- @rekaf66
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
工作流是 LLM 非常重要的概念,它可以帮助 LLM 更高效地完成工作,同时帮助 LLM 去拆解问题复杂度,达到化繁为简的效果。希望这篇文章可以帮助你更深地理解工作流。
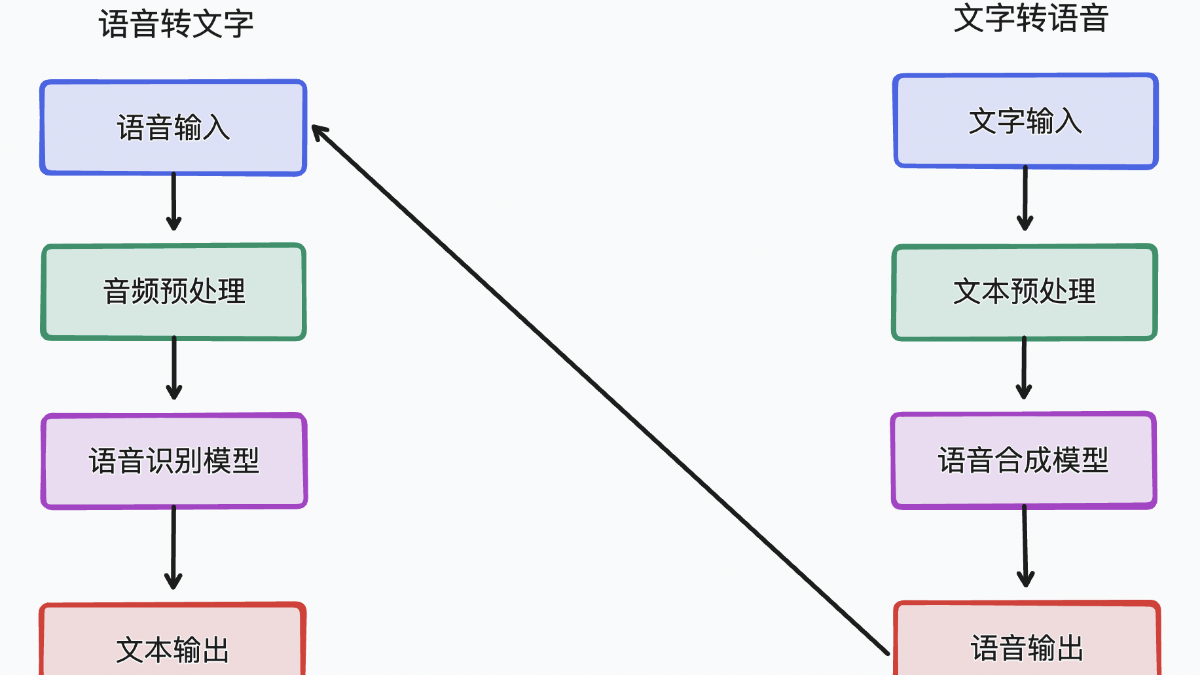
我们展示了如何使用阿里百炼的语音合成和语音识别技术,实现文本转语音和语音转文本的完整流程,并讲述如何针对自己的业务构建专属转文本模型。我们获取到比较精确的转出的文字再去做别的处理,可以极大帮助我们的实际业务。
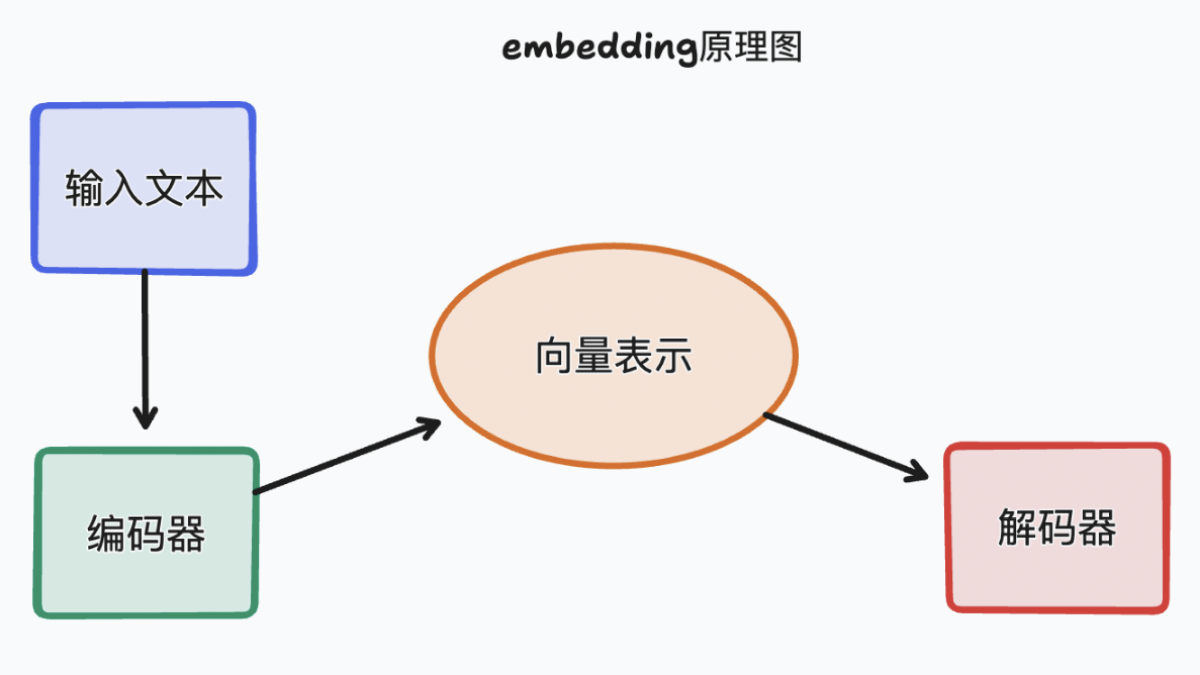
Embedding是一种将高维数据映射到低维空间的技术。在NLP中,Embedding通常用于将单词、句子或文档转换为连续的向量表示。这些向量不仅保留了原始数据的关键信息,还能够在低维空间中捕捉到语义上的相似性。简单来说,就是机器无法直接识别人类的语言,所以需要通过Embedding去转化成机器能够理解和处理的数值形式。比如:"猫"和"狗"由于都是动物,所以它们的Embedding向量在空间上比较
