




- @m0_68676142
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本周首先学习了M-P模型的基本原理,包括神经元激活的条件和数学形式,并探讨了阈值的确定方法。接着,文章讲解了损失函数(如均方误差和交叉熵)在机器学习中的作用及其计算方式。最后,本文深入探讨了集成学习的基本思想、分类器组合策略以及主要方法(如Boosting和Bagging),并分析了集成学习相对于个体学习在性能上的优势。本周全面学习了M-P模型的工作机制及其阈值调整方法,并详细解释了常见损失函数的

本周探讨了无监督学习中的几种关键方法,包括高斯混合模型(GMM)、聚类算法(如K-Means和Mean Shift)以及受限玻尔兹曼机(RBM)。高斯混合模型利用概率模型来拟合数据,并通过可视化展示了其对二维数据集的预测轮廓。聚类部分涵盖了多种算法的性能和局限性,如K-Means和Mean Shift,并提供了具体示例。最后,还介绍了受限玻尔兹曼机的工作原理及其在特征学习中的应用。
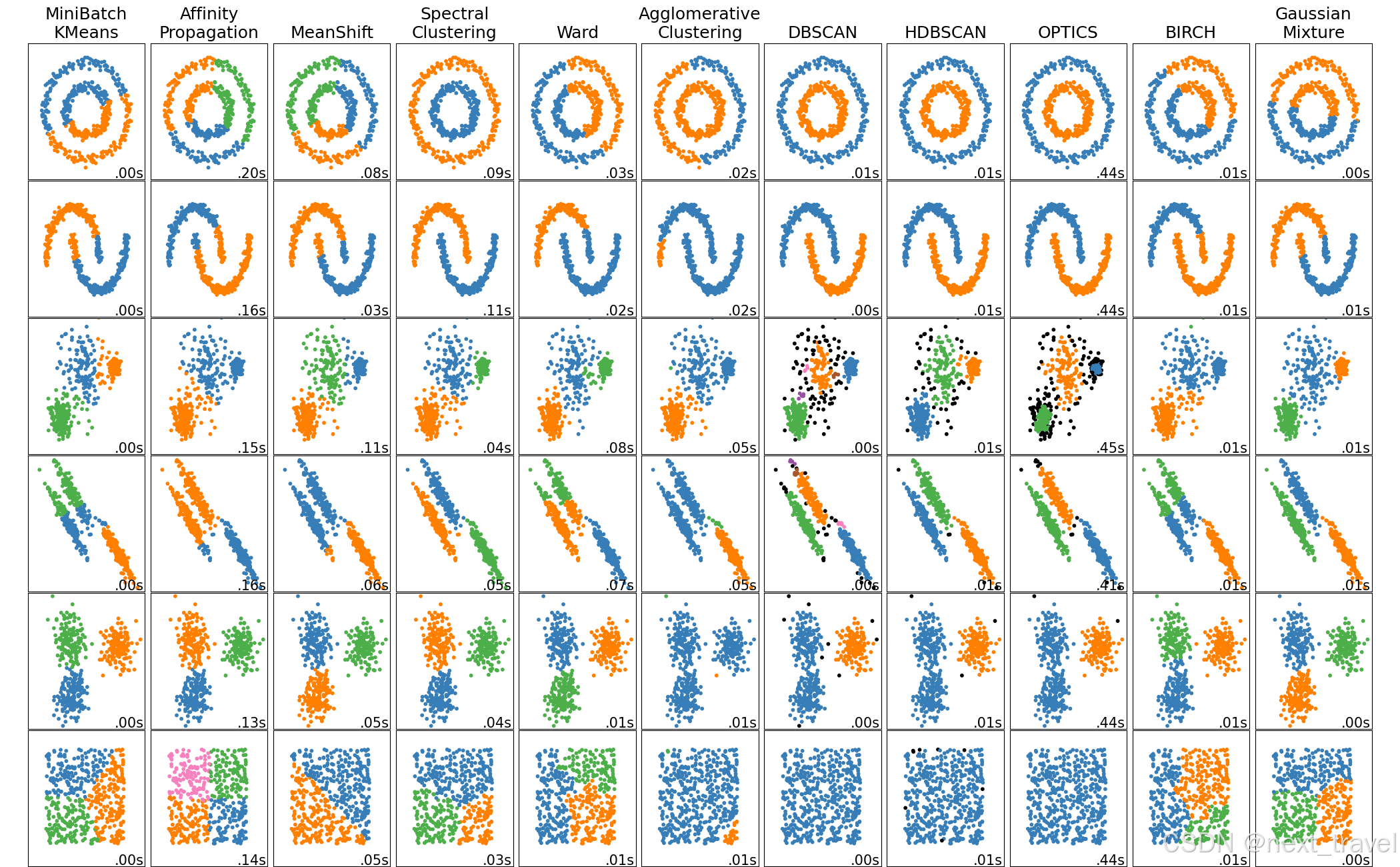
聚类是无监督学习中的重要任务,旨在将数据集划分为若干个子集(簇),使得同一簇内的样本相似度高而不同簇间的样本相似度低。本周学习了聚类的性能度量指标,包括内部和外部指标,如Jaccard系数、Rand指数、DB指数等,并介绍了几种常见的距离计算方法。此外,深入学习了几种原型聚类算法:k均值、学习向量量化(LVQ)以及高斯混合模型(GMM),并以K-means算法为例,通过鸢尾花数据集进行了实战演示。

