- @maligebilaowang
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
【摘要】本文提供数学建模竞赛专业指导服务,团队由8年经验、获奖率100%的专家及硕博一等奖得主组成。针对数据仿真、刚体动力学、动态规划及随机模拟等赛题,提供完整解决方案(含代码、论文、数据)。资源链接已附,适用于需要技术支持或想提升竞赛成绩的参赛者。
TF-IDF 采用文本逆频率 IDF 对 TF 值加权取权值大的作为关键词,但 IDF 的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能,所以 TF-IDF 算法的精度并不是很高,尤其是当文本集已经分类的情况下。经过一次聚类后,需要重新计算簇中心,然后计算距离重新划分数据点所属簇,过程中可能会出现原不属于该簇的数据被划分到了簇中,此次聚类可以看作对上一

2020年以来,我国人口在数量、素质、结构、分布以及居住等方面发生了明显变化。中国人口区域分布具有显著差异性,与自然环境、经济水平、产业结构、教育程度、性别结构等指标密切相关。问题1是基础,其分类结果贯穿后续所有问题。问题3的模型是问题4政策模拟的载体。
本题相对来说比较适合新手,包括针对数据的预处理,数据分析,特征提取以及模型训练等多个步骤,完整的做下来是可以学到很多东西的。
2026五一数学建模C题边坡预警问题摘要 本题聚焦边坡形变监测与预警建模,包含5个递进子问题: 数据校正:采用多项式回归对光纤位移计数据进行校准,通过交叉验证确定最优阶数(1-5阶),评估RMSE等指标。 形变阶段识别:基于滑动窗口速度分析和Pelt算法检测三阶段转换节点,建立分段模型(线性/二次/指数)计算各阶段平均位移速度。 多变量预处理: 中值滤波去噪与样条插值补齐缺失值 3σ+IQR双重机
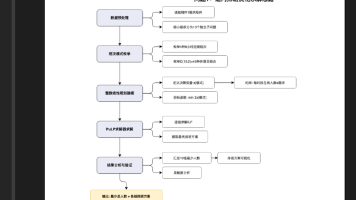
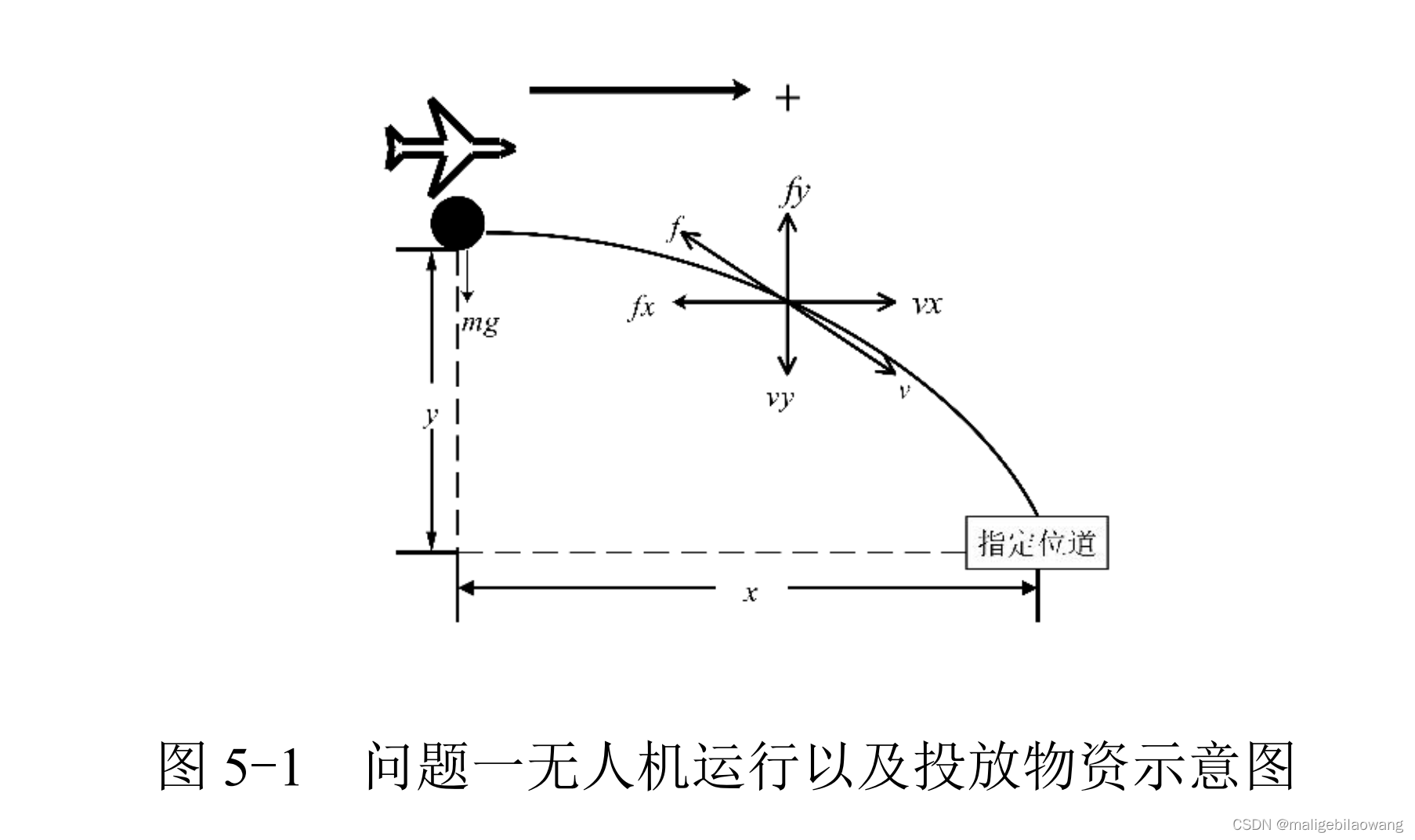
2.3.1本题通过查找俯仰角、滚转角、偏航角与飞机稳定性的关系表达式,以及不同 种类无人机的重量,通过流体力学的知识,找出相同重量下不同海拔的雷诺数来分 析出其对飞机稳定性的影响,再通过写出发射点到目标位置的表达式来刻画出命中 精度与飞行高度、飞行速度、俯冲角等的关系,通过控制变量法,改变其中某一个 参数的数值,来比较这些因素的重要程度,再赋值权重,从而写出影响稳定性的表 达式。相反时,速度为两者
