- @li11_
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
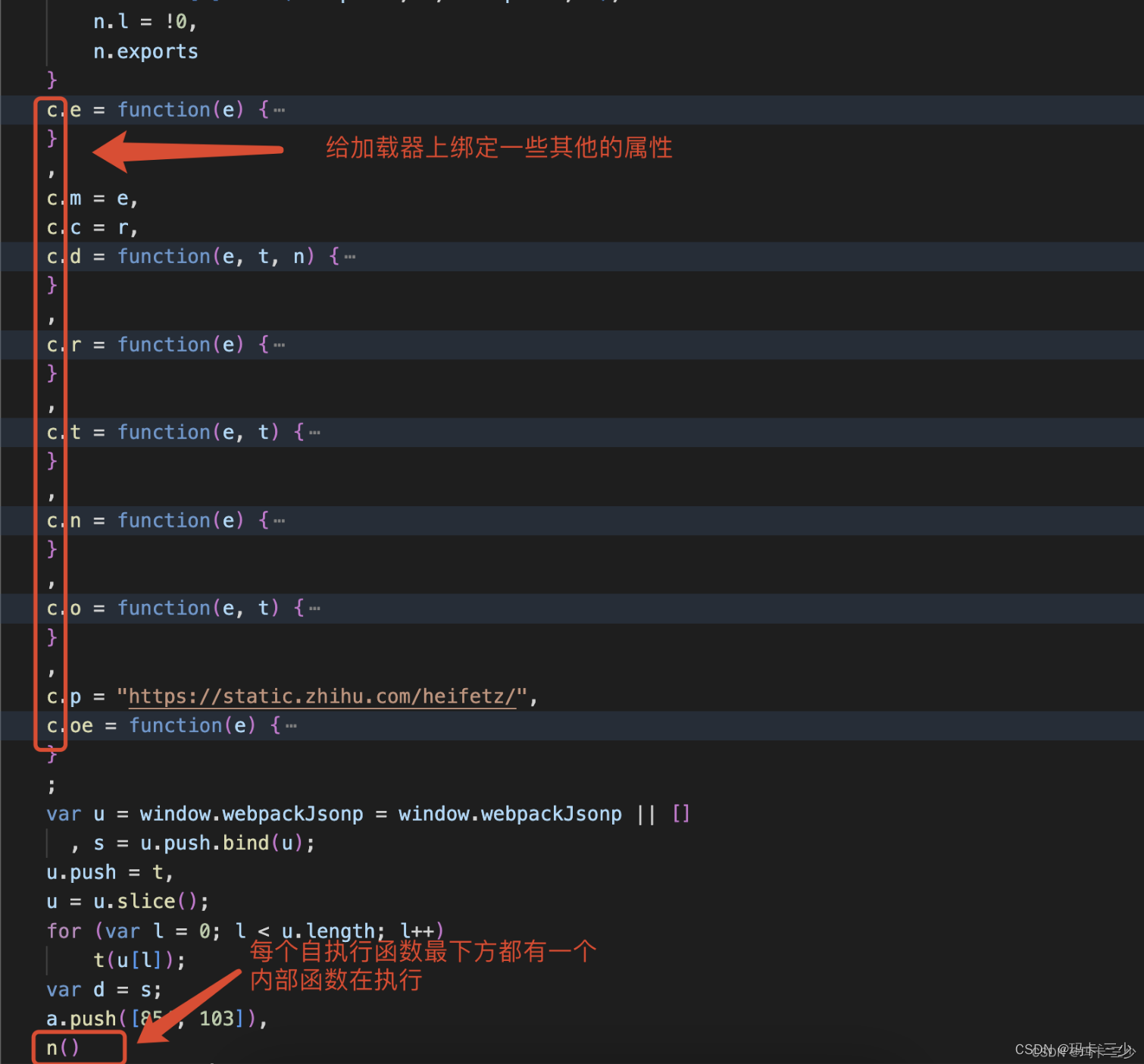
声明:XX手机社区加密逆向分析仅用于研究和学习这篇文章的学习内容是以XX手机社区为案例,对逆向的整个过程进行详细分析;下面会进行以下几步进行分析(下方演示过程全部使用浏览器);进入社区,随便操作一下即可锁定查询接口,如下图:我们多请求几次,对比一下请求数据,找到可疑的加密