DETR(DEtection TRansformer)是由Facebook AI提出的一种基于Transformer架构的端到端目标检测方法。它通过将目标检测建模为集合预测问题,摒弃了锚框设计和非极大值抑制(NMS)等复杂后处理步骤。DETR使用卷积神经网络提取图像特征,并将其通过位置编码转换为输入序列,送入Transformer的Encoder-Decoder结构。Decoder通过固定数量的目

目标检测算法从早期的暴力穷举逐步发展到基于深度学习的高效框架,如RCNN和SPPNet。RCNN通过候选区域和CNN结合,大幅提高了检测精度,但其多阶段训练过程复杂,耗时且占用大量磁盘空间。SPPNet的出现利用SPP层实现CNN层共享,显著提升了训练效率,启发了后续的Fast R-CNN等方法。然而,SPPNet仍需多阶段训练,效率提升有限。

DETR(DEtection TRansformer)是由Facebook AI提出的一种基于Transformer架构的端到端目标检测方法。它通过将目标检测建模为集合预测问题,摒弃了锚框设计和非极大值抑制(NMS)等复杂后处理步骤。DETR使用卷积神经网络提取图像特征,并将其通过位置编码转换为输入序列,送入Transformer的Encoder-Decoder结构。Decoder通过固定数量的目
聚类是无监督学习中的重要任务,旨在将数据集划分为若干个子集(簇),使得同一簇内的样本相似度高而不同簇间的样本相似度低。本周学习了聚类的性能度量指标,包括内部和外部指标,如Jaccard系数、Rand指数、DB指数等,并介绍了几种常见的距离计算方法。此外,深入学习了几种原型聚类算法:k均值、学习向量量化(LVQ)以及高斯混合模型(GMM),并以K-means算法为例,通过鸢尾花数据集进行了实战演示。
本周探讨了无监督学习中的几种关键方法,包括高斯混合模型(GMM)、聚类算法(如K-Means和Mean Shift)以及受限玻尔兹曼机(RBM)。高斯混合模型利用概率模型来拟合数据,并通过可视化展示了其对二维数据集的预测轮廓。聚类部分涵盖了多种算法的性能和局限性,如K-Means和Mean Shift,并提供了具体示例。最后,还介绍了受限玻尔兹曼机的工作原理及其在特征学习中的应用。
本周学习的ControlNet 是一种用于文本到图像扩散模型(如 Stable Diffusion)的条件控制方法。它通过冻结预训练的扩散模型,并创建一个可训练的副本,使其能够学习额外的条件信息。关键技术包括零卷积(Zero Convolutions),用于确保模型训练初期不影响原始网络,同时逐步引入控制信息。ControlNet 可以接受多种条件输入(如 Canny 边缘检测),并在保持高质量图

目标检测算法从早期的暴力穷举逐步发展到基于深度学习的高效框架,如RCNN和SPPNet。RCNN通过候选区域和CNN结合,大幅提高了检测精度,但其多阶段训练过程复杂,耗时且占用大量磁盘空间。SPPNet的出现利用SPP层实现CNN层共享,显著提升了训练效率,启发了后续的Fast R-CNN等方法。然而,SPPNet仍需多阶段训练,效率提升有限。