




- @m0_50889382
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Terraform 管理基础设施资源:GPU 节点、网络、负载均衡、存储——这些资源的生命周期是创建-更新-销毁,天然适合声明式语言描述。Ansible 管理操作系统和中间件配置:驱动版本、内核参数、运行时配置——这些是多步骤的过程式任务,需要幂等性和可重复执行。交接面需要工程化设计:动态 Inventory、健康检查等待、失败节点的状态回传——这三个组件不比基础设施本身简单,值得投入工程资源打磨
基础镜像标准化的核心价值:安全漏洞修复从"排查 11 种镜像"变为"修复 1 个基础镜像 + 全量滚动更新",时间从天降级到小时。实现方式是通过 CI 门禁强制约束FROM镜像来源、通过分层治理让不同团队各自负责不同层的变更、通过兼容性测试保障每次升级不引入推理输出偏差。落地建议:先把所有服务的 Dockerfile 中操作系统基础镜像收敛到一个固定版本(Ubuntu 22.04),这一步的阻力最
网络平面分离的核心收益:南北向和东西向流量互不干扰,推理链路的 P99 延迟保持稳定,不受外部流量波动影响。技术选型上,入口层使用 Envoy Gateway 处理南北向流量,服务间使用 Cilium eBPF 处理东西向流量。落地建议:从 NetworkPolicy 白名单模式起步,先收敛东西向的安全边界——即便暂时合并网络平面,也要把服务间的访问控制做到位。然后再根据实际的性能数据和集群规模判
