- @qq_45975143
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
接下来使用弱智吧的数据集微调我自己的模型,首先得给它做个配置:找到data目录里面有一个,然后我们就模仿人家配数据的方式,把我们自己的数据给它配进去:我们把identity东西我们拷贝一份儿。拷贝一份儿,然后给它粘过来找到弱智吧数据路径,给它把填到file_name里面进入到根目录,启动在启动页面我们就可以看到刚才的数据集了。Llama factory支持增加多套数据同时做训练。比如说可以选两个数
本系列文章详细介绍。
魔塔(ModelScope)是由阿里巴巴达摩院推出的开源模型即服务(MaaS)共享平台,汇聚了计算机视觉、自然语言处理、语音等多领域的数千个预训练AI模型。其核心理念是"开源、开放、共创",通过提供丰富的工具链和社区生态,降低AI开发门槛,尤其为企业本地私有化部署提供了一条高效路径。ModelScope。
模型压缩()是一种通过减少机器学习模型的复杂度、存储占用或计算资源消耗,同时尽量保持其性能的技术,模型压缩算法能够有效降低参数冗余,从而减少存储占用、通信带宽和计算复杂度,有助于深度学习的应用部署。其核心目标是在资源受限的设备(如移动设备、边缘计算设备)上高效部署模型,或加速模型推理/训练过程。人脸识别、人脸特效的模型集成在手机端,如何将高度依赖硬件的模型部署在算力低的移动端:核心就是模型压缩。模
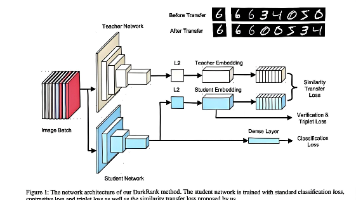
接下来使用弱智吧的数据集微调我自己的模型,首先得给它做个配置:找到data目录里面有一个,然后我们就模仿人家配数据的方式,把我们自己的数据给它配进去:我们把identity东西我们拷贝一份儿。拷贝一份儿,然后给它粘过来找到弱智吧数据路径,给它把填到file_name里面进入到根目录,启动在启动页面我们就可以看到刚才的数据集了。Llama factory支持增加多套数据同时做训练。比如说可以选两个数
我们在训练模型的时候,批次越大,模型训练的越快、效果越好,但是如果模型的参数固定是16位的情况下,微调批次batch一般不会设置很大。为了加速模型训练,可以用8位或者4位来替代训练过程中16位的运算,当我们把16位降到8位或者降到4位的时候,显存占用就降低了,批次就可以调整更大,模型训练起来就会更快。这种训练方式并没有改变模型的参数数量,只是降低了模型的计算精度而已。GGUF格式的全名为(),是由
Qwen-Agent是一个开发框架。充分利用基于通义千问模型(Qwen)的指令遵循、工具使用、规划、记忆能力。Qwen-AgentDashScope服务提供的Qwen模型服务支持通过OpenAI API方式接入开源的Qwen模型服务RAGAs。
特性全量微调参数高效微调(PEFT)局部微调更新参数范围全部参数新增的少量参数部分原始参数资源消耗非常高极低中等存储开销整个模型副本很小(仅需保存增量参数)整个模型副本灾难性遗忘风险高风险极低风险中等性能潜力可能最高通常接近全量微调取决于解冻层数易用性简单直接需要选择/配置方法(如LoRA)需要选择解冻层现代建议:对于大语言模型的微调,参数高效微调(PEFT),尤其是LoRA及其变体,已经成为事实
微软开源了一个分布式训练deepspeed框架,目前来讲,主流微调工具支持的分布式训练框架都是基于deepseed来实现的,这个框架的特点就是它支持千亿级参数模型的训练,基本上可以适配目前英伟达下面的主流显卡。deepspeed框架的核心目标是降低大模型训练成本,提升显存和计算效率。它其实基于PyTorch这个框架来构建的,支持库。[{# 单轮对话},# 多轮对话},}]单轮对话转换代码如下:#
我们提出了一个大型清洁汉语会话语料库(LCCCLCCC-base和LCCC-large。为了保证语料库的质量,设计了严格的数据清洗流水线。该管道涉及一组规则和几个基于分类器的过滤器。诸如攻击性或敏感词、特殊符号、表情符号、语法错误的句子和不连贯的对话等噪音都会被过滤掉。LCCC数据集包含large和base版本,large版本数据很大,基于base数据集选择1000到3000条数据作为样本的输入话