




- @mystic_codes
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
是 Claude Code 的模块化功能扩展系统,相当于"一键启动的标准操作流程"。你可以把经常重复的任务(如创建新 API、编写单元测试、做代码审查)封装成 Skill,之后只需调用名称即可执行完整流程。

智谱 GLM-5.1正式发布,作为新一代大模型,它在代码生成、复杂工程调试、多语言兼容上全面升级!而 Anthropic 的 Claude Code 凭借 “本地交互 + 沙箱执行” 的优势,一直是开发者的编程神器 —— 现在两者强强联合,无需复杂配置就能快速接入,国内用户也能享受稳定体验,新手 5 分钟即可上手!

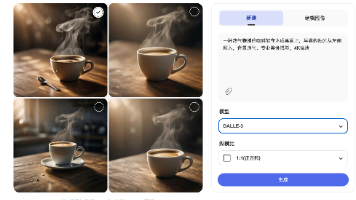
DALL·E 3 是"最听话"的模型——你说什么它就画什么,在指令遵循度上领先其他工具。
在完成第一阶段的预训练后,就可以开始进到指令微调阶段了。由于预训练任务的本质在于「续写」,而「续写」的方式并一定能够很好的回答用户的问题。因为训练大多来自互联网中的数据,我们无法保证数据中只存在存在规范的「一问一答」格式,这就会造成预训练模型通常无法直接给出人们想要的答案。不过,这种需要用户精心设计从而去「套」答案的方式,显然没有那么优雅。既然模型知道这些知识,只是不符合我们人类的对话习惯,那么我


OpenClaw(因图标是红色龙虾,在国内被形象地称为“”),是一个简单来说,以往我们用 ChatGPT 或 DeepSeek,它们更像一个“顾问”,给你提供思路或代码,但实际工作还得自己做。而 OpenClaw 则是一个,你只需要用自然语言给它下命令,它就能。

在获得了一个 Reward Model 后,我们便可以利用这个 RM 来进化我们的模型。目前比较主流的优化方式有 3 种:BON,DPO 和 PPO。

当我们在做完 SFT 后,我们大概率已经能得到一个还不错的模型。但我们回想一下 SFT 的整个过程:我们一直都在告诉模型什么是「好」的数据,却没有给出「不好」的数据。我们更倾向于 SFT 的目的只是将 Pretrained Model 中的知识给引导出来的一种手段,而在SFT 数据有限的情况下,我们对模型的「引导能力」就是有限的。这将导致预训练模型中原先「错误」或「有害」的知识没能在 SFT 数据

在完成第一阶段的预训练后,就可以开始进到指令微调阶段了。由于预训练任务的本质在于「续写」,而「续写」的方式并一定能够很好的回答用户的问题。因为训练大多来自互联网中的数据,我们无法保证数据中只存在存在规范的「一问一答」格式,这就会造成预训练模型通常无法直接给出人们想要的答案。不过,这种需要用户精心设计从而去「套」答案的方式,显然没有那么优雅。既然模型知道这些知识,只是不符合我们人类的对话习惯,那么我
当前,不少工作选择在一个较强的基座模型上进行微调,且通常效果不错(如:[]、[] 等)。这种成功的前提在于:预训练模型和下游任务的差距不大,预训练模型中通常已经包含微调任务中所需要的知识。2.当我们需要一个专业领域的 LLM 时,预训练模型中的知识就尤为重要。由于大多数预训练模型都是在通用训练语料上进行学习,对于一些特殊领域(金融、法律等)中的概念和名词无法具备很好的理解。我们通常需要在训练语料中