总的来说,飞算 JavaAI 像是给了我一个极速的脚手架搭建工具——能快速搭出一个结构完整的 Web 应用,但真正的"可用性"落在业务逻辑的精调、视觉风格的打磨和异常流程的处理上。完整系统包含登录注册、工作台、设备管理、租赁订单、归还检查、维修记录、客户管理、租赁日历和数据报表 9 个功能模块,覆盖了从设备入库到归还维修的全链路。设备的五段状态切换、订单的 CRUD 和筛选、日历视图的日期计算——
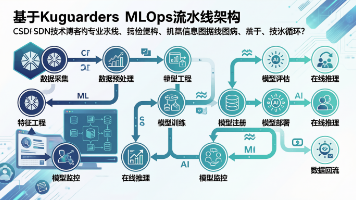
metadata:spec:templates:dag:tasks:container:container:resources:limits:import kfp云原生 MLOps 就像是为 AI 模型打造的一条自动化生产线。从数据输入到模型部署,每个环节都经过精心设计和优化。希望今天的分享能帮助你构建高效、可靠的 AI 基础设施。如果你在实践中遇到什么问题,欢迎在评论区留言讨论。好了,Ping
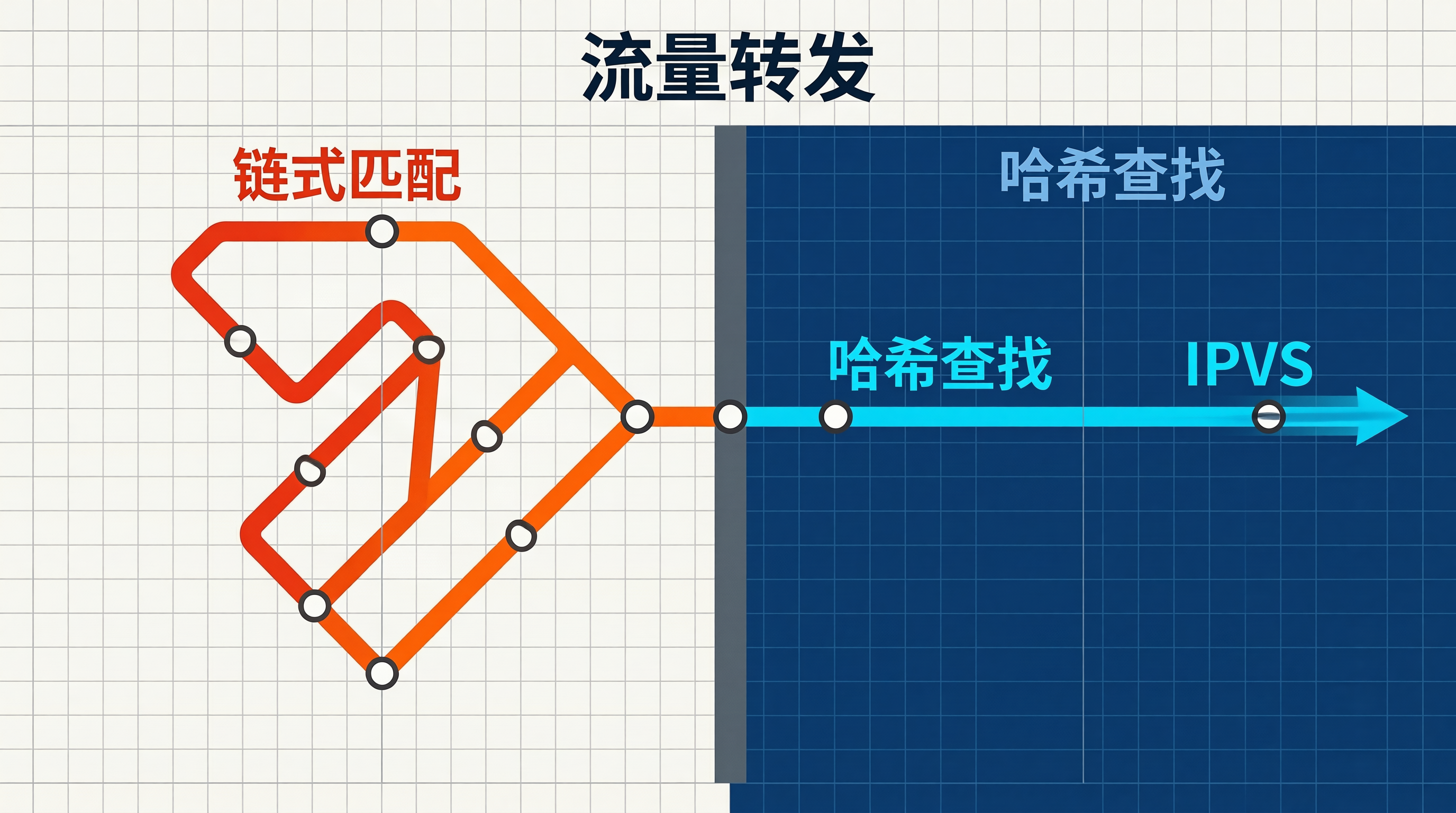
回到开头的场景,我们把集群切换到 IPVS 模式后,又配合做了同节点优先转发,节点间的流量分布曲线肉眼可见地变得均匀了。之前那个 CPU 偏高节点的负载直接降了 35%。iptables 的线性匹配在大规模集群中会成为瓶颈,而 IPVS 的哈希查找将时间复杂度从 O(n) 降到了 O(1)IPVS 在 K8s 中使用 NAT 模式,通过修改目标 IP 做流量转发,响应流量也经过 LVS 节点返回支
