




- @qq_43309286
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
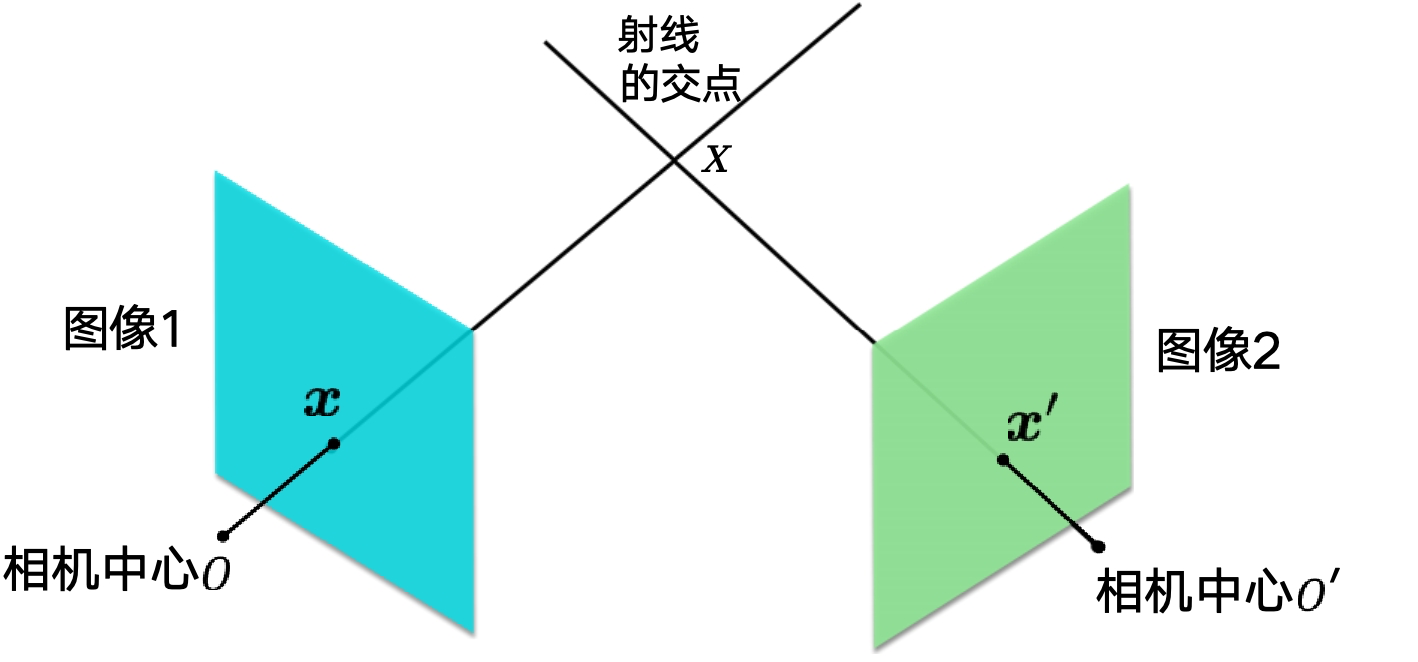
与第一个摄像机中心C的射线在第二幅图像上的投影。因此,存在一个从一幅图像上的点到另一幅图像上与之对应的对极线的映射。注意上面的推导在两个摄像机中心相同时不能采用.因为,如果 C是P和P’两个摄像机共同的中心,则。称为归一化摄像机矩阵,其中对于归一化摄影机矩阵的基本矩阵被称为本质矩阵。用归一化图像坐标表示对应点 x→x’时,本质矩阵的定义方程是。是图像上的点在归一化坐标下的表示。是第一幅图像的光心。
对于代码import cv2 as cvimport numpy as npcap = cv.VideoCapture(0)while(1):ret, frame = cap.read()hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)lower_blue = np.array([110,50,...
对象定位localization和目标检测detection判断图像中的对象是不是汽车–Image classification 图像分类不仅要判断图片中的物体还要在图片中标记出它的位置–Classification with localization定位分类当图片中有 多个 对象时,检测出它们并确定出其位置,其相对于图像分类和定位分类来说强调一张图片中有 多个 对象–Detection目标检测对
深度学习对数据集的预处理因为在使用神经网络的时候常常采用的图片数据集,常常是一个尺寸相同的,但是我们下载来的数据集往往尺寸不一定相同。所以我们应该转化为相同尺寸的数据集。笔者首先考虑过用cv2.resize()把图片变为等尺寸的,在同torch.form_numpy()转化成tensor来出来,但是resize改变了图片等的比例,所以在神经网络中的拟合出的结果可能不是我们所希望的。所以我们采用..
吴恩达机器学习第六章【Logistic Regression】文章目录吴恩达机器学习第六章【Logistic Regression】Classification【分类问题】Hypothesis Representation 【假说表示】Decision Boundary【判定边界】Cost Function【代价函数】Simplified Cost Function and Gradient D.
目标检测IoU对于一个检测器,我们需要制定一定的规则来评价其好坏,从而选择需要的检测器。对于图像分类任务来讲,由于其输出是很简单的图像类别,因此很容易通过判断分类正确的图像数量来进行衡量。物体检测模型的输出是非结构化的,事先并无法得知输出物体的数量、位置、大小等,因此物体检测的评价算法就稍微复杂一些。对于具体的某个物体来讲,我们可以从预测框与真实框的贴合程度来判断检测的质量,通常使用IoU(Int
NAO机器人的小记文章目录NAO机器人的小记APIALMemoryALMotionProxy :: setStiffnessesALMotionProxy :: getStiffnesses技术通过对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模。图像增广的另一种解释是,随机改变训练样本可以降低模型对某些属性的依赖,从而提高模型的泛化能力。简单说就是,通过一些技巧,让图像数据变多;图像增广基于现有训练数据生成随机图像从而应对过拟合。import sysfrom IP...
深度学习对数据集的预处理因为在使用神经网络的时候常常采用的图片数据集,常常是一个尺寸相同的,但是我们下载来的数据集往往尺寸不一定相同。所以我们应该转化为相同尺寸的数据集。笔者首先考虑过用cv2.resize()把图片变为等尺寸的,在同torch.form_numpy()转化成tensor来出来,但是resize改变了图片等的比例,所以在神经网络中的拟合出的结果可能不是我们所希望的。所以我们采用..