




- @qq_42019881
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
MeanVC 2:鲁棒低延迟流式零样本语音转换 摘要:本文提出MeanVC 2,一种改进的流式零样本语音转换系统,解决了MeanVC存在的三个关键问题。通过引入未来感受野分块(FRC)机制,在扩散Transformer解码器中显式调度感受野,移除了干净分块的教师强制策略,显著提升了训练效率。FRC机制允许40ms小分块下的稳定转换。同时提出的通用音色Token编码器(UTTE)基于全局说话人嵌入构
VoxCPM 1.5是面壁智能推出的新一代端到端文本转语音模型,通过创新的半离散残差表示架构解决了传统TTS模型在表现力与稳定性之间的权衡问题。该模型采用分层语义-声学建模方法,将语义韵律规划与细粒度声学渲染分离,同时通过可微量化瓶颈实现端到端训练。VoxCPM 1.5支持44.1kHz高采样率音频克隆,仅需6.25个token生成1秒音频,效率提升显著。模型在180万小时双语语料上训练,实现了开
vLLM显存管理核心要点解析 gpu_memory_utilization参数是vLLM显存管控的关键,默认0.9用于分配模型权重、KV Cache等业务显存,需预留10%空间防止OOM。 显存占用包含两部分: vLLM业务显存(受参数管控) 系统隐形开销(CUDA驱动、PyTorch缓存等不受控) vLLM显存"暴涨"本质是其预分配机制所致: 启动即锁定显存池用于KV Cac
vLLM显存管理核心要点解析 gpu_memory_utilization参数是vLLM显存管控的关键,默认0.9用于分配模型权重、KV Cache等业务显存,需预留10%空间防止OOM。 显存占用包含两部分: vLLM业务显存(受参数管控) 系统隐形开销(CUDA驱动、PyTorch缓存等不受控) vLLM显存"暴涨"本质是其预分配机制所致: 启动即锁定显存池用于KV Cac
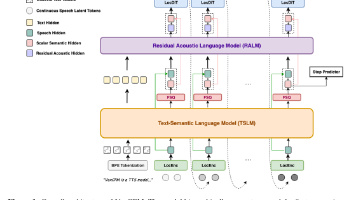
摘要 MOSS-TTS是一套基于离散音频令牌与自回归建模的语音生成基础模型,采用可扩展技术范式构建。其核心组件包括:1)MOSS-Audio-Tokenizer——支持12.5fps高压缩率的因果Transformer音频分词器;2)两种开源生成架构——简洁可扩展的MOSS-TTS和高效低延迟的MOSS-TTS-Local-Transformer;3)百万小时级多语言预训练数据。模型支持零样本声音
摘要 SoulX-Singer是一款工业级开源歌声合成模型,由Soul App联合高校团队开发,支持零样本多语言歌声生成。基于4.2万小时高质量歌声数据训练,模型采用流匹配架构和双控制模式(MIDI乐谱/F0旋律),实现精准音高、跨语言音色克隆及歌词编辑。通过严格的数据处理流水线(人声分离、歌词/音符转写)构建多语言数据集,并推出专用评估基准SoulX-Singer-Eval。实验表明,其合成质量
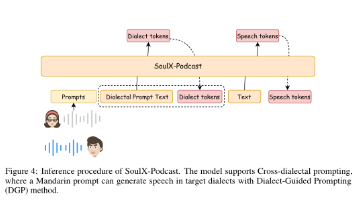
摘要: SoulX-Podcast是一款基于大型语言模型的多角色对话语音合成系统,专为播客风格的长篇对话设计。该系统支持普通话、英语及多种中国方言(四川话、粤语等),具备零样本语音克隆能力,并能通过副语言控制增强对话自然度。实验显示,SoulX-Podcast可稳定生成90分钟以上的多角色对话,保持音色一致性并实现流畅的说话人转换。采用两阶段生成框架(语义标记预测+声学特征转换),基于扩展的Qwe
Step-Audio-EditX是一款开源的基于大语言模型的音频处理系统,具备文本转语音(TTS)和迭代音频编辑能力,可精细控制情感、风格等语音属性。该系统创新性地采用大间隔合成数据训练方法,无需依赖额外先验知识或辅助模块,即可实现跨声音的高表现力控制。相比MiniMax-2.6-hd等商业模型,它在情感编辑等任务中表现更优。系统包含音频标记器、30亿参数LLM和流匹配解码器三部分,通过双码本标记
RVQ通过分层残差量化的创新设计,解决了传统VQ在高维数据与高比特率场景下的核心痛点,成为现代AI系统中数据压缩、特征离散化的关键技术。其在神经音频编解码、计算机视觉与大语言模型优化等领域的广泛应用,证明了其在效率与精度之间的优异平衡能力。随着AI模型规模扩大与边缘设备普及,RVQ将在更多低延迟、高压缩比场景中发挥重要作用。
摘要:矢量量化(VQ)是一种通过有限"标准模板"近似无限原始数据的技术,具有数据压缩和特征离散化双重功能。其核心包括输入向量、码本和量化误差三个组件,通过编码(寻找最近码向量)和解码(重建数据)两个步骤实现。码本通常采用K-Means聚类算法优化生成,以最小化量化误差。VQ在AI领域(如语音合成)的关键应用是将连续特征转化为离散符号,使模型能像处理文字一样处理语音/图像数据。该