




- @qq_42049231
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
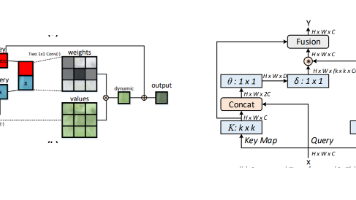
本文详细介绍了如何在YOLOv8模型中集成CoTNet模块以提升检测性能。主要内容包括:1) CoTNet模块的原理说明,该模块通过上下文编码和动态注意力机制增强特征提取能力;2) 代码实现步骤,包括在YOLOv8中添加C2f_CoT自定义模块、修改相关配置文件(init.py、task.py)和创建新的yaml模型配置文件;3) 训练新模型的方法。通过将YOLOv8中原有的C2f模块替换为C2f
本文介绍了大语言模型指令微调的完整流程,主要包括三个关键步骤:1)数据准备,将指令-回复对转换成Alpaca格式并划分数据集;2)模型配置与微调,构建自定义数据集类和处理函数,加载预训练GPT-2模型进行微调;3)评估方法,通过生成测试集响应和使用Llama3模型自动评分来评估对话性能。文中详细展示了数据处理、批次构建、模型训练的具体实现,并提出了结合多项选择测试、人类评估和自动化评估的综合评估策
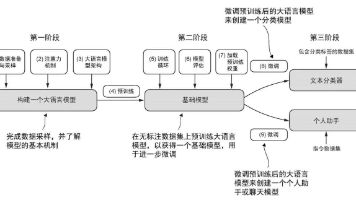
大语言模型(LLM)是基于Transformer架构的深度神经网络,以其超大规模参数量(数百至数千亿)和海量训练数据著称。核心应用包括文本生成、机器翻译、内容创作等,但通用模型在专业领域存在局限。构建LLM需经历三阶段:基础模型预训练、数据集准备、针对性微调(指令微调或分类微调)。Transformer通过自注意力机制捕捉长距离语义依赖,其编码器-解码器结构能有效处理输入文本并生成连贯输出,这正是
本文介绍如何训练GPT2模型,并且介绍了两个文本生成策略,温度缩放和Top-k采样来增加模型生成文本的多样性。此外,在最后还详细展示了如何加载OpenAI开源的tensorflow版本的GPT2模型参数
本文介绍了如何对预训练的大语言模型进行微调以适应垃圾邮件分类任务。首先构建平衡数据集,使用GPT2 tokenizer构建数据加载器。模型微调时冻结大部分参数,仅微调最后一层transformer块、归一化层和修改后的输出层(2分类)。实验展示了模型在垃圾邮件分类上的应用效果,并提供了模型保存和加载方法。该方法有效利用预训练模型的特征提取能力,通过有限微调实现特定分类任务。
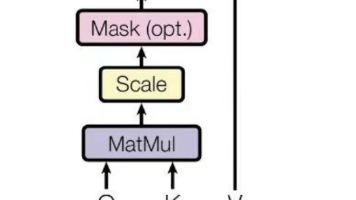
本文系统阐述了注意力机制的发展与实现。首先介绍自注意力机制的基本原理,包括点积计算、归一化和上下文向量生成;其次详细说明带可训练权重的注意力机制实现过程,通过查询、键、值向量计算注意力分数;然后探讨因果注意力机制,限制模型只能关注当前及之前的词元;最后解析多头注意力机制,通过分割和合并多个注意力头来提升模型性能。文章通过代码示例展示了从基础到进阶的各种注意力机制实现方法,为理解现代Transfor
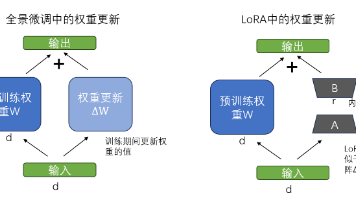
LoRA(低秩自适应)是一种高效的参数微调技术,通过引入低秩矩阵A和B来调整预训练模型权重,大幅减少需训练参数数量(从1.24亿降至266万)。该方法冻结原始权重,仅更新低秩矩阵,既保留预训练知识又降低计算成本。实验将LoRA应用于GPT-2模型的垃圾邮件分类任务,展示了其在保持模型性能的同时显著提升训练效率的优势。结果表明LoRA特别适合大模型微调,通过调整rank和alpha参数可平衡模型性能
本文介绍了大语言模型指令微调的完整流程,主要包括三个关键步骤:1)数据准备,将指令-回复对转换成Alpaca格式并划分数据集;2)模型配置与微调,构建自定义数据集类和处理函数,加载预训练GPT-2模型进行微调;3)评估方法,通过生成测试集响应和使用Llama3模型自动评分来评估对话性能。文中详细展示了数据处理、批次构建、模型训练的具体实现,并提出了结合多项选择测试、人类评估和自动化评估的综合评估策
本文介绍如何训练GPT2模型,并且介绍了两个文本生成策略,温度缩放和Top-k采样来增加模型生成文本的多样性。此外,在最后还详细展示了如何加载OpenAI开源的tensorflow版本的GPT2模型参数