- @myj2343
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
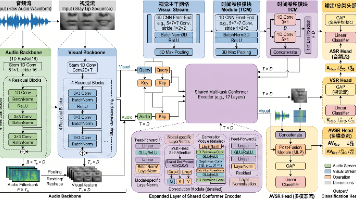
AVSR 视觉语音识别任务(唇读)存在准确率低、标注数据稀缺的问题,现有研究方向中常见的自监督方法还存在计算成本高、真实场景泛化差的缺陷。唇读数据太少,必须靠复杂的自监督预训练才能做好。音频和视觉是完全不同的模态,必须用两个独立的编码器分别处理。多任务学习一定要精心设计不同任务的损失权重。唇读模型必须外挂一个大语言模型才能用。针对这些认知,文章提出了纯监督多任务统一框架MultiAVSR,研究探讨
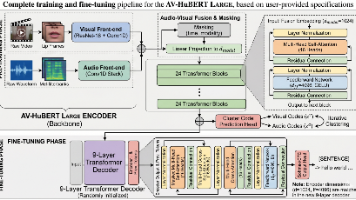
论文标题:Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction作者同样来自Meta AI与TTIC(丰田芝加哥理工),核心团队正是打造 wav2vec 2.0、HuBERT、AV-HuBERT 的语音自监督顶尖团队。对于做唇语识别(Lip Reading)、视听语音表征学习的同学,这篇
论文标题:Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction作者同样来自Meta AI与TTIC(丰田芝加哥理工),核心团队正是打造 wav2vec 2.0、HuBERT、AV-HuBERT 的语音自监督顶尖团队。对于做唇语识别(Lip Reading)、视听语音表征学习的同学,这篇
在基于音频的automatic speech recognition (ASR)自动语音识别任务中,模型在环境噪音的影响下识别率会显著下降,其中尤其容易受到他人语音干扰的影响,因为模型不好判断说话人是谁。Audio-visual speech recognition (AVSR)即视听语音识别系统,通过引入视觉模态的信息,利用视觉对语音噪音影响的不变性,来增强模型对语音识别任务中抗干扰能力的提升,