- @qq_34941290
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
梅尔滤波器组特征(FBank)- 现代深度学习ASR的主流输入FBankkmln∑i∣Xim∣2⋅HkiϵFBankkmlni∑∣Xim∣2⋅Hkiϵ其中HkiH_k(i)Hki为第kkk个梅尔滤波器在频点iii的权重。梅尔频率倒谱系数(MFCC)- 传统GMM-HMM ASR的标准特征Cn∑k1KlogMk⋅cosnk−12πKn01N−1C。

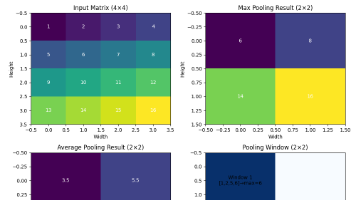
池化(Pooling)是深度学习中的一种重要操作,主要用于降低特征图的空间维度(高度和宽度),同时保留最重要的特征信息。池化操作通过减少参数数量和计算量来防止过拟合,并提高模型的平移不变性。与卷积层不同,池化层没有可学习的参数,只有超参数如核大小、步长和填充。池化操作通常应用于卷积神经网络(CNN)中,跟在卷积层之后,用于逐步减少空间分辨率,同时增加通道深度。常见的池化类型包括最大池化(Max P
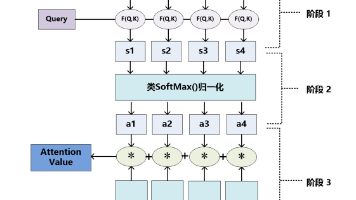
深入理解注意力机制:从人类认知到深度学习注意力机制(Attention Mechanism)是深度学习中一种模仿人类视觉和认知系统工作方式的技术。就像人类在观察复杂场景时会聚焦于重要部分而忽略次要信息一样,注意力机制让神经网络能够有选择地关注输入数据中最相关的部分。1.1 人类注意力类比想象你在阅读一篇文章时:• 你不会同时关注所有单词• 你会聚焦于关键词和重要句子• 根据上下文动态调整关注点•
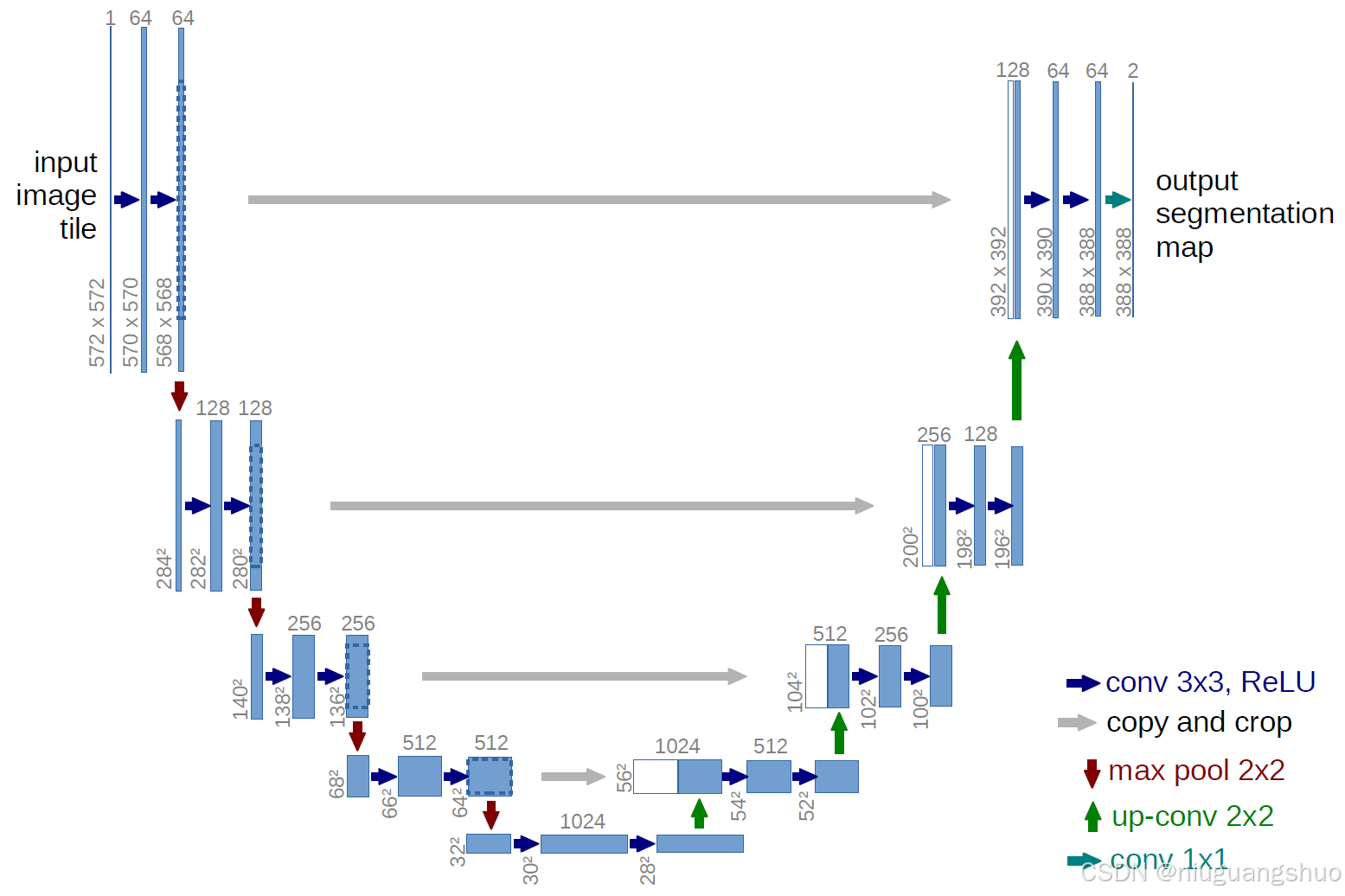
U-Net 是一种用于图像分割的卷积神经网络架构,其设计旨在处理生物医学图像分割任务。U-Net 的网络结构具有对称性,包含编码器和解码器两个主要部分,并通过跳跃连接(skip connections)将两者连接起来。U-Net 网络结构因其对称性而得名,形似英文字母 “U”。整个网络架构由蓝色和白色框表示特征图(feature map),不同颜色的箭头则代表了不同的操作和连接方式。