Readiness Probe 参数不合理远小于服务启动时间 12s,导致新 Pod 刚启动就被标记就绪,实际上还没准备好缺少 PreStop Hook:SIGTERM 发出后应用来不及处理已有请求,连接被硬中断未配置 PDB:节点升级时 3 个 Pod 同时被驱逐,服务完全不可用使用 iptables 模式:Endpoint 同步延迟 + 全量规则刷新,加剧了流量漂移问题优化项配置建议解决的核心
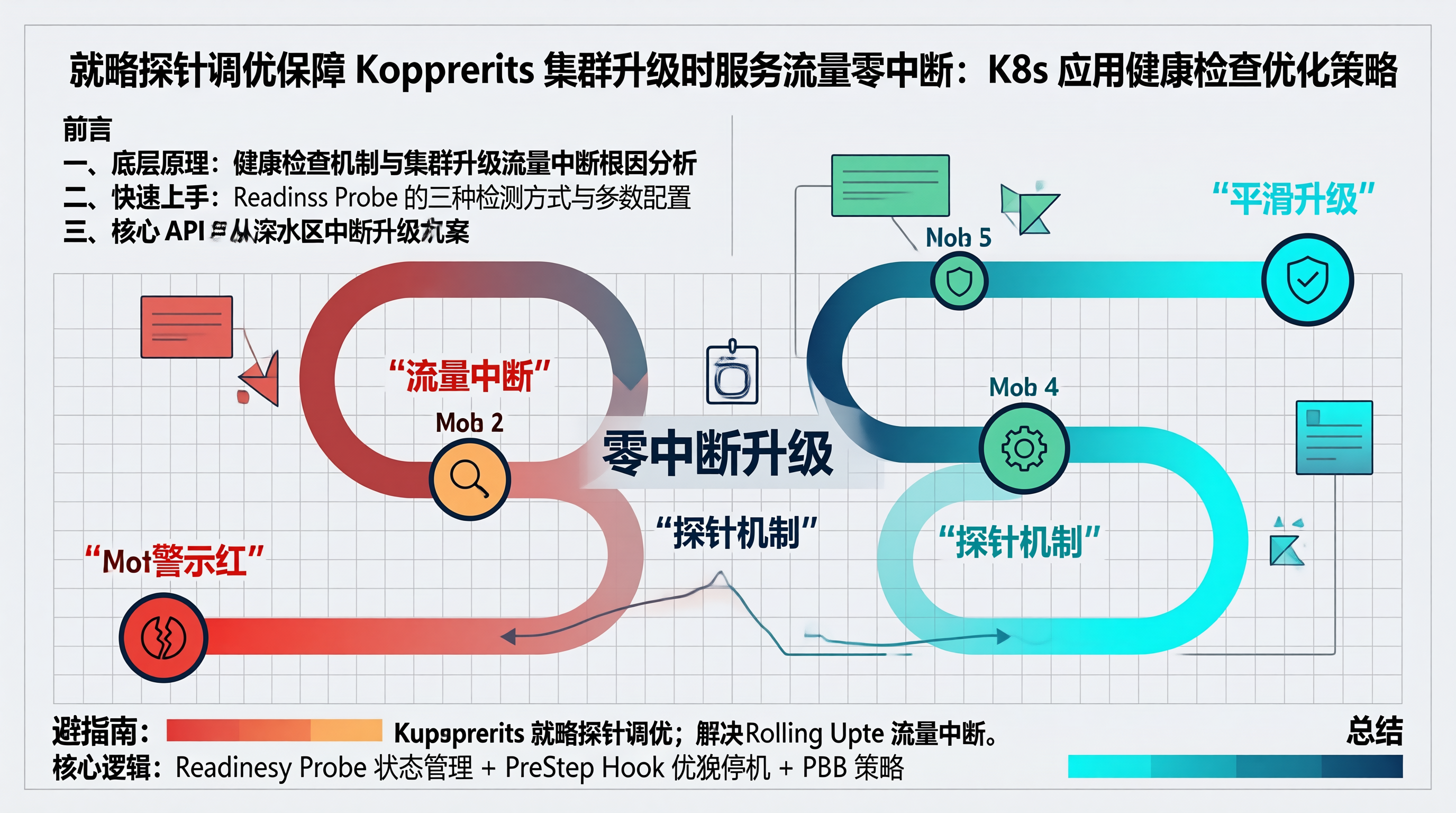
if!return 0就绪探针与 IPVS 健康检查的同步- 确保只有健康 Pod 接收流量动态权重调整策略- 根据实际负载实时调整分发比例TopologySpreadConstraints 配置- 实现跨节点的均匀分布调度算法选择- 根据业务场景选择合适的算法。
Go 的逃逸分析是编译器提供的隐式优化,理解其规则并在热点路径上主动控制逃逸行为,是降低 GC 压力、稳定 P99 延迟的关键手段。核心优化策略包括:值接收者替代指针接收者、预分配切片容量、sync.Pool 复用临时对象、以及根据堆大小动态调整 GOGC。落地路径建议:首先通过识别热点函数中的逃逸点;其次对排名前 5 的逃逸热点逐个优化,优先选择收益最大的改动;最后建立 GC 指标基线,持续监控
import ("context""fmt"// Score 根据 GPU 碎片率和亲和性对节点打分if err!= nil {return 0, framework.NewStatus(framework.Error, fmt.Sprintf("获取节点信息失败: %v", err))return 0, framework.NewStatus(framework.Error, "节点对象为空")
