




- @liupras
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
涌现能力是在模型参数增加到某一临界点后突然出现的,这些能力包括但不限于语言理解能力、生成能力、逻辑推理能力等,而这种能力是小模型所不具备的。这也是为什么chat GPT出现后让人眼前一亮:和它聊天与真人无异,不像是机器了!这主要应该归功于大模型的涌现能力。

这是从零开始搭建langchain本地化RAG服务(本地部署的lamma3.1+本地部署的chroma)的保姆级教程
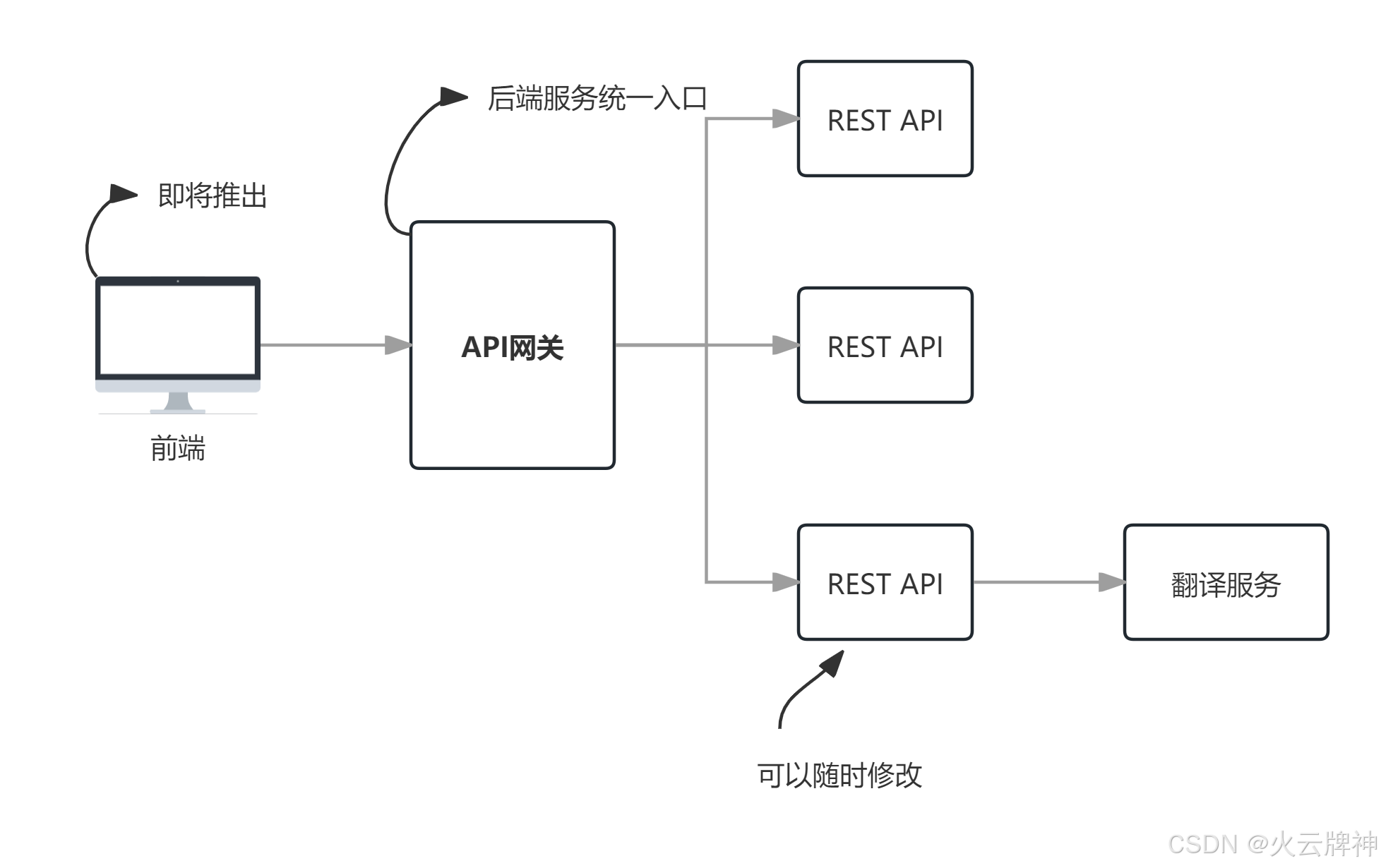
本文讲述了如何使用FastAPI和langchain框架,包装本地大模型llama3.1,实现语言翻译功能的API。相对于Flask,使用FastAPI做接口要简便得多。
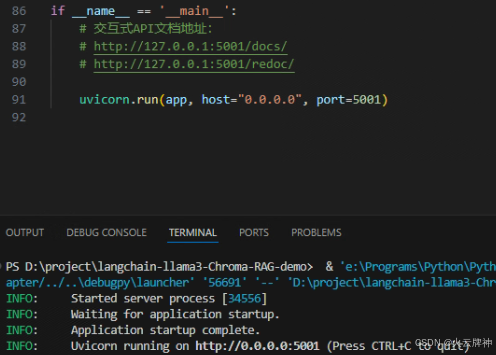
这是从零开始搭建langchain本地化RAG服务(本地部署的lamma3.1+本地部署的chroma)的保姆级教程
本文讲述了如何使用FastAPI和langchain框架,包装本地大模型llama3.1,实现语言翻译功能的API。相对于Flask,使用FastAPI做接口要简便得多。
涌现能力是在模型参数增加到某一临界点后突然出现的,这些能力包括但不限于语言理解能力、生成能力、逻辑推理能力等,而这种能力是小模型所不具备的。这也是为什么chat GPT出现后让人眼前一亮:和它聊天与真人无异,不像是机器了!这主要应该归功于大模型的涌现能力。
涌现能力是在模型参数增加到某一临界点后突然出现的,这些能力包括但不限于语言理解能力、生成能力、逻辑推理能力等,而这种能力是小模型所不具备的。这也是为什么chat GPT出现后让人眼前一亮:和它聊天与真人无异,不像是机器了!这主要应该归功于大模型的涌现能力。
涌现能力是在模型参数增加到某一临界点后突然出现的,这些能力包括但不限于语言理解能力、生成能力、逻辑推理能力等,而这种能力是小模型所不具备的。这也是为什么chat GPT出现后让人眼前一亮:和它聊天与真人无异,不像是机器了!这主要应该归功于大模型的涌现能力。