




- @qq_39463175
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
matlab 中对大型数据进行处理时,经常需要把矩阵里的某一些数据进行处理。如所以行或者列重新储存再某个cell的子cell中。下面是一个简单实现:load('lncRNAGene.mat')%加载数据load('GeneDisease.mat')R12=LGasso'; %R12为矩阵,15527*240R13=GDasso; %R13为矩阵,15527*8450...
最近发现一个秘密,用python可以完成批量的诸如课程设计、学年设计、毕业论文模版,即从数据采集,数据分析,数据可视化,GUI界面等不同模块组合。下面介绍我自己写的一个简单例子。一 摘要定向网络爬虫可以帮助人们快速地从庞大的互联网中获取特定的信息,是当今信息时代非常有用的助手。Python 是一门面向对象、解释型高级程序设计语言,语法简洁清晰,具有丰富强大的类...
在阿里云先购买服务器,然后配置好安全组后,进行服务器使用,bt default命令 可以得到访问宝塔管理链接入口,一开始我使用该命令后,得到的链接地址是http://:8888/data这个链接一看就是有问题的,后面我重新启动服务器后就陈功了重新启动:如果还不行,重新配置安全组,加入8080或者8888端口进入后点击安全组配置下面是我手动添加:...
如果你是刚读研的小白,准备投人工智能机器学习数据挖掘领域论文,可以参考下面的列表,选择自己适合的会议。投摘要一般都会提前1个星期左右。人工智能机器学习数据挖掘会议期刊论文很多,有时候会忘记重要的一些时间节点,用此篇记录重要日期范围,方便以后检索和投稿; 投稿主要使用CMT系统,很方便进行管理。下面介绍的这些会议基本上都用的CMT系统,但目前我了解到有ECML和SIGIR不是。目前已经参与过投稿的会
如果你是刚读研的小白,准备投人工智能机器学习数据挖掘领域论文,可以参考下面的列表,选择自己适合的会议。投摘要一般都会提前1个星期左右。人工智能机器学习数据挖掘会议期刊论文很多,有时候会忘记重要的一些时间节点,用此篇记录重要日期范围,方便以后检索和投稿; 投稿主要使用CMT系统,很方便进行管理。下面介绍的这些会议基本上都用的CMT系统,但目前我了解到有ECML和SIGIR不是。目前已经参与过投稿的会
