- @qq_39838728
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
找到我本地linux服务器上面以前下载的ollama模型,然后复制到这个没网络的服务器上面。注:刚开始我将模型文件复制错地方了,导致一直找不到模型文件,我复制到/home/user/.ollama下面了,只想着找到.ollama文件,复制到下面,没想到复制错了。所谓投资,无非是用现在的资源换取未来的资源。接着去添加dify即可,记得dify的网络要跟ollama的网络互通,可以将两个应用部署到同一

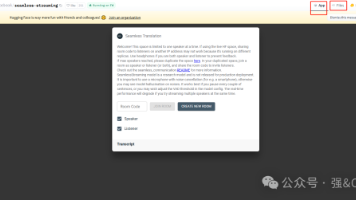
facebook也推出了实时语音翻译系统,支持一百多个国家语音,经实测效果很不错,使用了5G左右显存。
找到我本地linux服务器上面以前下载的ollama模型,然后复制到这个没网络的服务器上面。注:刚开始我将模型文件复制错地方了,导致一直找不到模型文件,我复制到/home/user/.ollama下面了,只想着找到.ollama文件,复制到下面,没想到复制错了。所谓投资,无非是用现在的资源换取未来的资源。接着去添加dify即可,记得dify的网络要跟ollama的网络互通,可以将两个应用部署到同一
awesome-digital-human-live2d是一个轻量级开源实时数字人项目,对配置要求不高。搭建过程也比较简单。

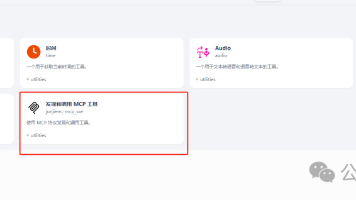
总结:感觉mcp服务就是大模型将你的自然语言转换为api识别的参数,然后调取相关服务的api,不用自己写代码调用api了。先不管它,点击上面的mcp服务,选择install,点击下方按钮configure mcp servers,然后将配置文件填进去。选择聊天界面,选择需要使用的大模型。有本地的可以添加本地的,没有本地的可以添加各大平台在线的。最近mcp协议比较火,好多平台都已经开通了mcp协议,

大模型直接与数据库交互,实现基本增删改查操作

MCP数据库服务接入dify,让你的智能体操作数据库
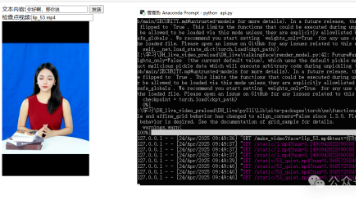
DH_LIVE一个实时数字人解决方案,从输入文字到数字人对口型说话用时2-3秒。
下面是原上传音频的内容。支持语气(高兴、悲伤等),多语言,加速慢速,还可将克隆的音频设置成哼唱的。发现一个好用的语音克隆工作流,大家在做数字人视频的时候可以克隆自己的声音,或者别的好听的声音。大家在搭建的过程中有遇到什么问题,或者有什么想实现的功能欢迎留言,大家一起讨论学习。若服务器受网络限制可以先在本地下载好源码,再移到服务器上面安装。2、接着可以去comfyui的manger中安装此插件。上面
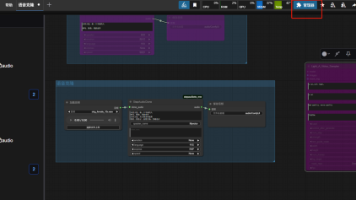
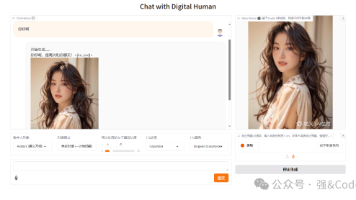
实时对话数字人VideoChat是由阿里达摩院开源的一个实时数字人对话。经实测,效果还不错,每次对话数字人生成视频的时间大致在6-8秒钟,今天将环境搭建步骤及遇到的问题整理下