- @shayuchaor
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在数据构建方面,研究者提出自适应数据集构建方法(Self-adaptive Dataset)和双重增强框架(SED-Aug),有效提升模型性能;在Agent领域,开源工具包SRWToolkit和世界模型植入框架(WorMI)推动了交互式智能体的发展;行业应用中,DeepMedix-R1和ChexGen等医学模型展现出临床应用潜力;文生图技术方面,Plot'n Polish和TaleDiffusio
VGGSounder、RSVLM-QA等数据集通过重新标注或自动生成方式提升音频-视觉、遥感VQA等任务评估质量。训练策略方面,OTReg优化语音文本对齐,CATP减少视觉token冗余,EDiT改进扩散模型效率。行业应用中,ODYSSEY框架实现四足机器人长时程任务规划,GPT-5在医学推理表现突出,MuaLLM辅助电路设计。这些工作通过数据增强和算法创新推动多模态大模型在复杂场景的应用。
在数据合成方面,提出了自动生成2D/3D/4D数据的Follow-Your-Instruction框架和面向低资源语言的MELLA数据集;训练策略创新包括Shuffle-R1强化学习框架、VFlowOpt剪枝技术和MulCoT-RD蒸馏模型;行业应用涵盖医疗(MoMA临床预测、CT-GRAPH报告生成)、化学(Chemist Eye实验室监控)等领域。

Nova框架实现单GPU实时服务Agentic视觉语言模型,VC-Agent则加速定制视频数据集收集。Meta-Memory通过LLM增强机器人空间推理能力。模型预训练方面,SciReasoner培养科学推理能力,Sigma优化手语理解。数据方面,TABLET提供大规模视觉表格数据集,ArchGPT构建建筑领域专业数据集。行业应用中,语义通信框架减少交通监控数据传输,Decipher-MR提升3D
在数据方面,GeneVA数据集系统标注文生视频伪影,AdsQA构建广告视频理解基准,VR语音转录增强提升共指消解性能;模型应用上,FinZero实现金融时序预测,VLM成功用于中微子检测和皮肤病诊断,CLAPS实现视网膜图像统一分割;生成技术中,RewardDance创新奖励机制提升视觉生成质量,HuMo框架实现多模态人体视频生成。

PediatricsMQA基准揭示LLM在儿科问答中的年龄偏见问题;HPSv3提出宽光谱人类偏好评估框架提升文生图质量;医疗领域应用如RenalCLIP模型显著提升肾癌诊断和预后能力;MV-RAG通过检索增强方法改进文本到3D生成;MoDER模块化框架增强VLM的增量学习能力。这些研究在模态偏见消除、医疗AI应用、生成模型优化等方面取得突破,为AI技术的公平性、专业性和创造性发展提供了新思路。
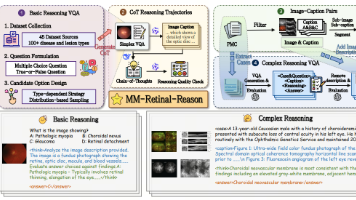
训练数据方面,SCAR框架提出多模态数据集评价指标,多个团队发布了孟加拉语、韩语等低资源数据集及儿科问答基准。智能体研究关注强化学习优化和人机协作,如SWIRL框架和InquireMobile系统。训练策略上,提出轻量级知识整合框架NLKI和自奖励视觉推理方法Vision-SR1。行业应用涵盖机器人控制、电商分类、医疗预测等领域,如Long-VLA机器人模型和动脉瘤预测网络MCMeshGAN。
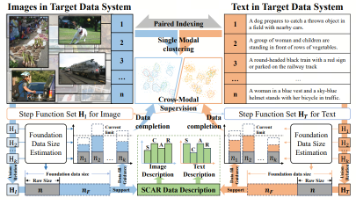
在数据集方面,Visual-TableQA和EgoGazeVQA分别针对表格图像推理和注视引导视频问答提出新基准;在智能体领域,Mini-o3、TA-VLA等研究探索了视觉搜索、力矩感知和视频推理的新方法;行业应用方面,医疗、教育等领域涌现出数据高效微调、联邦学习等创新方案;文生图/视频技术结合神经隐式表示实现矢量动画。此外,HiPhO物理竞赛基准、TextlessRAG无文本问答框架等突破性工作

EDITS框架通过文本语义增强数据集蒸馏;CLAW利用视觉-语言-动作框架提升机器人抓取精度;PhysicalAgent整合扩散模型实现机器人操作。医疗领域探索LLM在VR培训中的应用,临床任务中结合文本与时间序列数据。新基准如Cinéaste评估电影理解能力,PairTally测试细粒度视觉计数。底层架构方面,DVU通过门控残差tokenization提升视频处理效率。
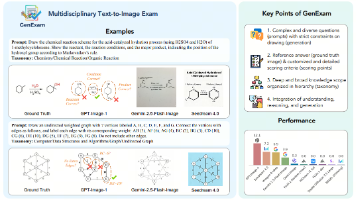
在医学领域,多个团队发布了胸部CT分割数据集ReXGroundingCT、基于不确定性的医学预训练模型,以及评估模型压缩技术对医学LLAVA模型影响的研究。在自动驾驶领域,SafeDriveRAG框架通过知识图谱提升安全性,构建了22.8万交通安全问答对。