




- @tanxiangbo
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在软件开发领域,需求管理一直是项目成功的核心关键。随着项目复杂度提升和团队规模扩大,传统依赖文档、邮件和会议的需求管理方式显露出明显短板:版本混乱、协作困难、知识难以沉淀。更值得注意的是,行业内能够真正实现需求结构化、资产化,并结合AI技术进行智能化辅助的系统并不多见。我们公司是一家垂直领域专攻企业级需求与非企业级需求管理的公司, 我们公司的大模型应用连接:http://aipoc.chtech.

本文介绍了高效提示词设计的五大核心结构模式:1. 通用公式(角色+任务+上下文+指令+约束+输出格式)提供一个系统化框架,适用于大多数场景;2. CRISPE框架(能力角色、背景洞察、任务陈述、个性风格、实验迭代)特别适合创意性工作;3. COSTAR结构(背景、目标、风格、语气、受众、响应格式)专注于沟通类任务;4. 思维链(CoT)模式通过分步推理解决复杂问题;5. 六大基本原则(清晰明确、提

文章摘要:本文系统介绍了深度学习中的张量概念及其在PyTorch和TensorFlow框架中的实现差异。首先阐述了张量作为多维数组的核心特性(形状、数据类型、设备等),并通过实例说明其在大模型中的应用场景。其次详细对比了两大框架的张量操作特性:PyTorch强调动态图和灵活调试,TensorFlow侧重生产部署和静态图优化。最后提出了大模型开发中的最佳实践建议,包括形状管理、混合精度训练和设备协调

本文介绍了软件开发中需求管理的痛点及解决方案,重点展示了NanoChat开源项目的架构与核心功能。项目采用分层设计,包含应用层、核心引擎层、数据层和基础设施层,提供完整的AI对话系统功能。文章详细解析了common.py工具文件,包括日志系统、分布式训练管理等核心功能实现。该项目体现了当前LLM开源项目的最佳实践,是学习大语言模型工作原理的优质案例。

大模型的数据集是一个多层次、多目标的复杂生态系统预训练数据是基石,决定了模型的知识广度和深度。SFT数据是教练,决定了模型的行为模式和对话能力。RLHF数据是价值观校准器,决定了模型的输出安全性和人性化程度。构建一个成功的大模型,其核心工程挑战很大程度上在于如何大规模地收集、清洗、策划和组织这些不同类型的数据,而不仅仅是设计模型架构。好的,我们将详细说明大模型训练各个阶段(预训练、有监督微调-SF

大模型的数据集是一个多层次、多目标的复杂生态系统预训练数据是基石,决定了模型的知识广度和深度。SFT数据是教练,决定了模型的行为模式和对话能力。RLHF数据是价值观校准器,决定了模型的输出安全性和人性化程度。构建一个成功的大模型,其核心工程挑战很大程度上在于如何大规模地收集、清洗、策划和组织这些不同类型的数据,而不仅仅是设计模型架构。好的,我们将详细说明大模型训练各个阶段(预训练、有监督微调-SF
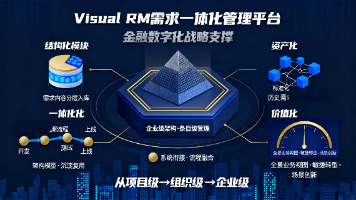
银行业数字化转型面临新核心系统搭建和需求管理效率的双重挑战。VisualRM需求数智化系统通过四大核心能力:线上化协同实现跨部门高效联动,结构化拆解降低业技偏差,资产化复用提升历史需求价值,智能化赋能加速全流程效率。该系统打通需求全生命周期管理,帮助银行缩短新核心系统搭建周期50%,提升需求复用率至40%,降低开发返工率73%。典型案例显示,某城商行应用后研发成本减少800万元,客户满意度提升至9
本文介绍了软件开发中需求管理的痛点及解决方案,重点展示了NanoChat开源项目的架构与核心功能。项目采用分层设计,包含应用层、核心引擎层、数据层和基础设施层,提供完整的AI对话系统功能。文章详细解析了common.py工具文件,包括日志系统、分布式训练管理等核心功能实现。该项目体现了当前LLM开源项目的最佳实践,是学习大语言模型工作原理的优质案例。
大模型的数据集是一个多层次、多目标的复杂生态系统预训练数据是基石,决定了模型的知识广度和深度。SFT数据是教练,决定了模型的行为模式和对话能力。RLHF数据是价值观校准器,决定了模型的输出安全性和人性化程度。构建一个成功的大模型,其核心工程挑战很大程度上在于如何大规模地收集、清洗、策划和组织这些不同类型的数据,而不仅仅是设计模型架构。好的,我们将详细说明大模型训练各个阶段(预训练、有监督微调-SF