




- @m0_46221545
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
随着深度学习的发展,强化学习在复杂决策问题中的应用逐渐扩展到连续控制领域。然而,传统的值函数方法(如 DQN)主要适用于离散动作空间,在机器人控制、自动驾驶、机械臂操作等连续动作场景中难以直接应用。为了解决这一问题,Deep Deterministic Policy Gradient(DDPG)算法被提出,用于处理高维、连续动作空间下的强化学习问题。
在机器人学习中,能通过可视化手段定位到“数据抖动”和“动作犹豫”,就已经跨过了最难的一道坎。当同一个视觉位置对应多个方向的修正动作时,模型会因“多峰分布”而产生困惑(Regression Averaging),最终表现为“抓不准”。判断:对于基于 Transformer 的 ACT 来说,10 组只能实现对特定轨迹的“硬背”,一旦物体位置偏移 1 厘米,模型大概率会失败。在具身智能领域,10 组高
在机器人学习中,能通过可视化手段定位到“数据抖动”和“动作犹豫”,就已经跨过了最难的一道坎。当同一个视觉位置对应多个方向的修正动作时,模型会因“多峰分布”而产生困惑(Regression Averaging),最终表现为“抓不准”。判断:对于基于 Transformer 的 ACT 来说,10 组只能实现对特定轨迹的“硬背”,一旦物体位置偏移 1 厘米,模型大概率会失败。在具身智能领域,10 组高
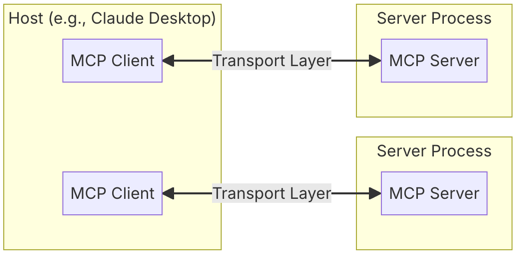
MCP(Model Connectivity Protocol) 是连接 AI 助手与数据系统的新一代开放标准,旨在打破数据孤岛,让前沿模型能够更高效地访问内容存储库、业务工具和开发环境中的数据,从而生成更精准、更相关的响应。当前,尽管 AI 助手的推理能力和生成质量快速提升,但其潜力仍受限于数据隔离问题——关键信息往往分散在孤立的遗留系统和封闭平台中。每接入一个新数据源,都需要定制化开发,导致扩
这篇内容纪念我这几个月来复现surrol论文遇到的困难在六自由度主从控制系统中,主手(Master Device)用于采集操作者的运动数据,并将其映射到从手(Slave Device)以实现精确控制。在强化学习(Reinforcement Learning, RL)框架下,主手可以作为数据采集器,记录位置、姿态、角度等信息,用于训练智能体(Agent)完成特定的控制任务。其语言代码是c++代码我们

例如: python Copy code my_list = [1, 2, 2, 3, 4, 2, 5] count_of_2 = my_list.count(2) print(count_of_2) # 输出:3 这段代码统计了列表 my_list 中元素 2 的出现次数,结果是 3。" count_of_o = my_string.count("o") print(count_of_o) #

是一种用于人脸识别的深度学习算法,它结合了传统的特征提取方法和现代的深度学习技术,旨在提高人脸识别的准确性和效率。
是用于导入 Hugging Face Transformers 库中的类。这个类是所有预训练模型的基类,提供了许多通用功能和方法,适用于不同类型的模型(如BERT、GPT、Transformer-XL等)。