- @qq_35704550
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
专注后端实战技术分享,不限于PHP,Python,JavaScript, Java等语言,致力于为猿友们提供有价值,有干货的内容。
快递鸟的接口对接其实很简单,先去官网注册账号,登陆把基本信息填好,然后在产品管理中订购一下“物流查询”,免费,不过其他产品是收费,免费的有对接口调用频率限制,结合自己的应用流量够用就可以。 使用前复制一下账号下的用户ID和API key,并且快递鸟对各个API提供了各种语言的demo,其实下载下来,找一下平时寄快递的运单号,本地运行一下就能用了。(名称: KdApiSearchDe...
COS简介: 腾讯云提供的一种对象存储服务,供开发者存储海量文件的分布式存储服务。可以将自己开发的应用的存储部分全部接入COS的存储桶中,有效减少应用服务器的带宽消耗等。个人也可以通过腾讯云账号免费使用COS6个月,https://cloud.tencent.com/product/cos整体流程简介: 1. 前端引入cos的SDK文件2. 监听上传控件,并在图片加载至网页临时流中发起签名请求3.
前言:只要是一个愿折腾的人,应该对安卓手机ROOT并不陌生。当了解了SuperSU神器后,又会发现Xposed,Magisk,太极等的一波新天地。有了这些,可以让你手机在使用应用的基础功能外还添加了连会员都体验不到的权限。手机本身ROOT外加上安装了以上框架以及框架的知名模块,手机就像开启了上帝模式,拥有最高权限的发烧机友。下面就简单介绍以下框架,具体介绍安装和使用过程。...
在规则编码中,我们常常会遇到需要通过多种区间判断某种物品分类。比如二手物品的定价,尽管不是新品没有 SKU 但是基本的参数是少不了。想通过成色来区分某种物品,其实主要是确定一些参数。然后根据参数数据以及参数对应成色的所有数据集归档用机器学习训练,这样机器就可以得出规则了
直播小玩法是抖音里的一种统称,其他平台有叫直播弹幕小游戏,而抖音里的直播小玩法包括两种,弹幕小游戏和互动插件。个人主体开发者申请软著后,符合平台规范都能上架。上架后,只要有主播用了你的开播,就能享受直播间的礼物分成,分成比例见下图。比例看着确实比较低,但他也有一个很符合被动收益的优势:一经开发,多端部署,多人开播,无需直接面向观众。就是我们开发后,其实是可以发布到多个平台的,已知对个人开发者开发弹
一.下载MTK SP FlashTool工具(含驱动)并解压二.安装驱动(Win10系统请跳过此步)1.将手机关机,插入电脑USB接口2.打开设备管理器3. 选中VCOM设备4.右键更新驱动程序5.选择第二项浏览计算机以查找驱动6.点击浏览,定位到SP FlashTool\MTK Phone Driver驱动文件夹点击下一步安装驱动。三.开始解锁BL1.运行flash_tool2.点击“下载D..

