- @polloo2012
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要:腾讯龙虾团队开发的WorkBuddy项目采用Windows Minifilter驱动技术(C/WPF C#),1.5天完成全自动开发。该项目实现内核级透明文件加密,具备防泄露、防破解等企业级安全功能。核心是通过文件系统过滤驱动拦截处理磁盘操作,类似杀毒软件工作原理。开发中遇到5次蓝屏重启问题(0x139错误),系驱动代码与Windows CFG安全机制冲突所致。项目涉及sys驱动文件签名部署
QwenPaw-Flash是一款专为QwenPaw智能体优化的轻量级模型,具备2B/4B/9B三种参数规模。该模型通过高质量智能体轨迹数据训练,在记忆管理、文件解析、信息检索和智能引导等方面表现突出。其采用门控DeltaNet和注意力机制混合架构,支持262,144 tokens长上下文处理。基准测试显示该模型性能媲美旗舰模型但资源消耗更低,可通过llama.cpp部署并提供OpenAI兼容API
WorkBuddyCodebuddy是一款全栈智能开发工具,现已实现插件、IDE和CLI三端覆盖。它提供从设计到部署的全流程支持,包括Figma设计稿转代码、智能文档生成、后端服务集成等功能。该工具特别适合产品经理、设计师和开发者使用,具有0门槛新建项目、自然语言修改组件、任务智能拆解等特色功能,能显著提升开发效率,实现设计与开发的无缝衔接。通过预置组件库和云服务集成,帮助用户快速完成项目从构思到
QwenPaw-Flash是一款专为QwenPaw智能体优化的轻量级模型,具备2B/4B/9B三种参数规模。该模型通过高质量智能体轨迹数据训练,在记忆管理、文件解析、信息检索和智能引导等方面表现突出。其采用门控DeltaNet和注意力机制混合架构,支持262,144 tokens长上下文处理。基准测试显示该模型性能媲美旗舰模型但资源消耗更低,可通过llama.cpp部署并提供OpenAI兼容API
摘要: FP32→INT8量化是深度学习模型部署的关键技术,可缩小模型体积4倍、提升推理速度2-10倍,但需控制精度损失(<1%)。核心损失源于数值截断、舍入误差及敏感层(如检测头、Attention层)。量化方案包括: 训练后量化(PTQ):无训练,KL散度校准+对称权重量化可降低损失至1%内; 量化感知训练(QAT):接近无损(损失<0.5%),适合高精度场景。 优化方法:混合精度

安装了.net reactor之后,可以在安装目录下找到帮助文档REACTOR_HELP.chm,目前没有中文版本,里面详细介绍了.net reactor的各功能及使用场景。本系列文章是基于此帮助文档来写的。.net reactor主要有三大面板:菜单面板:- 文件就是普通的创建操作环境,打开操作环境,加载程序集等操作- 运行保护程序集 - 对当前选中的程序集执行保护操作创建许可证文件 - 根据
摘要: Google DeepMind推出的Gemma4是新一代开源大模型系列,基于Apache2.0协议,支持商用与自由修改。涵盖E2B(2.3B有效参数)、E4B(4.5B)、26B(MoE架构)和31B旗舰版,适配从手机到服务器的全硬件场景。核心亮点包括高效推理、128K-256K长上下文支持、原生多模态(文本/图像/视频/音频)及可配置思考模式。E4B为端侧平衡首选,26B MoE以26B
摘要:麦橘写实V7是由国内AI模型师开发的超写实通用模型,在CivitAI平台获得4.93分高评分和70万+下载量。该模型具有人物摄影级真实感,擅长表现皮肤质感、五官细节和光影效果,适用于人像、风景等多种创作场景。文章还提供了针对不同创作类型的负面提示词预设,包括通用质量增强、人物写实专用、二次元/动漫人物等9种预设方案,帮助优化生成效果。这些预设删除了不兼容的特殊嵌入词,提高了99%模型的兼容性
摘要: FP32→INT8量化是深度学习模型部署的关键技术,可缩小模型体积4倍、提升推理速度2-10倍,但需控制精度损失(<1%)。核心损失源于数值截断、舍入误差及敏感层(如检测头、Attention层)。量化方案包括: 训练后量化(PTQ):无训练,KL散度校准+对称权重量化可降低损失至1%内; 量化感知训练(QAT):接近无损(损失<0.5%),适合高精度场景。 优化方法:混合精度
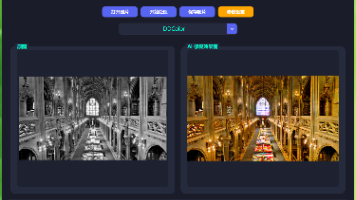
摘要:DDColor是一种基于双解码器架构的图像上色模型,在ICCV 2023会议上提出。该PyTorch官方实现能够生成逼真的彩色图像效果,通过双解码器结构实现高质量的黑白照片上色。项目代码已开源,展现了当前图像彩色化领域的前沿技术水平。