- @qq_43475750
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
使用 vscode 的时候偶然触发 bug:使用快捷键选中多行代码进行批量注释或解注释之后,vscode 程序直接闪退。

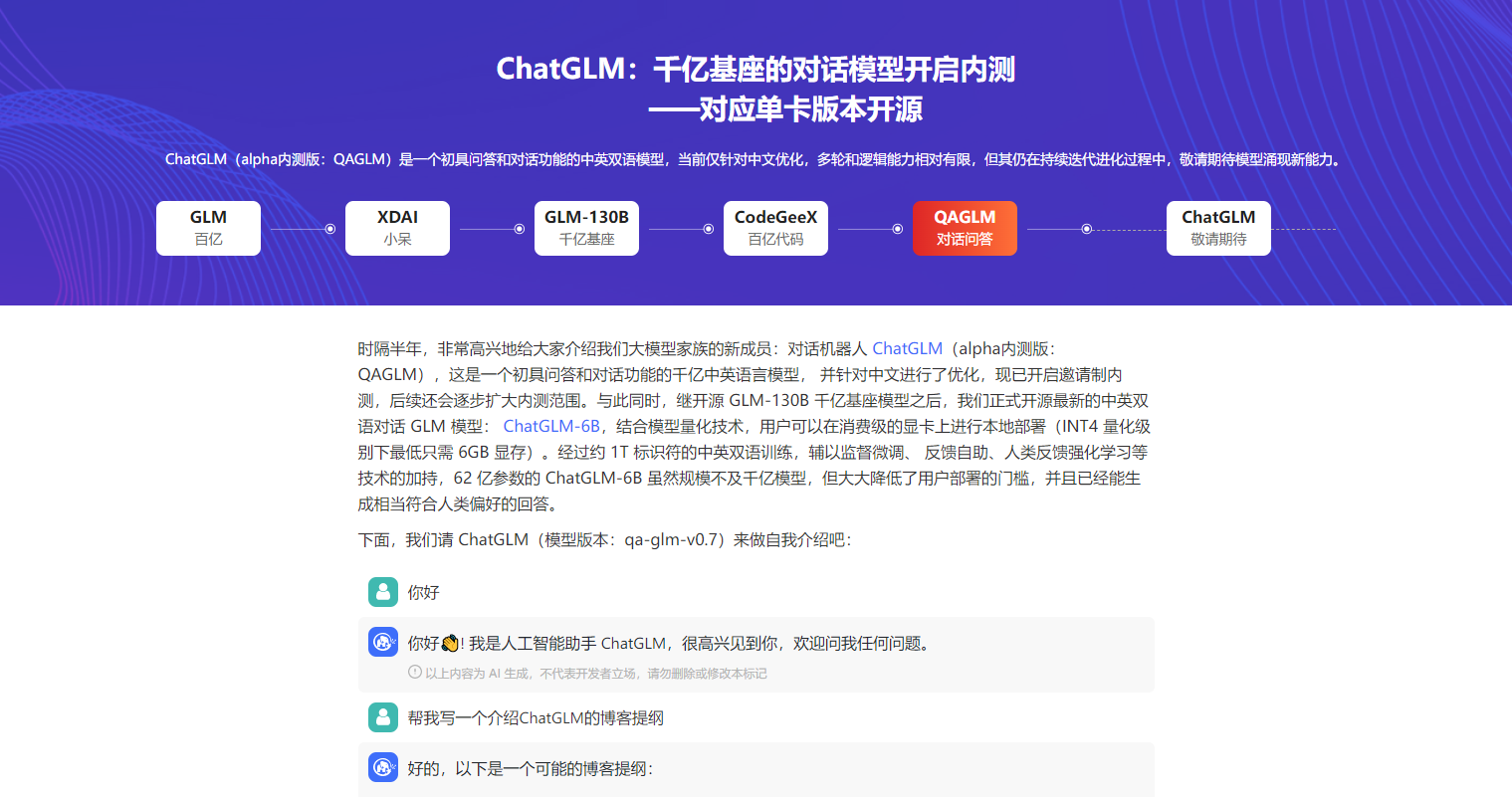
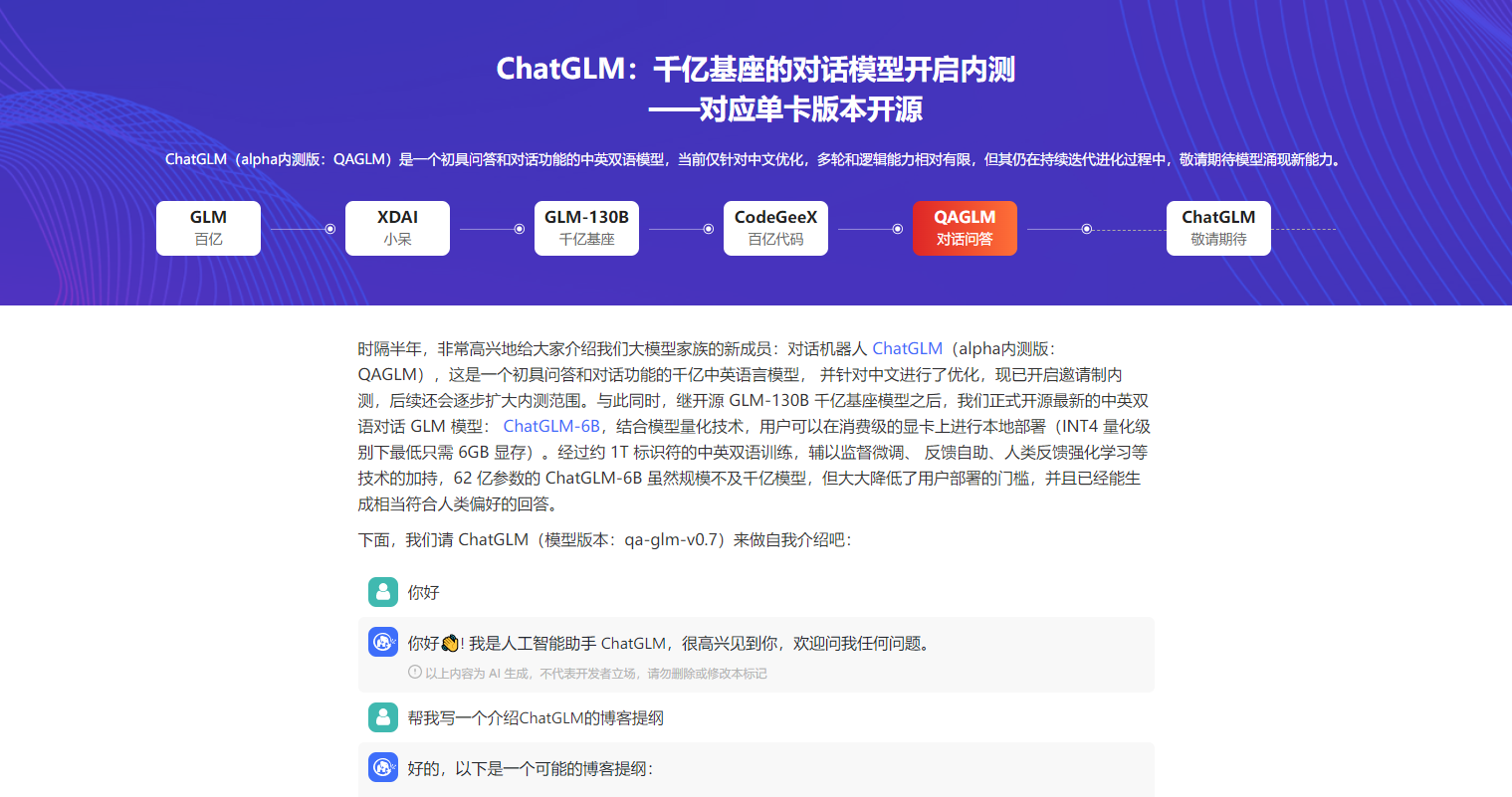
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反
这是初识SDR的SDR#(SRDSharp)篇SDRSharp的安装首先,先下载SDRSharp相关文件夹。这时,面对一堆文件不知所措的同学们来说,可以尝试把每个文件都打开试试。这里建议 .bat 为后缀的文件,需要多次打开确认安装相关文件成功,如果长时间没有安装进度更新,请耐心等待。安装成功后的文件夹列表如图(参考而已,可能存在差异):其中,名为 “tmp”的文件夹就是其打开bat后...
本文主要是记录一下自己过滤分类信息的一个步骤。主要目的是从爬取的素材中得到一个集中、有效的、有关网络暴力的中文词库。主要思路是将已分词的素材 source.txt通过 word2vec 训练出一个模型 vectors.bin,再把人工挑选的种子库 feed.txt 中的种子输入模型,得到相似的词,最后获得词库。目录文本预处理准备语料构建种子库Word2vec模拟Linux环境(Cygwin)wor
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反