




- @qq_28165595
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:MySQL数据库从utf8改为utf8mb4后,Java程序插入表情符号时出现编码错误。分析发现mysql-connector-java-5.1.46版本依赖MySQL服务端返回的编码信息,而动态修改编码参数后服务端仍返回旧编码。解决方法包括:1)重启MySQL使配置生效;2)为连接器打补丁使其额外检查collation参数;3)升级到5.1.47+版本直接支持utf8mb4映射。此外还指出

Apache Tika是一个强大的内容分析工具,支持从多种文件格式(如文档、PDF、图片等)中提取文本和元数据。其核心特性包括自动文件类型识别、OCR文字识别、语言检测和多线程处理。Tika架构包含解析器、配置管理和REST服务等组件,可广泛应用于文档管理、数据分析和信息安全领域。在SpringBoot项目中,Tika可集成用于敏感信息检测,通过正则表达式识别身份证号、信用卡号等敏感数据,实现数据

我研究了 Clawdbot 的架构,包括它如何处理等。对于 AI 工程师来说,这里有很多值得学习的地方。深入了解 Clawd 的底层原理,能让你更好地理解这个系统的能力边界,最重要的是,搞清楚它以及。这篇文章始于我个人的好奇心:Clawd 是如何处理内存的?它的可靠性究竟如何?在此,我将带你揭开 Clawd 运作机制的表层。

Elasticsearch实现"近实时"搜索的关键在于其精妙的架构设计:底层依托Lucene的倒排索引实现快速检索,采用内存缓冲区+Translog日志保证数据安全,通过定期Refresh操作(默认1秒)将数据转为可搜索的Segment。Segment的不可变性提升了查询效率,后台Merge优化索引结构。分布式架构通过分片并行查询和两阶段处理(先定位后取数)加速搜索。这种权衡设
store” 模式可以接受一个 --file 参数,可以自定义存放密码的文件路径(默认是~/.git-credentials)。如果我们git clone的下载代码的时候是连接的http形式,而不是git@git (ssh)的形式,当我们操作git pull/push到远程的时候,总是提示我们输入账号和密码才能操作成功,频繁的输入账号和密码会很麻烦。2、再次执行git pull拉取代码后,输入用户

日常开发中,我们无意间在master分支上开发了一些代码,由于一般企业都会对master分支代码提交合并有设置权限,所以如果代码写在了master分支上,但是又无法push到远程仓库,这时候怎么办呢,难道要把本地代码都拷贝下来,再切到一个新分支上,再把代码粘贴过来?这样肯定可以实现,但是如果改动的代码比较多,又比较分散,这种Ctrl+C加Ctrl+V的方法肯定是不行的。

一般在安装好git之后,我们可以在IDEA中集成git工具,后续就可以直接在IDEA中执行git操作,当然如果你非要直接打开git的命令窗口也是ok的。
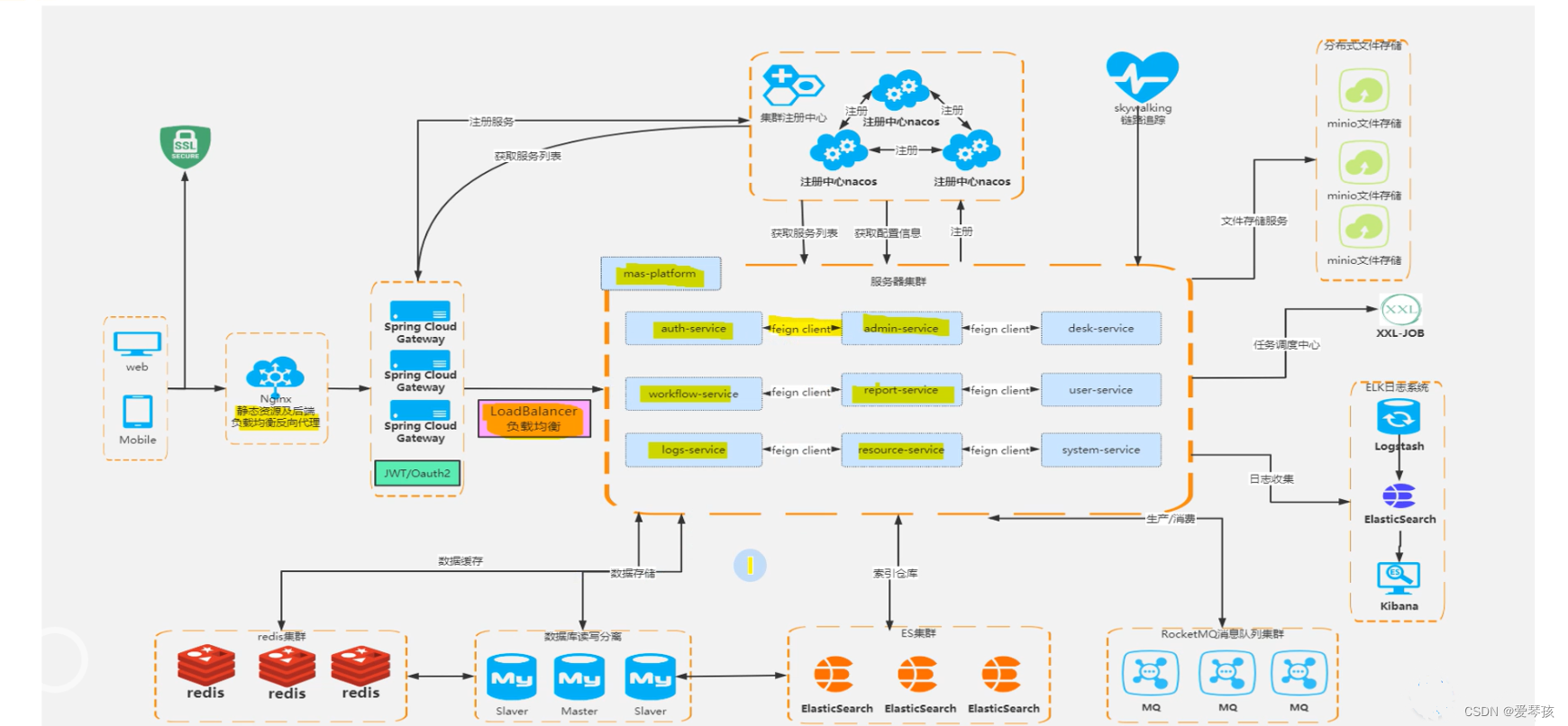
当前,微服务架构在很多公司都已经落地实施了,下面用一张图简要概述下微服务架构设计中常用组件。不能说已经使用微服务好几年了,结果对微服务架构没有一个整体的认知,一个只懂搬砖的程序员不是一个好码农!在上图中可以看到,Nginx作为整个架构的流量入口,可以理解为一个外部的网关,它承担着请求的路由转发、负载均衡、动静分离等功能。作为一个核心入口点,Nginx肯定要采用多节点部署,同时通过LVS+keepa
java应用部署下在生产环境,肯定是少不了监控的,比如说我们想要监控JVM的线程使用情况,内存使用情况等等。
前段时间,有同事反馈开发联调环境有个订单服务访问不了,在Eureka页面上点击服务也是链接拒绝,很奇怪,连接访问的ip是一个陌生IP,并不是订单服务部署服务器的ip,后来查看了下服务网卡信息,发现服务器上挂载了一个新网卡。而服务注册到Eureka服务端就是172.30.32.16的地址。当时这个ip实际是访问不了的,所以就出现服务注册Eureka成功,但是服务调用不了。