阶段通过多个Python脚本实现Excel到SQL的转换、问题模板关联、向量化处理等流程,最终生成向量数据库。批量执行阶段采用多线程处理,通过查询匹配库表、构建提示词、调用大模型生成SQL等步骤,将结果写入JSON文件。整体架构包含10余个功能模块,实现了从自然语言到SQL语句的自动化转换流程。