COT思维链的出现,为AI的发展开辟了一条新的道路。它让AI学会了像人类一样思考,将复杂问题分解成简单的步骤,并逐步推理出最终答案。希望我的引导会对你产生启发。

混合检索技术通过结合关键词检索和语义检索的优势,实现了多路召回,从而提高了检索的准确性和全面性。掌握上面我们提到的混合检索,不仅你可以根据自己的实际情况去对多种检索方式的权重进行加权,还可以根据自己的实际情况去调整对应的召回策略,对我们自建RAG检索有着极大帮助,希望本文能对你有启示。

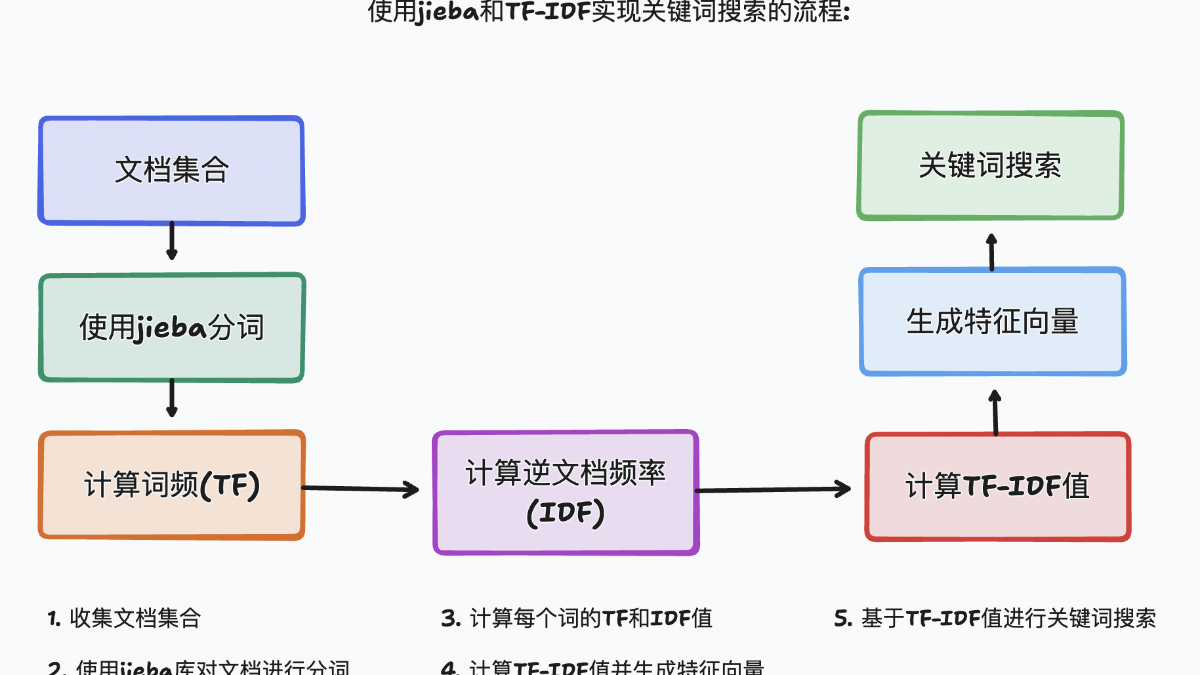
jieba(结巴)是一个在Python中广泛使用的分词库,特别适用于中文文本处理。jieba库不仅支持基本的分词功能,还提供了关键词提取、词性标注、命名实体识别等多种功能。在关键词检测领域,jieba库的TF-IDF和TextRank算法被广泛应用于提取文本中的关键词。TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索和文本挖掘的常