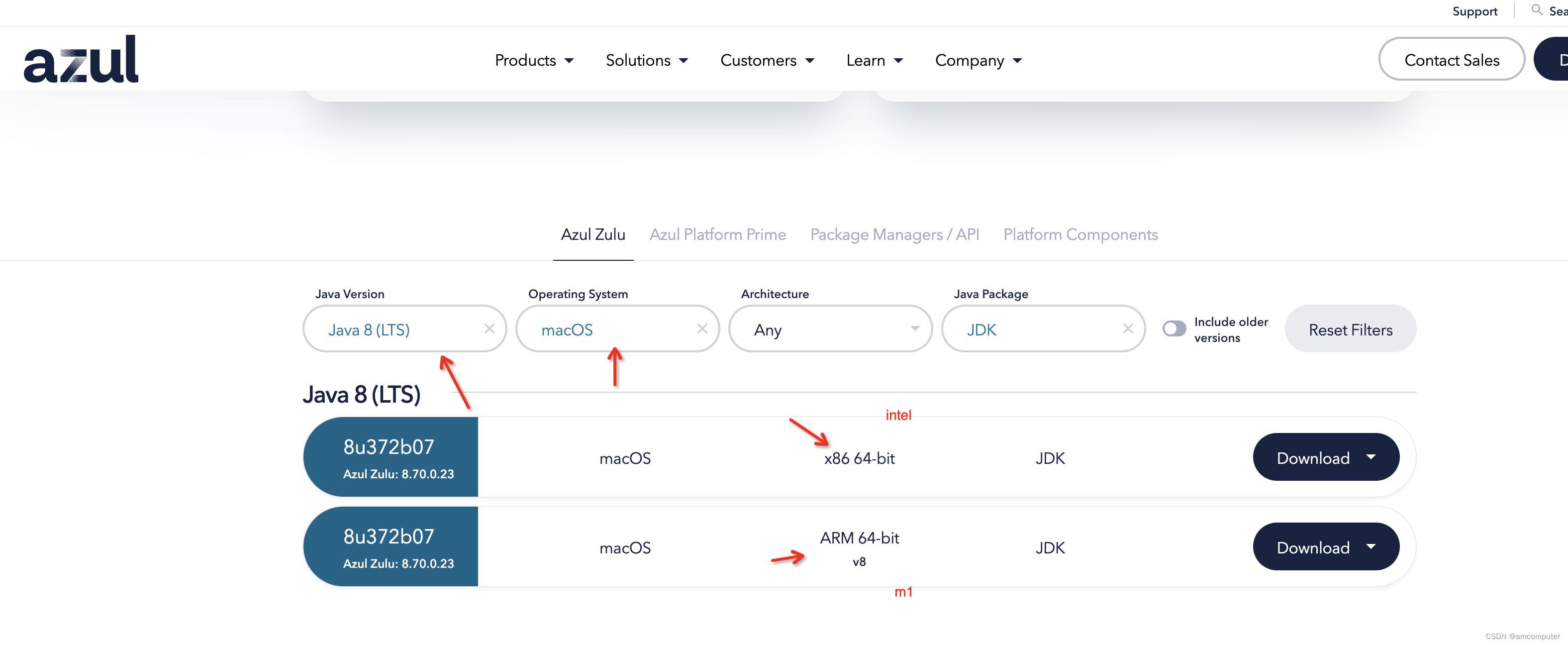
这里需要小心,不同版本选择的idea版本也不相同,版本选择错了,你发发型idea会特别卡,比如你是m1芯片,用了intel的idea, 打开2-4个项目工程,或者本地运行springboot项目,会特别卡。如果你是m1芯片,用了对应的idea, idea会非常顺化,打开10个工程都不卡。下面是笔者自己陪的()这个功能很实用,在idea最右下边, 右键然后勾选 memory indicator-内存
1背景基本情况:首先确保该类存在,并且导入路径正确,还是不能导入类。在idea中写好了类,在其他地方是能正常导入的,过了一段时间后,重新打开项目发现不能识别类,该类报红,也不能导入它,明明路径中也存在这个类,其他类正常,只有这个类不能导入,手动输入正确的包路径来导入,也是不能识别,还是报红。运行项目不通过,因为不能识别这个类:import com.yang.demo.RequestMappingG
报错信息:TypeError: can't convert np.ndarray of type numpy.int32. The only supported types are: float64, float32, float16, int64, int32, int16, int8, uint8, and bool.众所周知,在torch中,与numpy数组互相转换的API是torch.fr
需要安装pytorch,尝试了几次还是失败。同时,由于pytorch比较大,下载速度也比较慢,在这里总结快速安装pytorch步骤,以拱自己以后参考和同行参考。一 安装清华镜像在自己C盘这个路径下(C:\Users\1112\AppData\Roaming),主要是在AppData\Roaming这里,用户(1112)每个电脑可能不同(我的是win10)。然后新建文件夹pip,如下图:然后在pip
如果你是刚读研的小白,准备投人工智能机器学习数据挖掘领域论文,可以参考下面的列表,选择自己适合的会议。投摘要一般都会提前1个星期左右。人工智能机器学习数据挖掘会议期刊论文很多,有时候会忘记重要的一些时间节点,用此篇记录重要日期范围,方便以后检索和投稿; 投稿主要使用CMT系统,很方便进行管理。下面介绍的这些会议基本上都用的CMT系统,但目前我了解到有ECML和SIGIR不是。目前已经参与过投稿的会