




- @m0_47588836
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
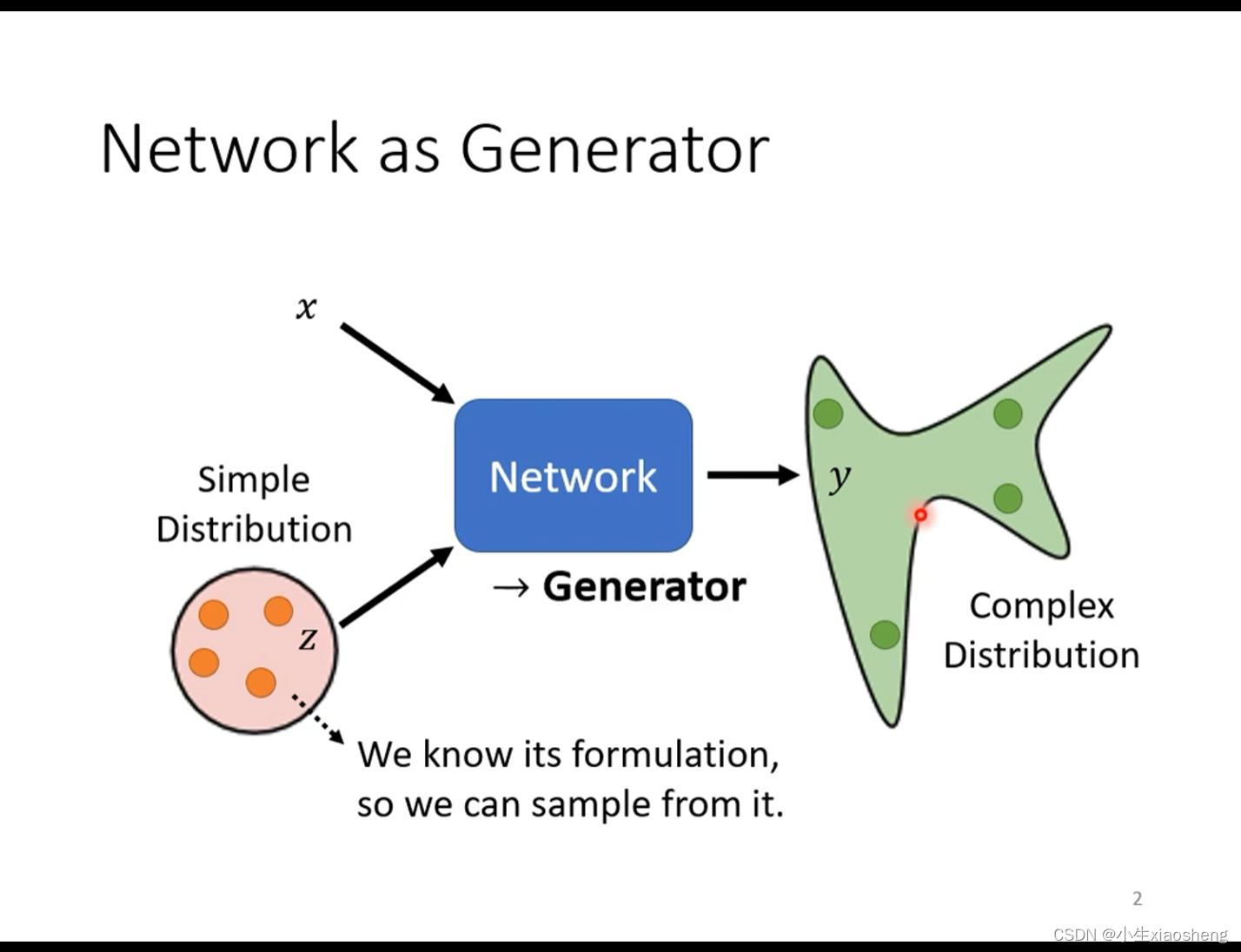
目前最好的可能是SNGAN来训练。第一代的generator的参数是随机的,输出的可能不是我们想要的结果,然后第一代的discrimination就是要分辨由generator产生的输出和正真的图片存在的不同,发现discrimination的结果不是我们要的,第二代的generator就调整参数再生成新的结果(已经满足第一代的要求了),但是第二代的discrimination也会进行分辨第二代生
self-supervised learning里面有一些模型这些模型都是巨大的模型,这次就来以bert模型为例子来讲解self-supervised。我们之前学习的模型都是supervised,就是通过输入标注数据给我们设计的模型,然后得到想要的输出结果,而self-supervised就是让数据自己想办法给自己打上标注==》把数据分为两部分,一部分输入到模型里面得到输出,一部分作为模型的标注,

RL其实和machine Learning很像,也是三个步骤。机器学习就是找一个函数,RL也是找一个函数,这个函数里面有两个变量-行为(Actor)和环境(Environment),两者进行互动。机器学习的三个步骤是:1.找出定义函数中的所有未知数;2.定义loss函数来训练数据;3.找到未知数参数从而得到最小的loss。而RL和这三个步骤是一样的。

目前最好的可能是SNGAN来训练。第一代的generator的参数是随机的,输出的可能不是我们想要的结果,然后第一代的discrimination就是要分辨由generator产生的输出和正真的图片存在的不同,发现discrimination的结果不是我们要的,第二代的generator就调整参数再生成新的结果(已经满足第一代的要求了),但是第二代的discrimination也会进行分辨第二代生
目前最好的可能是SNGAN来训练。第一代的generator的参数是随机的,输出的可能不是我们想要的结果,然后第一代的discrimination就是要分辨由generator产生的输出和正真的图片存在的不同,发现discrimination的结果不是我们要的,第二代的generator就调整参数再生成新的结果(已经满足第一代的要求了),但是第二代的discrimination也会进行分辨第二代生