MCP 英文全称 Model Context Protocol,字面意思就是模型上下文协议,也有说他是为解决大语言模型商业落地最后一公里而生。1. 数据不实时,因为都是对历史数据进行训练,而对于像新闻、天气、股市这种一直变动的是无法获取的。2. 功能有限,虽然他可以通过提示词实现很多功能,但还是因为旧数据原因,没法灵活更新功能。3. 私密数据不保障,已知知名模型训练都是抓取的全球公开数据,而商业落

在规则编码中,我们常常会遇到需要通过多种区间判断某种物品分类。比如二手物品的定价,尽管不是新品没有 SKU 但是基本的参数是少不了。想通过成色来区分某种物品,其实主要是确定一些参数。然后根据参数数据以及参数对应成色的所有数据集归档用机器学习训练,这样机器就可以得出规则了
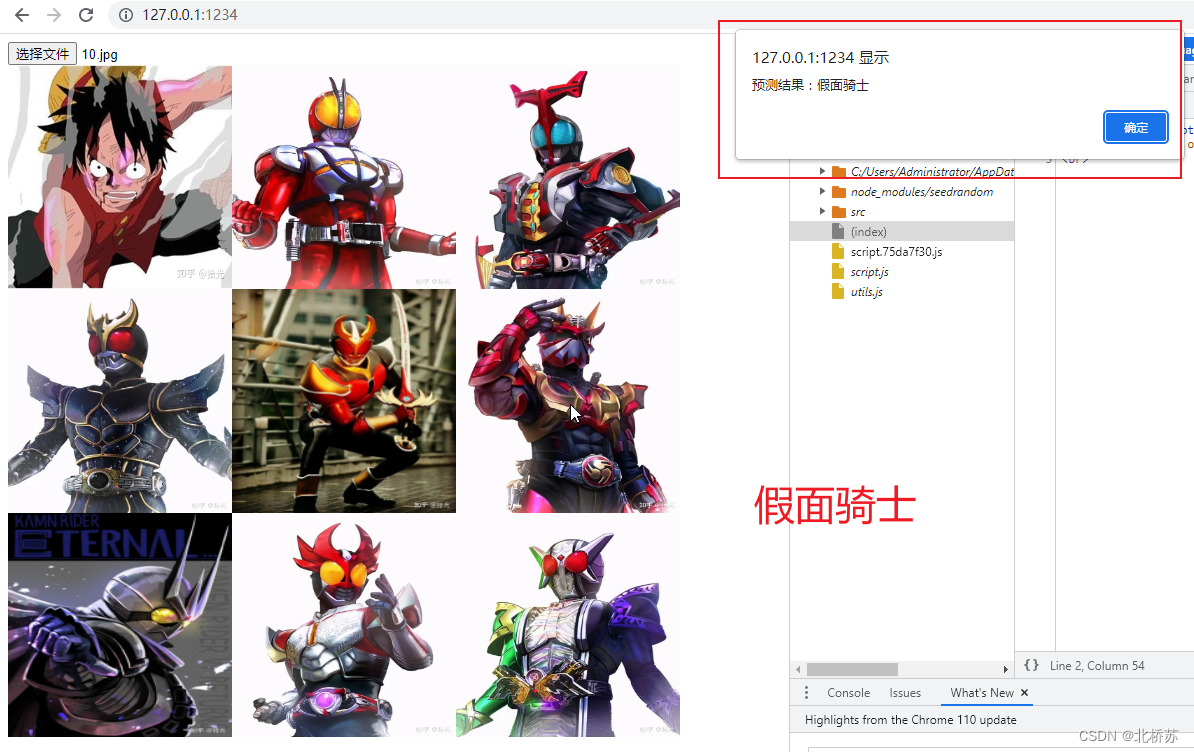
