




- @m0_65253196
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
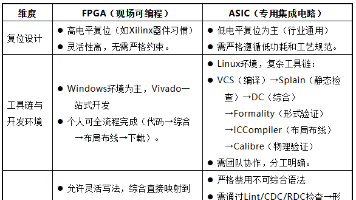
并通过离散门电路实现;FPGA问世后,逻辑电路(包括MUX)可以通过LUT直接实现,LUT的本质是将真值表映射到。,它继承了真值表的逻辑设计思想,但通过可编程存储单元实现了更灵活、高效的逻辑实现方式。A、B、C各有0和1两种输入,因此A、B、C组合共有2的三次方=8种输入。当选择信号S=0时,输出Y=A;当S=1时,输出Y=B。方法2:将真值表映射到可编程存储单元中(FPGA思想)那么FPGA中的
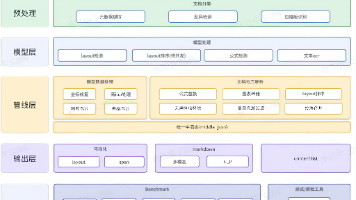
在RAG应用中,MinerU能够将复杂PDF文档转换为结构化数据,为大模型提供高质量的检索材料。例如,将学术论文中的公式、表格和图表提取为LaTeX、HTML和Markdown格式,便于大模型理解文档内容并生成高质量的回答;在Deep Research中需要处理大量复杂文档,提取关键信息并进行分析。MinerU能够自动识别文档中的多模态内容,包括文本、公式、表格和图片等,并将它们转换为机器可读的格
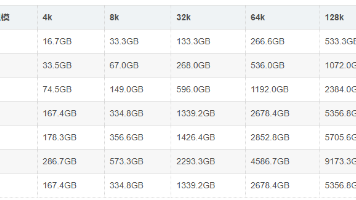
LLM推理阶段的显存需求主要由三部分组成:模型权重、KV缓存和额外开销。以LLaMA-2-13B模型为例,FP16精度下26GB存储权重,10并发4096token场景下KV缓存约33.55GB,加上10%额外开销总计约65.5GB。不同规模模型显存需求差异显著,如671B模型在4k序列长度下需167.4GB。实际部署可通过分片加载、KV缓存压缩、量化等技术优化。训练阶段需求更大,13B模型训练需
LLaMa-Factory的LoRA微调采用模块化架构实现:首先解析配置参数(秩、alpha值等),加载基础模型后通过init_adapter函数动态注入LoRA层;该方法调用_setup_lora_tuning自动检测目标线性层(如q_proj/v_proj),创建LoraConfig并转换为PeftModel;训练阶段可选配优化增强技术(如LoRA+分层学习率),在监督微调(SFT)执行器中完

在RAG应用中,MinerU能够将复杂PDF文档转换为结构化数据,为大模型提供高质量的检索材料。例如,将学术论文中的公式、表格和图表提取为LaTeX、HTML和Markdown格式,便于大模型理解文档内容并生成高质量的回答;在Deep Research中需要处理大量复杂文档,提取关键信息并进行分析。MinerU能够自动识别文档中的多模态内容,包括文本、公式、表格和图片等,并将它们转换为机器可读的格
在RAG应用中,MinerU能够将复杂PDF文档转换为结构化数据,为大模型提供高质量的检索材料。例如,将学术论文中的公式、表格和图表提取为LaTeX、HTML和Markdown格式,便于大模型理解文档内容并生成高质量的回答;在Deep Research中需要处理大量复杂文档,提取关键信息并进行分析。MinerU能够自动识别文档中的多模态内容,包括文本、公式、表格和图片等,并将它们转换为机器可读的格
LLM推理阶段的显存需求主要由三部分组成:模型权重、KV缓存和额外开销。以LLaMA-2-13B模型为例,FP16精度下26GB存储权重,10并发4096token场景下KV缓存约33.55GB,加上10%额外开销总计约65.5GB。不同规模模型显存需求差异显著,如671B模型在4k序列长度下需167.4GB。实际部署可通过分片加载、KV缓存压缩、量化等技术优化。训练阶段需求更大,13B模型训练需