




- @shenxiaoming77
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
首先解释下“有统计学意义”和“显著差异” 两个概念:”有统计学意义"和"差异显著"是两个不同的概念,"差异显著"易给人一种误导,原来两概念在统计学中经常有点通用,现在明确地只能用“有统计学意义”。P<0.05是指假设H0(即两总体没区别)成立的可能性概率在5%以下,a就是允许犯Ⅰ类错误(拒绝了正确的无效假设H0)的概率,一般在做假设检

VectorIndexer主要作用:提高决策树或随机森林等ML方法的分类效果。VectorIndexer是对数据集特征向量中的类别(离散值)特征(index categorical features categorical features )进行编号。它能够自动判断那些特征是离散值型的特征,并对他们进行编号,具体做法是通过设置一个maxCategories,特征向量中某一个特征不

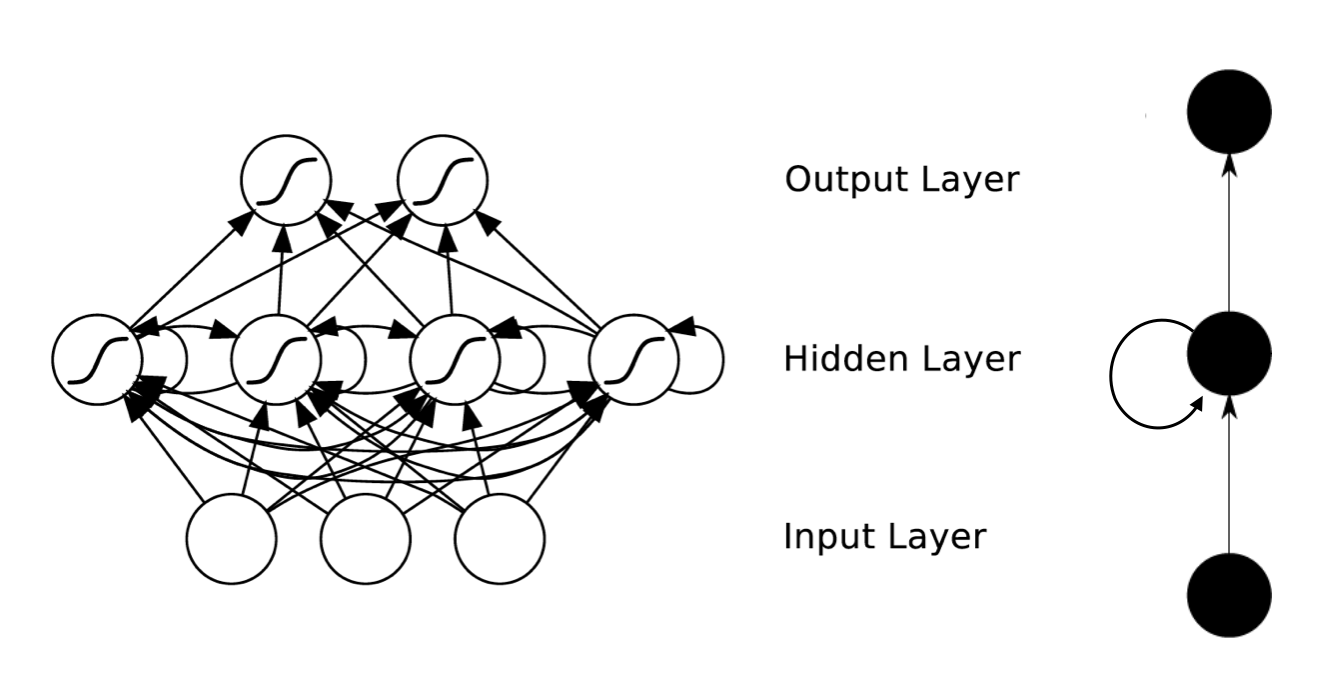
首先来看下RNN的一个循环网络结构图:RNN(Recurrent Neural Network)在时间维度上,我们将RNN进行展开,以便能够更好地来观察:主要的参数就是三部分:在RNN中每一个时间步骤用到的参数都是一样的,要理解清楚的是:一般来说,每一时间的输入和输出是不一样的,比如对于序列数据就是将序列项依次传入,每个序列项再对应不同的输出(比如下一个
昨天下午接到的一个需求,需要对线上的hadoop集群做一个改动,切换最重要的namenode节点, 将namenode服务转移到另一台服务器上,由于namenode节点下保存了所有的hbase元数据信息等等,万一操作不当, 导致大量数据丢失,责任可不小。这里整理下上午切换过程中的一些操作和碰见的问题。
能量函数(energy function)一开始在热力学中被定义,用于描述系统的能量值,当能量值达到最小时系统达到稳定状态。在神经网络(Neural Network)中,在RBM中被首次使用。在RBM中,输入层v和隐藏层h之间的能量函数定义为:E(v,h)=∑i∈vaivi+∑j∈hbjhj+∑i∈v,j∈hvihjwij将a,v,b,h和w向量表示成矩阵,这个式子可以

能量函数(energy function)一开始在热力学中被定义,用于描述系统的能量值,当能量值达到最小时系统达到稳定状态。在神经网络(Neural Network)中,在RBM中被首次使用。在RBM中,输入层v和隐藏层h之间的能量函数定义为:E(v,h)=∑i∈vaivi+∑j∈hbjhj+∑i∈v,j∈hvihjwij将a,v,b,h和w向量表示成矩阵,这个式子可以
在别的地方看到了一篇有关总结模型评估的文章,感觉讲解还是挺有点内容的,转载过来 学习学习 分享下模型评估的方法一般情况来说,F1评分或者R平方(R-Squared value)等数值评分可以告诉我们训练的机器学习模型的好坏。也有其它许多度量方式来评估拟合模型。你应该猜出来,我将提出使用可视化的方法结合数值评分来更直观的评判机器学习模型。接下来的几个部分将分享
一、在适合用途上的比较。ItemCF是利用物品间的相似性来推荐的,所以假如用户的数量远远超过物品的数量,那么可以考虑使用ItemCF,比如购物网站,因其物品的数据相对稳定,因此计算物品的相似度时不但计算量较小,而且不必频繁更新;UserCF更适合做新闻、博客或者微内容的推荐系统,因为其内容更新频率非常高,特别是在社交网络中,UserCF是一个更好的选择,可以增加用户对推荐解释的信服程度。

P是“拒绝原假设时犯错误概率”又或者说是“如果你拒绝掉原假设实际上是在冤枉好人的概率”。不管怎么表达理解上都有点绕,所以你还是看例子吧。比如你做一个假设( null hypothesis):你的女性朋友平均身高2米,输入你统计的样本数据后,计算机给你返回的p值是0.03。这意味着如果你拒绝“女性朋友平均身高2米”这个结论,犯错的概率是0.03,小于0.05(人们一般认为拒绝一句话时犯错概率小于0.
Bad Rate:坏样本率,指的是将特征进行分箱之后,每个bin下的样本所统计得到的坏样本率bad rate 单调性与不同的特征场景:在评分卡模型中,对于比较严格的评分模型,会要求连续性变量和有序性的变量在经过分箱后需要保证bad rate的单调性。1. 连续性变量:在严格的评分卡模型中,对于连续型变量就需要满足分箱后 所有的bin的 bad ...
