




- @qq_46035581
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
早期训练一个大模型只需要预训练和监督微调就行,比如GPT2,这个时候的大模型效果并不好,在市场上并没有犯起大浪花,但是在GPT-3之后,随着InstructGPT和ChatGPT的发布而被广泛引入和应用的强化学习,大模型才开始爆火,所以有必要了解强化学习的概念。
这里设置识别类型,这个项目默认就行。
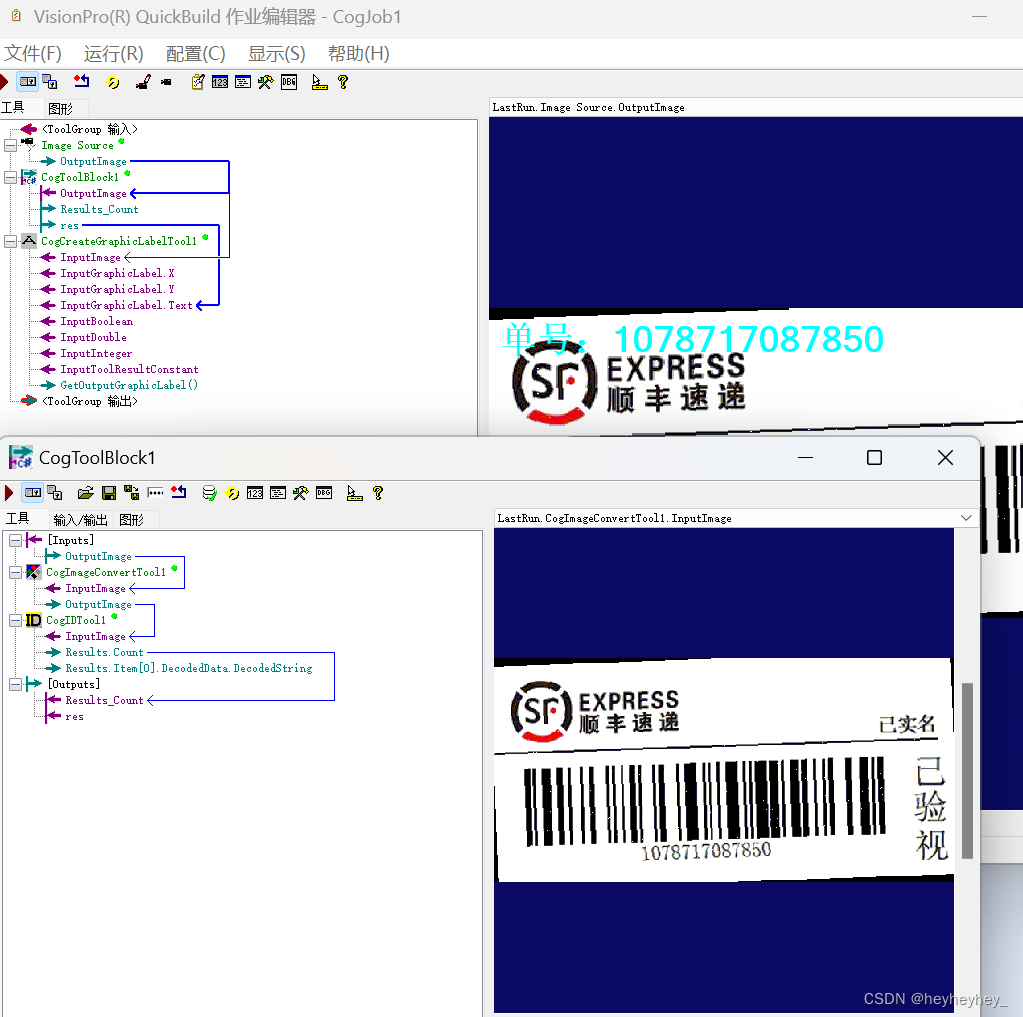
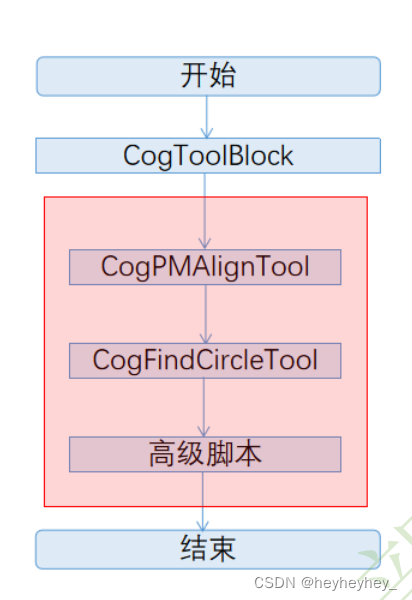
本案例是用PMA的中心传给找圆工具作为圆形,然后在圆心里设置参数找出圆的,下面两张图是配置参数的细节,通过卡尺数量,投影长度,对比度阈值、边缘模式等设置,在调试时可以开启实时模式进行调试,最后勾上最佳拟合圆。
早期训练一个大模型只需要预训练和监督微调就行,比如GPT2,这个时候的大模型效果并不好,在市场上并没有犯起大浪花,但是在GPT-3之后,随着InstructGPT和ChatGPT的发布而被广泛引入和应用的强化学习,大模型才开始爆火,所以有必要了解强化学习的概念。
网上资料很详细,但是也过于详细了,我简单说下显存占用的原理和公式。
跟着楼兰老师学习。
用@tool定义描述,函数内需要按照格式写参数信息,简述功能# 定义⼯具 注意要添加注释# @tool(description="写一本某种风格的小说")@tool(description="写一本某种风格的小说")"""写一本某种风格的小说Args:Style: 小说的风格"""return "我正在写" + Style + "风格的小说"
摘要: 本文介绍了如何在PyTorch中实现单机多卡并行训练,包括数据并行和模型并行的具体实现方法。数据并行通过nn.DataParallel将数据分批到不同GPU,解决大数据量问题;模型并行则手动分配网络层到不同GPU,解决大模型参数问题。文章以MNIST数据集和CNN模型为例,详细说明了代码实现要点:1) 设置环境变量选择GPU;2) 确保数据和模型在同一设备;3) 模型并行需指定各层设备及数
网上资料很详细,但是也过于详细了,我简单说下显存占用的原理和公式。
分词最开始的方法是BPE,但存在生僻字在词表中不存在的问题,后续都采用BBPE方法,这种方法对UTF-8的编码进行字节划分,UTF-8是包含了世界的语言,所以能够涵盖所有字体。这部分自行查找相关资料。分词密度 = 字数/token数词表越大,token密度越大,上下文长度越长,运行效率越慢。