- @redemptiv
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
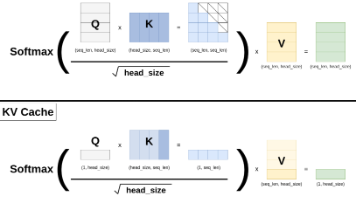
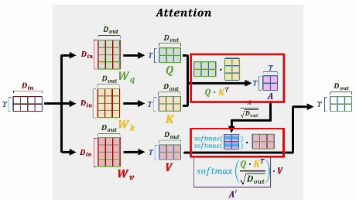
这种极端的压缩方案带来了立竿见影的工程收益,KV Cache 的体积被骤减了数十倍,从根本上释放了显存带宽的压力,让推理速度得到了极大的提升。这种设计的核心优势在于它赋予了模型极强的特征表达能力,因为每一个 Query 头都能在一个完整且独立的 Key 和 Value 特征子空间中进行信息提取,从而充分捕捉极高维度的复杂语义特征。在生成新词时,当前的 Query(Q)只代表最新生成的那个词,它要去
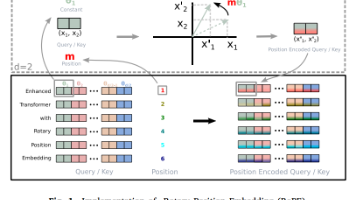
(3)原生支持长度外推:既然它是通过“旋转频率”来控制位置的,那么当我们想让模型处理比训练时更长的文本时,只需要像 YaRN 算法那样,稍微修改一下旋转频率(把转速拨慢一点),就能无缝支持 32K 甚至 1M 的超长文本,而不需要重新从头训练模型。对于注意力机制来说,句子 [A, B, C] 和 [C, B, A] 的计算结果是完全一样的,因为它只是在算词与词之间的相似度,完全没有“语序”的概念。
假设网络最终输出的标量损失函数为。
剥开纷繁复杂的公式,Transformer 的本质其实极其纯粹:它提供了一种极其优雅的数学拓扑结构。它从不“理解”语言,它只是用极度自由又被精心约束的矩阵空间,承载了语言的无限可能。我们惊叹于大模型的智能涌现,但在这背后,不过是冰冷的梯度下降在浩瀚的参数海中,顺理成章走到的那个最优解。
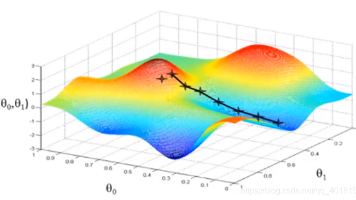
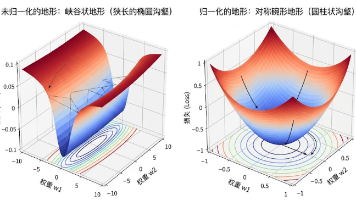
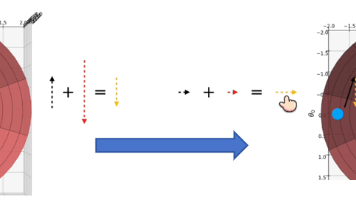
在人工智能和深度学习领域,优化器(Optimizer)是驱动神经网络不断学习和收敛的核心引擎。它的核心任务是通过更新网络的参数 θ\thetaθ,来最小化目标函数(Loss Function)J(θ)J(\theta)J(θ)。理解优化器的演进过程,本质上是理解数学上如何更高效、更稳定地在复杂的高维空间中寻找全局最优解(或足够好的局部最优解)。在整个梯度下降过程 θnew=θold−η⋅∇θJ(θ
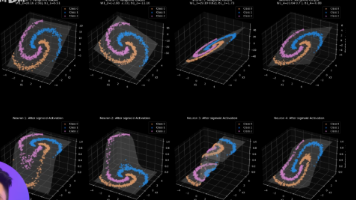
在深度学习领域,神经网络常被比作模拟人类大脑的复杂系统。然而,其核心能力的来源并非仅仅在于“神经元”的叠加,而在于隐藏在每个神经元之后的激活函数。激活函数是神经网络能够处理现实世界复杂任务的根本。它不仅是实现万能近似能力的关键钥匙,更是调控模型训练动态平衡(避免梯度消失或爆炸)的核心开关。
从计算机视觉(CV)跨界到大模型方向,是我近期科研路径上的一个重要转折。但方向的转换往往伴随着阵痛,底层逻辑的差异让我在初期的推进中遇到了明显的瓶颈。与其在知识断层中挣扎,不如退回原点,重新打牢根基。这段时间,我开始了对人工智能底层知识的“重修”计划。这篇博客将作为我的学习备忘录,沉淀我转向大模型以来的最新知识总结与核心体悟。这既是一次对现有瓶颈的突围,也是为了后续研究的厚积薄发。前向传播没有任何