深度学习基本模块:深度可分离卷积深度可分离卷积(Depthwise Separable Convolution)是现代轻量级神经网络架构的核心组件,它通过将标准卷积分解为两个独立步骤,显著降低了模型的参数量和计算复杂度。这种高效的设计使其成为移动端和嵌入式设备上部署深度学习模型的理想选择。一、深度可分离卷积介绍1.1 结构深度可分离卷积将标准卷积分解为两个独立的操作:深度卷积(Depthwise
在深度学习领域,尤其是计算机视觉任务中,模型的可解释性和透明性变得越来越重要。可视化特征图和热力图是两种有效的技术,能够帮助研究人员和开发者理解模型的内部工作原理。本文将介绍可视化特征图和热力图的目的、实现方法,并提供简单的代码示例。

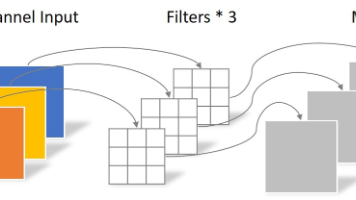
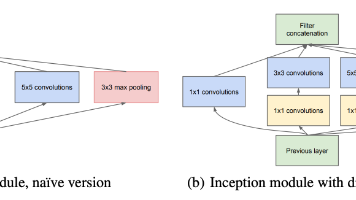
AlexNet的成功证明了深度网络的优势,随后出现的ZFNet、VGG等模型不断加深网络层数,扩大滤波器数量。正是在这样的背景下,Google Research团队提出了(代号GoogLeNet),在2014年ImageNet挑战赛中以top-5错误率6.67%的优异成绩夺冠,同时参数量仅有AlexNet的1/12,实现了。
在深度学习的领域,模型的复杂性和灵活性使得它们在训练数据上表现出色,但同时也容易导致过拟合。过拟合是指模型在训练数据上表现良好,但在未见数据上表现不佳。为了解决这个问题,研究人员提出了多种正则化技术,其中是一种非常有效且广泛使用的方法。。这意味着。
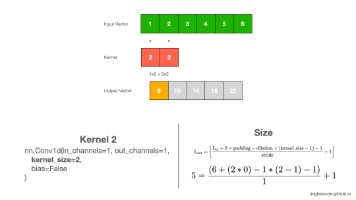
Conv1D 是一种专门用于处理一维数据的卷积层。它通过滑动卷积核(滤波器)在输入序列上进行卷积操作,从而提取局部特征。与二维卷积(Conv2D)不同,Conv1D 只在一个维度上进行卷积,适合处理时间序列数据、音频信号和文本数据。
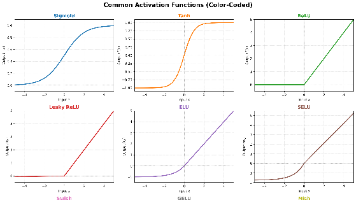
在深度学习中,激活函数(Activation Function)是神经网络的核心组件之一。如果没有激活函数,无论网络堆叠多少层,都只是,最终输出仍是输入的线性组合。。激活函数的主要价值在于。