- @oscarun
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
远程开发有很多种类型,有直接线上环境的云端IDE,文件、编译、测试都可以在云端的 IDE 实现,跟本地的 IDE 差别不大,这种方案本质上就是一个 web console。另外的类型就是通过同步本地开发文件夹里的文件,至少实现文件从本地 --> 远程同步的功能,这种方案本质上就是通过 sftp 等方法,同步文件,真正的编译还是在远程做的,当然也可以在本地编译好之后直接同步上传到远程运行。本文
文章目录1 Overview2 Example3 Summary1 Overview官方文档「又长又臭」,我只是想在 Kubernetes 集群里,运行一个能跑在 GPU 显卡的程序而已,文档太多,看的眼花缭乱,本文就讲一个简单的例子。2 Example例子来源于 gihub 上的一段 code,test_single_gpu.py,核心代码很简单,就是在第一块 GPU 上做一个矩阵的运算...
大模型训练中语料是非常重要的,目前公网上有各种各样的语料可以供下载,但是不可能每个用户、每次训练任务都通过公网去拉取语料,因此我们需要在语料平台上为用户提前下载并且注册一些需要的语料,通过语料平台维护一些公用的语料。鉴于语料下载的多样性,目前下载公网上的语料一般会先把语料下载到国外的服务器,然后再上传到华为云的 obs,最后再在 IDC 环境的服务器上将 obs 的数据下载到 CephFS 的语料
下载插件的时候又莫名其妙报错了,报错信息还挺让人困惑的,failed to download,然后 response 200 OK?What the hell…? 确实挺奇怪的,看图吧。这个报错太骚了,有点猝不及防,但是既然说下载失败,那么无非就两个可能原因,要本作为 client 的我的电脑有问题,要么作为 server 的插件市场有问题。有兴趣可以试试报错时候的那个链接,本地 curl -v
大模型训练中语料是非常重要的,目前公网上有各种各样的语料可以供下载,但是不可能每个用户、每次训练任务都通过公网去拉取语料,因此我们需要在语料平台上为用户提前下载并且注册一些需要的语料,通过语料平台维护一些公用的语料。鉴于语料下载的多样性,目前下载公网上的语料一般会先把语料下载到国外的服务器,然后再上传到华为云的 obs,最后再在 IDC 环境的服务器上将 obs 的数据下载到 CephFS 的语料
大模型训练中语料是非常重要的,目前公网上有各种各样的语料可以供下载,但是不可能每个用户、每次训练任务都通过公网去拉取语料,因此我们需要在语料平台上为用户提前下载并且注册一些需要的语料,通过语料平台维护一些公用的语料。鉴于语料下载的多样性,目前下载公网上的语料一般会先把语料下载到国外的服务器,然后再上传到华为云的 obs,最后再在 IDC 环境的服务器上将 obs 的数据下载到 CephFS 的语料
大模型训练中语料是非常重要的,目前公网上有各种各样的语料可以供下载,但是不可能每个用户、每次训练任务都通过公网去拉取语料,因此我们需要在语料平台上为用户提前下载并且注册一些需要的语料,通过语料平台维护一些公用的语料。鉴于语料下载的多样性,目前下载公网上的语料一般会先把语料下载到国外的服务器,然后再上传到华为云的 obs,最后再在 IDC 环境的服务器上将 obs 的数据下载到 CephFS 的语料
公司 Ceph 集群从 v12 升级到 v14 后,今天某个 CephFS 的集群收到一个 HEALTH_WARN 的告警,具体的 Warning 的信息为 1 pools have many more objects per pg than average。很明显就是 pg 数目设置的过少,导致有些 pg 里的对象过多,估计是超过了默认的一个 Limit,所以产生了 Warning 的信息,解决
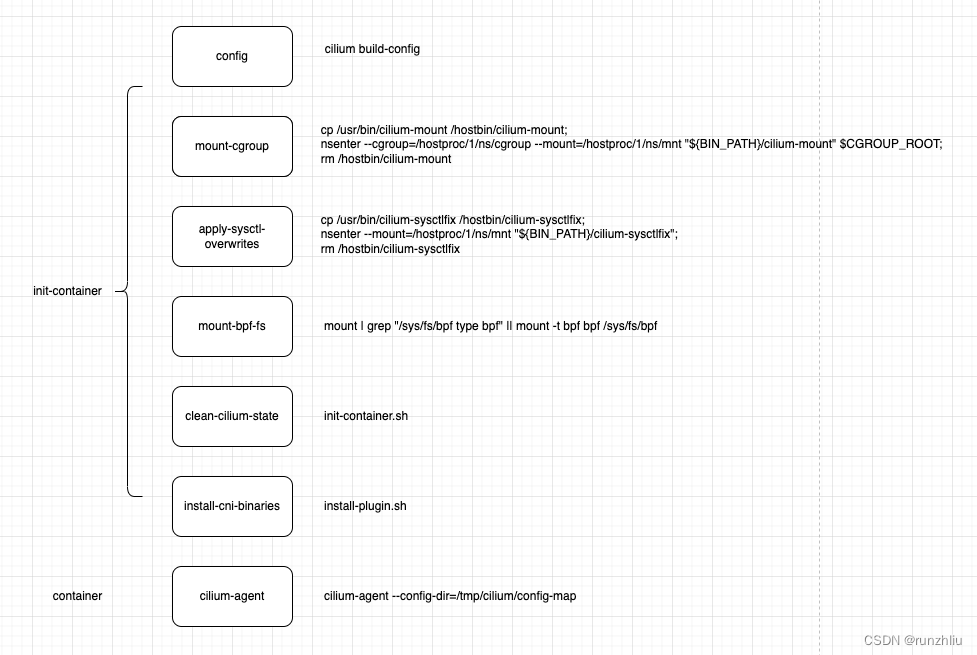
本文主要分析 cilium-agent 作为 DaemonSet 在每个节点的启动流程。根据以上的分析,可以总结一下,在 Kubernetes 集群内部的节点下,启动 cilium-agent 的二进制之前需要执行下面的脚本。# config# /hostbin是一个非常临时的目录# /hostproc相当于/proc。