




- @qq_36776216
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文系统介绍了三类主流预训练语言模型:Encoder-only(BERT系列)、Encoder-Decoder(T5)和Decoder-only模型。重点解析了BERT的双向编码结构、MLM和NSP预训练任务;RoBERTa通过移除NSP、动态遮蔽等优化提升性能;ALBERT采用参数分解和共享实现轻量化;T5创新性地将所有NLP任务统一为文本到文本形式。文章揭示了Transformer架构的潜力、
本文摘要:大语言模型(LLM)是参数规模达数十亿至万亿、在超大规模语料上训练的语言模型,代表NLP领域的最新范式。LLM的核心特征包括涌现能力、上下文学习、指令遵循和逐步推理等,使其在复杂任务上远超传统模型。文章介绍了LLM的三阶段训练流程(预训练、监督微调、强化学习),并分析了2022-2025年国内外主要LLM的发展历程。特别探讨了LLM的多语言支持、长文本处理、多模态拓展等特点及其面临的幻觉
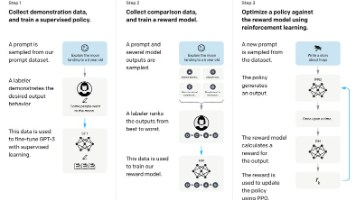
本文摘要:大语言模型(LLM)是参数规模达数十亿至万亿、在超大规模语料上训练的语言模型,代表NLP领域的最新范式。LLM的核心特征包括涌现能力、上下文学习、指令遵循和逐步推理等,使其在复杂任务上远超传统模型。文章介绍了LLM的三阶段训练流程(预训练、监督微调、强化学习),并分析了2022-2025年国内外主要LLM的发展历程。特别探讨了LLM的多语言支持、长文本处理、多模态拓展等特点及其面临的幻觉
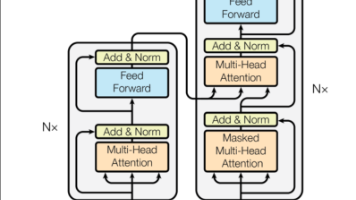
本文详细解析Transformer架构的核心组件与实现原理。首先介绍注意力机制作为Transformer的核心突破,包括其解决RNN缺陷的能力、自注意力与多头注意力机制的计算公式及PyTorch实现。重点剖析了Transformer的Encoder-Decoder结构,展示前馈神经网络(FFN)的代码实现,并说明其在序列转换任务中的应用。文章通过数学公式和代码示例相结合的方式,深入浅出地讲解了从基
本文系统介绍了三类主流预训练语言模型:Encoder-only(BERT系列)、Encoder-Decoder(T5)和Decoder-only模型。重点解析了BERT的双向编码结构、MLM和NSP预训练任务;RoBERTa通过移除NSP、动态遮蔽等优化提升性能;ALBERT采用参数分解和共享实现轻量化;T5创新性地将所有NLP任务统一为文本到文本形式。文章揭示了Transformer架构的潜力、
微信公众号:Java成长录感兴趣可以关注下哦,Java知识点,学习路线规划,Java相关电子书,一起学习呀!。打开虚拟机发现屏幕一直闪烁,不过命令什么都是可以执行的,所以上网找了一下,有的说内核问题,有的说桌面问题,不过好像都是不行的,最后发现是显卡驱动问题,其实想想也是,其他什么问题都是正常的就是屏幕在一直闪烁。这时在网上找的一段安装驱动的代码!参考自:https://www...