




- @limanjihe
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
人工智能浪潮正以前所未有的速度重塑全球产业格局。在这场技术革命的底层,神经网络处理器(Neural Processing Unit,NPU)扮演着极为关键的角色。从智能手机中每日无声处理亿万次推理请求的端侧芯片,到为超大规模语言模型训练提供算力支撑的数据中心加速卡,NPU已经成为数字经济时代最重要的基础设施之一。从技术背景、基本原理、发展脉络、核心性能指标、体系结构设计、重要里程碑以及与大型语言模

人工智能浪潮正以前所未有的速度重塑全球产业格局。在这场技术革命的底层,神经网络处理器(Neural Processing Unit,NPU)扮演着极为关键的角色。从智能手机中每日无声处理亿万次推理请求的端侧芯片,到为超大规模语言模型训练提供算力支撑的数据中心加速卡,NPU已经成为数字经济时代最重要的基础设施之一。从技术背景、基本原理、发展脉络、核心性能指标、体系结构设计、重要里程碑以及与大型语言模
LPU 是为 AI 推理"量身定制"的芯片:用流水线传送带代替无序调度,用片上 SRAM 代替外部内存,用编译器静态规划代替硬件动态决策——用专用换来了极致速度。它不打算替代 GPU 训练模型,而是要让训练好的模型在推理时更快、更省、更稳定地服务用户。参考来源Groq 官方技术白皮书Groq 官方技术博客— 官方架构说明页(基于 Groq 在 ISCA 2020/2022 发表的学术论文)Hype

TurboQuant 用数学上最接近"终极极限"的方式,把大语言模型运行时的工作内存压缩了 6 倍以上,计算速度提升 8 倍,且不需要训练、不损失精度——这是一个真正由理论驱动、有实际落地价值的算法突破。如果说 DeepSeek 证明了"用更少的钱训练更好的模型",那 TurboQuant 证明的是:"用更少的内存运行已有的模型"。两者合力,正在重新定义 AI 基础设施的经济学。
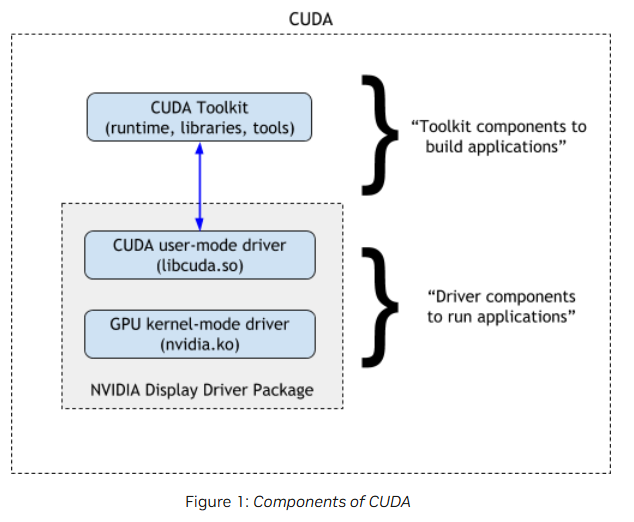
reference:CUDA从入门到精通NVIDIA CUDA初级教程视频1.CUDA环境搭建;2.CUDA算力估计;3.并行编程;4.线程编程及通信;
人工智能浪潮正以前所未有的速度重塑全球产业格局。在这场技术革命的底层,神经网络处理器(Neural Processing Unit,NPU)扮演着极为关键的角色。从智能手机中每日无声处理亿万次推理请求的端侧芯片,到为超大规模语言模型训练提供算力支撑的数据中心加速卡,NPU已经成为数字经济时代最重要的基础设施之一。从技术背景、基本原理、发展脉络、核心性能指标、体系结构设计、重要里程碑以及与大型语言模
reference : http://blog.sina.com.cn/s/blog_4c270c730101f6mw.html 断言assertion被放在verilog设计中,方便在仿真时查看异常情况。当异常出现时,断言会报警。一般在数字电路设计中都要加入断言,断言占整个设计的比例应不少于30%。以下是断言的语法:1. SVA的插入位置:在一个.v文件
http://blog.csdn.net/bruce0532/article/details/7865800Windows下的源码阅读工具Souce Insight凭 借着其易用性和多种编程语言的支持,无疑是这个领域的“带头大哥”。Linux/UNIX环境下呢?似乎仍然是处于百花齐放,各有千秋的春秋战国时代,实 际上,似乎其环境下的任何软件都是处于一种逐鹿中原的态势,也许这就是“集市”之于“大教
创建环境,所有项⽬都依赖⼀个虚拟环境(不建议不同项⽬混⽤环境,容易出现不兼容的问题),我们使⽤conda指令进⾏环境的搭建和配置。激活当前环境,从base环境切换到刚创建好的名为‘torchʼ的环境。conda install -n name selenium 指定环境安装package,不加-n则安装在当前。conda remove -n name selenium 删除package,不加-n
MBIST:用于嵌入式存储器的可测试设计技术作者:牛风举,DFT应用工程师明导(上海)电子科技有限公司术可以自动实现存储器单元或阵列的RTL级内建自测试电路,MBIST的EDA工具支持多种测试算法的自动实现,可针对一个或多个内嵌存储器自动创建BIST逻辑,并完成BIST逻辑与存储器的连接,此外MBIST结构中还可包括故障自动诊断功能,方便了故障定位和开发针对性测试向量。本文