




- @sjyttkl
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
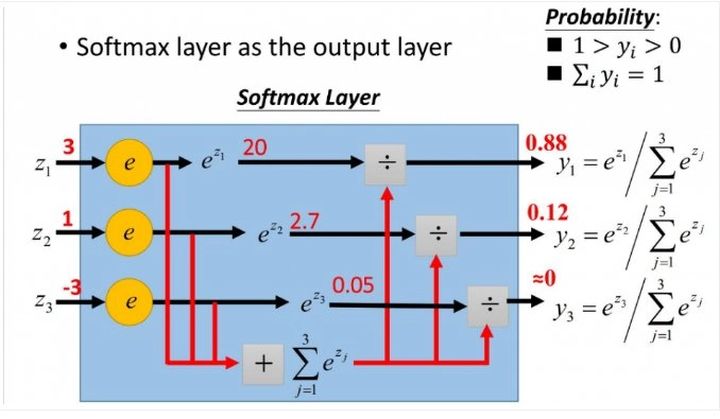
多分类任务损失函数:多分类问题一般用softmax作为神经网络的最后一层,然后计算交叉熵损失。TensorFlow中的tf.nn.softmax_cross_entropy_with_logits函数可以直接计算多分类损失。
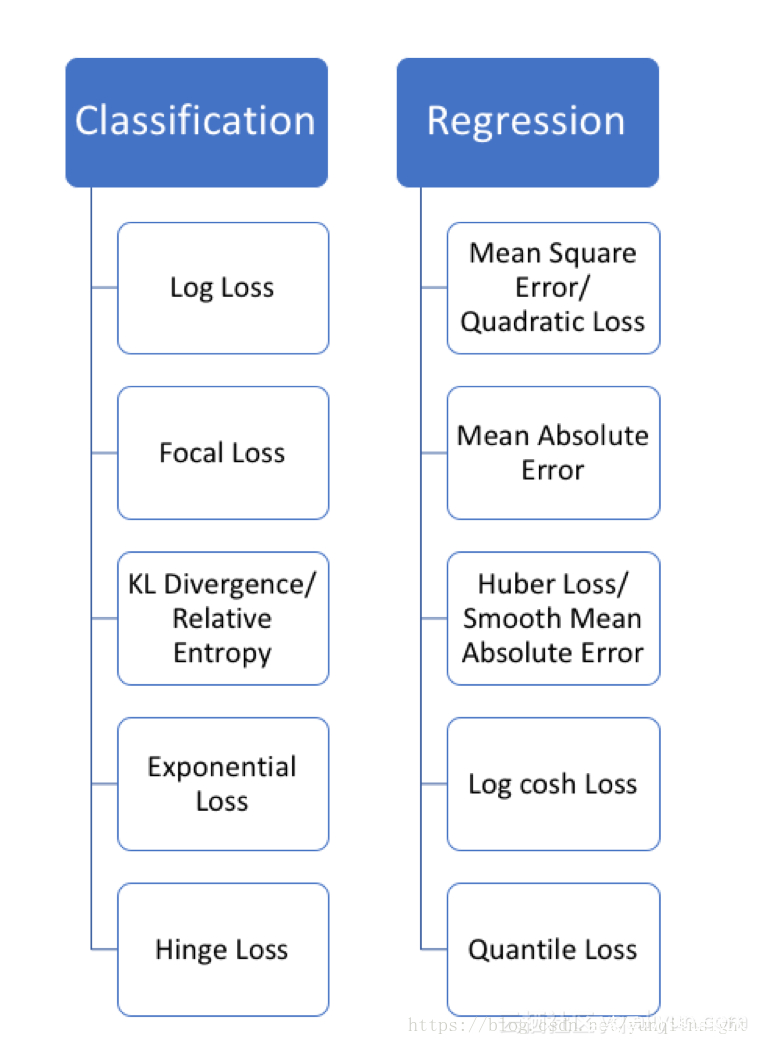
深度学习(tensorflow)中的所有学习算法都必须 有一个 最小化或最大化一个函数,称之为损失函数(loss function),或“目标函数”、“代价函数”。损失函数是衡量模型的效果评估。损失函数严格上可分为两类:分类损失和回归损失,其中分类损失根据类别数量又可分为二分类损失和多分类损失。在使用的时候需要注意的是:回归函数预测数量,分类函数预测标签。
深度学习1. 视觉计算任务有哪些,你怎么分类 ?我把任务分为像素级别、目标级别、理解级别。像素级别的任务一般是传统的图像处理任务,他们不需要用到图像的语义信息,或者最多用到底层特征(比如图像的边缘、纹理),这些任务有图像增强、传统的图像复原(如去噪、去模糊)、传统的图像分割(比如基于种子生长的方法)、图像加密等。目标级别的任务需要用到语义信息,所以提取的特征是高层特征,CNN作为...
多分类任务损失函数:多分类问题一般用softmax作为神经网络的最后一层,然后计算交叉熵损失。TensorFlow中的tf.nn.softmax_cross_entropy_with_logits函数可以直接计算多分类损失。
在很多机器学习和深度学习的应用中,我们发现用的最多的优化器是 Adam,为什么呢?下面是 TensorFlow 中的优化器https://www.tensorflow.org/api_guides/python/train在 keras 中也有 SGD,RMSprop,Adagrad,Adadelta,Adam等:https://keras.io/optimizers/我...
你肯定经历过这样的时刻,看着电脑屏幕抓着头,困惑着:「为什么我会在代码中使用这三个术语,它们有什么区别吗?」因为它们看起来实在太相似了。为了理解这些术语有什么不同,你需要了解一些关于机器学习的术语,比如梯度下降,以帮助你理解。这里简单总结梯度下降的含义...梯度下降这是一个在机器学习中用于寻找最佳结果(曲线的最小值)的迭代优化算法。梯度的含义是斜率或者斜坡的
深度学习(tensorflow)中的所有学习算法都必须 有一个 最小化或最大化一个函数,称之为损失函数(loss function),或“目标函数”、“代价函数”。损失函数是衡量模型的效果评估。损失函数严格上可分为两类:分类损失和回归损失,其中分类损失根据类别数量又可分为二分类损失和多分类损失。在使用的时候需要注意的是:回归函数预测数量,分类函数预测标签。
深度学习1. 视觉计算任务有哪些,你怎么分类 ?我把任务分为像素级别、目标级别、理解级别。像素级别的任务一般是传统的图像处理任务,他们不需要用到图像的语义信息,或者最多用到底层特征(比如图像的边缘、纹理),这些任务有图像增强、传统的图像复原(如去噪、去模糊)、传统的图像分割(比如基于种子生长的方法)、图像加密等。目标级别的任务需要用到语义信息,所以提取的特征是高层特征,CNN作为...
目录本章导读1.机器学习概率2.Spark MLlib总体设计3.数据类型3.1局部向量3.2标记点3.3局部矩阵3.4分布式矩阵4.基础统计4.1摘要统计4.2相关统计1.皮尔森相关系数2.斯皮尔森秩相关系数4.3分层抽样4.4假设校验4.5随机数生成5. 分类和回归5.1数学公式5.2线性回归1.简单线性回归2.多元线性回归5.3分类1.线性支持向量机2.逻辑回归...
深度学习(tensorflow)中的所有学习算法都必须 有一个 最小化或最大化一个函数,称之为损失函数(loss function),或“目标函数”、“代价函数”。损失函数是衡量模型的效果评估。损失函数严格上可分为两类:分类损失和回归损失,其中分类损失根据类别数量又可分为二分类损失和多分类损失。在使用的时候需要注意的是:回归函数预测数量,分类函数预测标签。