




- @qq_41058526
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
线性注意力机制(Linear Attention)是一类通过降低计算复杂度来优化传统注意力机制的方法,尤其适用于长序列任务。业界针对KV Cache的优化,衍生出很多方法,这里我根据自己的积累,稍微总结下,只简单描述优化的思路,不过多展开。每个head的Query 共享K和V矩阵,KV cache的内存占用直接降到了。不过这么做的效果还是会有折扣的,即性能上的下降不可避免,也会影响模型的稳定性。的
hard attention记stst s_{t} 为decoder第 t 个时刻的attention所关注的位置编号stistis_{ti} 表示第 t 时刻 attention 是否关注位置 ististi s_{ti} 服从多元伯努利分布(multinoulli distribution), 对于任意的 t , sti,i=1,2,...,Lsti,i=1,2,...,Ls_{t...
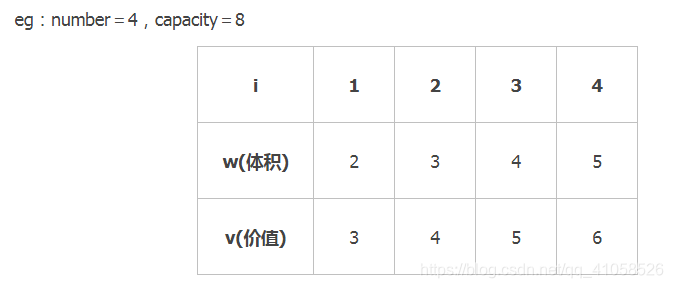
注意:边界条件的判断取地址符传参的使用溢出问题,long long题目来源:https://github.com/ZXZxin/ZXBlog/blob/master/%E5%88%B7%E9%A2%98/InterviewAlgorithm.md01背包参考:https://www.cnblogs.com/Christal-R/p/Dynamic_program...
VS code romote ssh配置主要参考这篇博文:https://www.jianshu.com/p/d7c9cef525bc出现Connecting was canceled.问题主要报错:[13:34:40.403] Log Level: 2[13:34:40.414] remote-ssh@0.51.0[13:34:40.414] win32 x64[13:34:40....
什么是机器学习1.初步认识机器学习:通过对于data的学习使得某些performance得到增强2.哪些问题可以使用机器学习3.具体定义3.1 问题组成3.2 学习形式其中(重点),3.3 定义总结...