




- @qq_40604302
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
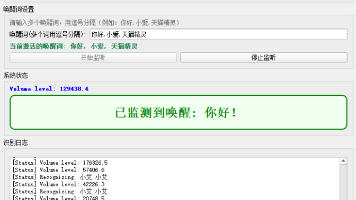
技术特性是一款轻量级、高精度的离线语音唤醒引擎,支持多平台部署(Linux、Windows、macOS、Android、iOS、RaspberryPi等)。采用深度神经网络技术,模型大小仅数MB,支持自定义唤醒词训练,无需云端依赖,完全本地化运行。核心特性离线唤醒:无需网络连接,保护用户隐私低功耗运行:CPU占用率低,适合嵌入式设备多唤醒词支持:可同时识别多个自定义唤醒词抗噪能力强:在嘈杂环境下仍
Hermes Web UI 是专为 Hermes Agent(NousResearch 开源的多平台 AI Agent 框架)设计的全功能 Web 管理面板。
本文评估了三种语音唤醒技术方案:高通DSP语音唤醒、Porcupine(Picovoice)和Vosk。高通DSP基于Hexagon/Kalimba DSP实现超低功耗监听,但依赖特定硬件;Porcupine作为轻量级神经网络引擎,支持多平台且资源占用极低(CPU<1%,内存~5MB),但自定义中文词需付费;Vosk基于Kaldi实现离线语音识别,支持免费自定义词但资源消耗高(CPU15-4
Porcupine是一款由Picovoice开发的轻量级跨平台语音唤醒引擎,支持离线运行和多语言唤醒词检测。其核心特性包括低延迟响应、多平台兼容(Windows/Linux/macOS/Android等)和资源高效(仅2MB内存占用)。部署指南详细介绍了Windows系统下的安装步骤,包括获取AccessKey、Python环境配置和命令行测试方法,支持内置和自定义唤醒词。此外还提供了基于PyQt
本文评估了三种语音唤醒技术方案:高通DSP语音唤醒、Porcupine(Picovoice)和Vosk。高通DSP基于Hexagon/Kalimba DSP实现超低功耗监听,但依赖特定硬件;Porcupine作为轻量级神经网络引擎,支持多平台且资源占用极低(CPU<1%,内存~5MB),但自定义中文词需付费;Vosk基于Kaldi实现离线语音识别,支持免费自定义词但资源消耗高(CPU15-4
摘要:本文实现了一个基于Gradio的音频处理界面,整合Whisper语音识别、Pyannote说话人分离和Qwen3-1.7B文本处理功能。由于Tkinter打包报错(Python整数范围错误),暂时采用Gradio实现。系统支持上传音频文件,自动生成带说话人标签的文本,并通过大模型进行文档整理。关键特性包括:说话人识别噪声过滤、文本去重处理、时间戳优化对齐,以及Qwen模型的内容摘要生成功能。
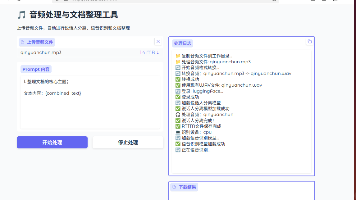
这段代码是一套 “音频处理→说话人分离→语音识别→时间对齐→文档整理” 的全流程自动化工具,核心用于处理多人音频,最终输出结构化的文本整理结果(主题 + 大意)。
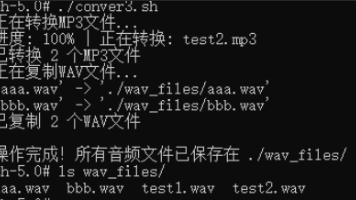
本文介绍了使用FFmpeg命令行工具将MP3转换为WAV格式的方法,包括单文件转换和批量转换脚本。主要内容: 单文件转换命令示例 批量转换脚本(显示进度条) 处理Windows/Unix换行符差异 优化脚本:自动创建输出目录,同时处理MP3转换和WAV文件复制 最终脚本支持自动检测并处理目录中的所有MP3和WAV文件 脚本特点:显示转换进度、自动处理文件格式、错误检查、输出目录管理。适用于需要批量
FreeRTOS常用API一、任务[task.h]1、任务创建如果任务成功创建并加入就绪列表函数返回pdPASS,否则函数返回错误码,具体参见projdefs.h。xTaskCreate((TaskFunction_t) master_task_main,/* 任务入口函数 */“MASTER”,/* 任务名字 */64*1024,/* 任务栈大小 */NULL,