内容和资源的采集,反手就是某虫了。在网络上,经过近几年的营销渲染,可能首选是用 Python 做脚本。而这次是用 PHP 的 QueryList 来做采集,下面也就是采集的编码过程和踩坑解决方法,最后再对采集图片进行标注和训练。
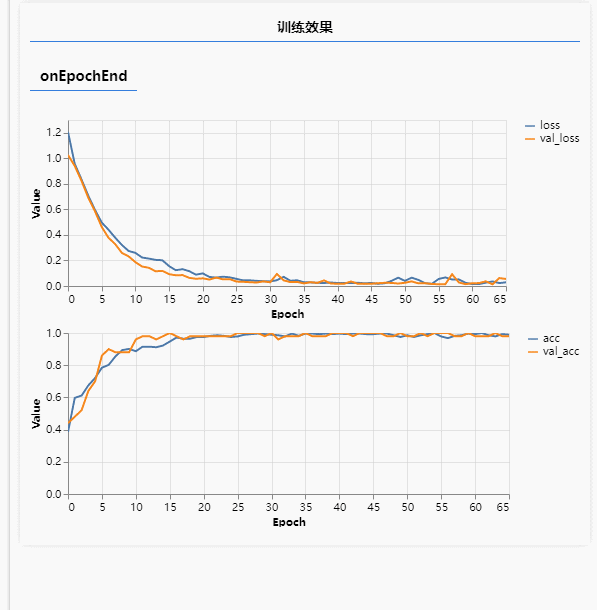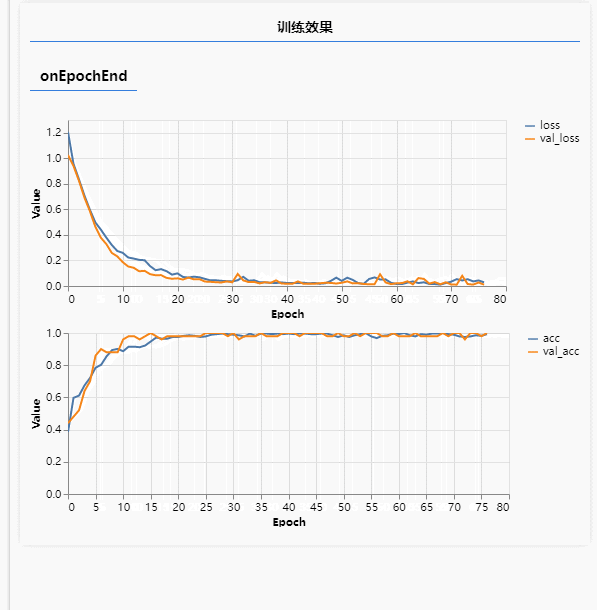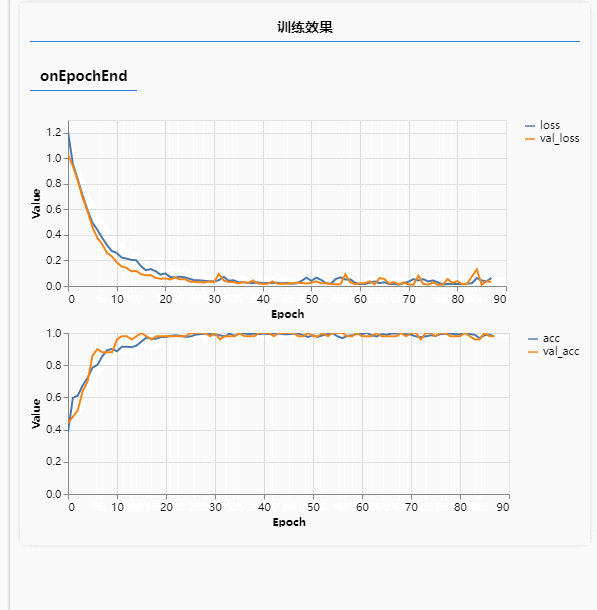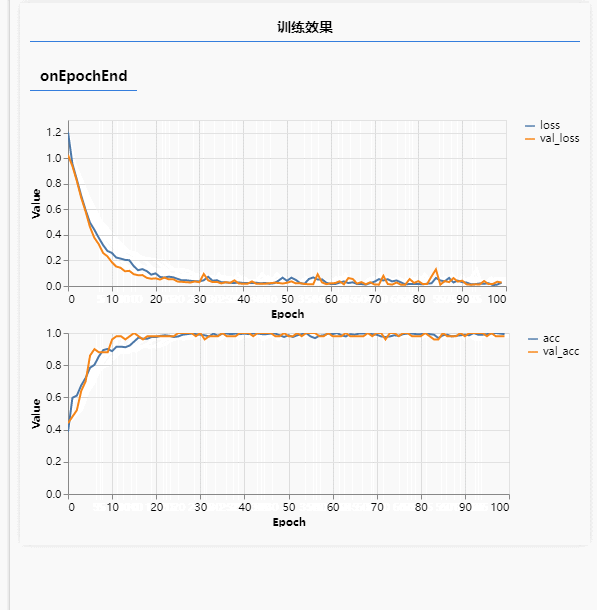
这种功能在应用场景里就比较多了,比如图标素材站点,用户通过上传一个图标,系统会自动匹配出相似的图标,还有二手平台,用户通过上传闲置物品图片,平台自动给出分类等,这些也都是前期对海量图片进行了标注训练而得到一个损失率极低的模型。下面就通过简答的代码实现一个小的动漫分类