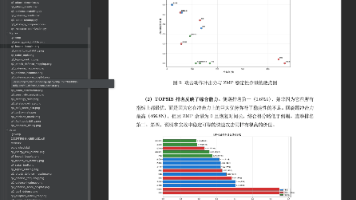
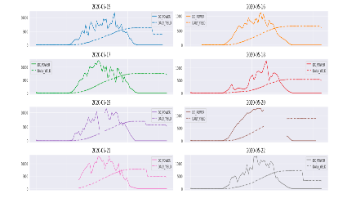
本文基于印度某光伏电站全年发电数据,研究光伏发电功率特性及预测方法。首先通过数据预处理修正坏数据,分析发电功率随时间变化趋势及季节性特征。然后建立两种预测模型:时间序列法和动态神经网络法。时间序列法计算量小但自适应能力差,而动态神经网络通过反馈机制能更好处理非线性时变特征。实验表明神经网络预测效果更优。研究为光伏发电功率预测提供了有效解决方案,成果包含完整数据、论文和代码实现。
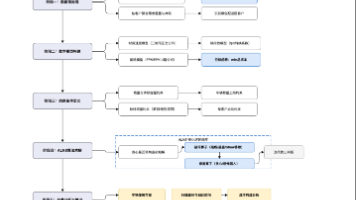
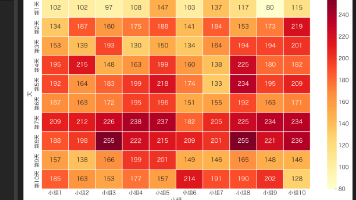
本文针对2026年五一杯数学建模竞赛A题"煤矿巷道支护问题"进行了系统解析。赛题围绕锚杆支护中预紧力矩与预紧力的转换机制展开,包含四个递进问题:1)建立标准/实测条件下的T-P关系模型;2)考虑三种工程约束的最大预紧力矩建模;3)偏心受力条件下的模型修正;4)基于围岩等级的优化模型。解题方案融合了线性回归、Chow结构突变检验、多约束优化等数学方法,并结合了材料力学、岩土工程等
可能需要用监督学习的方法,比如逻辑回归、随机森林、梯度提升树等,将用户的历史行为作为特征,预测他们是否会在当天关注某个博主。问题2的结果要填写每个指定用户在7月22日新关注的博主ID,所以可能需要为每个用户生成一个概率分布,然后选择概率最高的几个博主作为预测结果。问题3要求预测指定用户在7月21日是否在线,如果在线的话,预测他们可能与哪些博主产生互动,并给出互动数最高的三个博主。

摘要:2026年华中杯A题聚焦城市绿色物流配送调度问题,要求为"绿色物流"公司设计兼顾客户满意度、运营成本和环保要求的车辆调度方案。研究涉及98个客户点、2139个订单和5种车型(燃油/新能源)。针对三个子问题,提出MIP建模+ALNS求解的组合方案,分析时变速度、能耗U型曲线等复杂因素,特别处理绿色配送区限行政策(8:00-16:00仅新能源车)和动态事件响应。论文结构预计2