




- @m0_66858441
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
机器人评测体系正成为具身智能领域的关键发展方向,其框架包含五个层级:任务→能力→场景→指标→数据。核心任务评测检验机器人完成抓取、搬运等具体操作的完成度;能力评测涵盖感知、推理等六大维度;环境评测关注从实验室到真实场景的适应性;指标层则定义成功率、能耗等量化标准。随着VLA(视觉-语言-动作)机器人的兴起,评测新增多模态理解、长期记忆等维度。完整的评测流程需经过任务定义、场景构建、自动化测试、错误
摘要 Agent RAG(智能体检索增强生成)技术通过将大语言模型(LLM)的生成能力与自主智能体相结合,实现动态知识检索、多轮决策和上下文优化。报告系统介绍了Agent RAG的核心架构(检索器、向量数据库、智能体决策模块等)、典型工作流程(查询分析→检索→评估→生成→校验)及主流工具链(LangChain、LlamaIndex等)。重点分析了智能体如何实现多步任务分解、检索策略优化和反馈迭代,
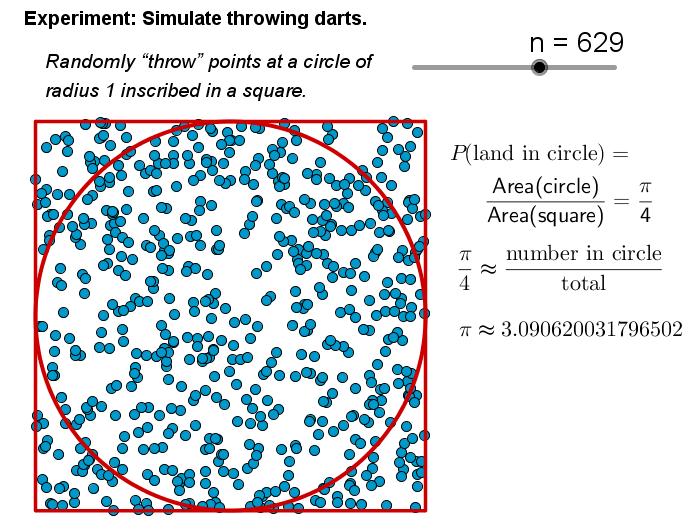
摘要:马尔可夫链是一种未来状态仅依赖当前状态的随机过程(马尔可夫性质),例如天气预测。蒙特卡罗方法通过大量随机试验逼近复杂问题的解(如计算圆周率)。MCMC(马尔可夫链蒙特卡罗)结合两者,利用马尔可夫链设计采样过程,使样本逐渐收敛到目标概率分布(如Metropolis-Hastings算法)。它在贝叶斯推断中尤为重要,可绕过复杂计算直接采样后验分布,广泛应用于机器学习、统计建模等领域,是处理高维概
摘要 Agent RAG(智能体检索增强生成)技术通过将大语言模型(LLM)的生成能力与自主智能体相结合,实现动态知识检索、多轮决策和上下文优化。报告系统介绍了Agent RAG的核心架构(检索器、向量数据库、智能体决策模块等)、典型工作流程(查询分析→检索→评估→生成→校验)及主流工具链(LangChain、LlamaIndex等)。重点分析了智能体如何实现多步任务分解、检索策略优化和反馈迭代,
Agent Evals 本质是:在真实任务环境中,衡量智能体完成任务、规划行动、使用工具、稳定运行和安全行为的能力。
OpenClaw内置Headless Chrome,通过 Chrome DevTools Protocol (CDP) 实现点击、输入、滚动、截图、抓取DOM,能力包括自动填表、自动登录、自动抓数据、自动操作网站。保存用户信息、任务结果、经验总结;OpenClaw默认四个核心工具:read、write、edit、bash,即读文件、写文件、编辑代码、执行命令;每个 Agent 有独立配置:agen
摘要: 本文探讨了AI智能体评估的挑战与方法。智能体的自主性和灵活性使其评估变得复杂,但有效的评估能提前暴露问题,提升产品信心。评估方法包括单轮与多轮测试,结合代码、模型和人工评分,针对不同智能体类型(如编程、对话、研究)设计特定评估策略。关键步骤包括定义明确任务、构建平衡问题集、设计稳健评估框架,并结合多种评分方式。评估应贯穿智能体开发全周期,早期投入可加速迭代,避免后期被动修复。文章还介绍了评
系统级智能体(Agentic AI)是基于大模型的自主智能代理,能够主动规划、分解和执行复杂任务。其核心架构包括推理引擎、内存机制、调度模块和执行者等组件,通过多智能体协作实现任务处理。相比传统工具链,系统级智能体具备自主性、协同能力和长期记忆等优势,已应用于自动化编程、数据分析等领域。代表性系统包括Auto-GPT、BabyAGI等,采用不同协作策略。尽管面临稳定性、安全性等挑战,但未来将向人机
ClaudeCode是Anthropic推出的智能编程代理工具,通过整合大语言模型与工具调用能力实现自动化编程。其核心架构包含五层:用户指令→Claude模型推理→代理决策→工具调用→执行反馈,形成闭环循环。关键技术包括:LLM决策引擎、结构化工具调用(文件读写/终端执行等)、多轮代理循环、智能上下文管理(压缩历史/工作记忆)以及沙箱执行环境。与普通聊天模型相比,ClaudeCode具备文件操作、
OpenClaw是一个开源的 AI 代理系统,本质上是一个可以“替你执行任务”的 AI,而不仅仅是回答问题的聊天机器人,它的特点包括:(维基百科自动执行任务:可以管理邮件、日历、浏览网页、运行脚本、处理文件等,而不需要每一步都手动确认。本地运行(自托管):软件运行在自己的电脑或服务器上(macOS、Windows、Linux 都支持),而不是在云端服务器完全控制。集成聊天平台:可通过 WhatsA