参数,发现请求头里没有变化的参数,请求参数里有一个字段每次都不一样,那应该就是这个字段了,下面老规矩,我们搜索这个字段,看看它是

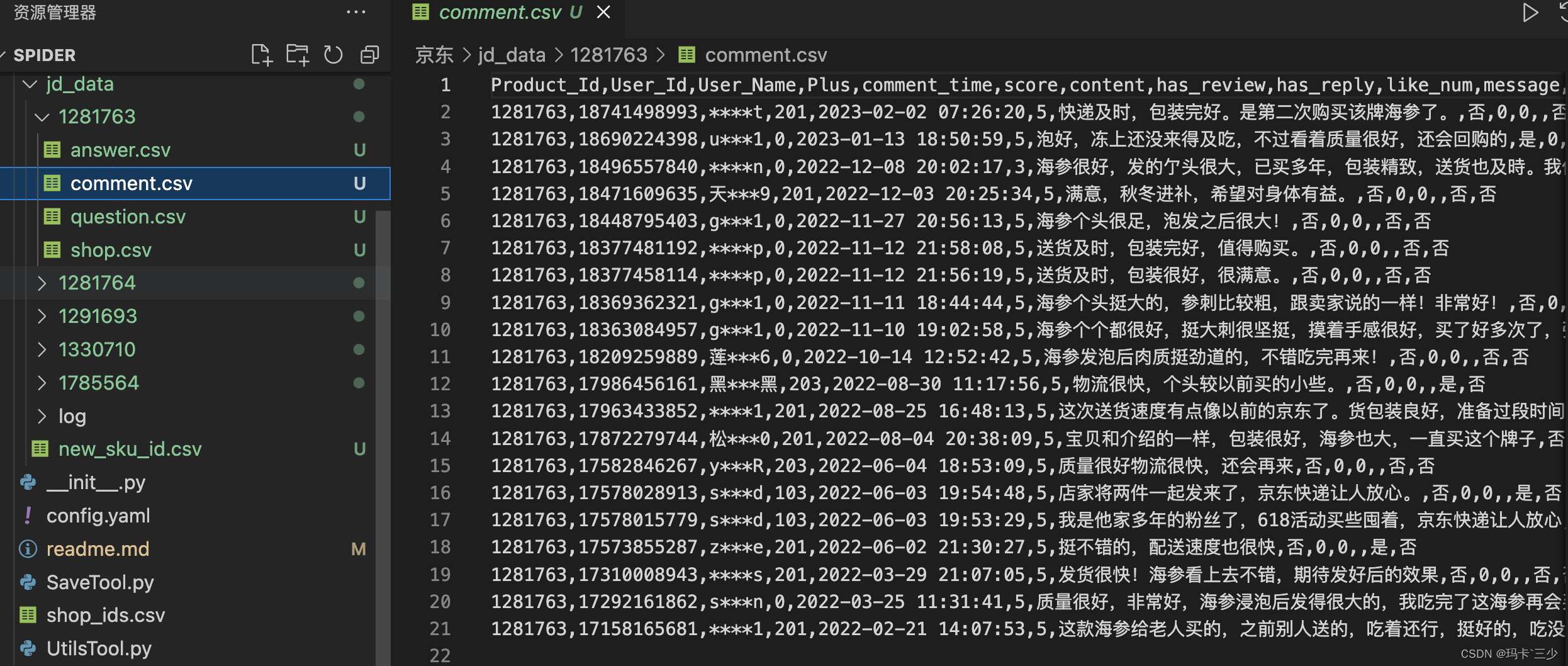
爬取任意问题下的所有回答,如下图:1.根据问题,批量获取问题下的所有回答、与对应问题的关系到answer.csv文件;2.保存当前问题基本信息到quesiton_info.csv文件;

总结:程序一键运行,过程中错误中断自动保存日志到log文件,方便后续分析!
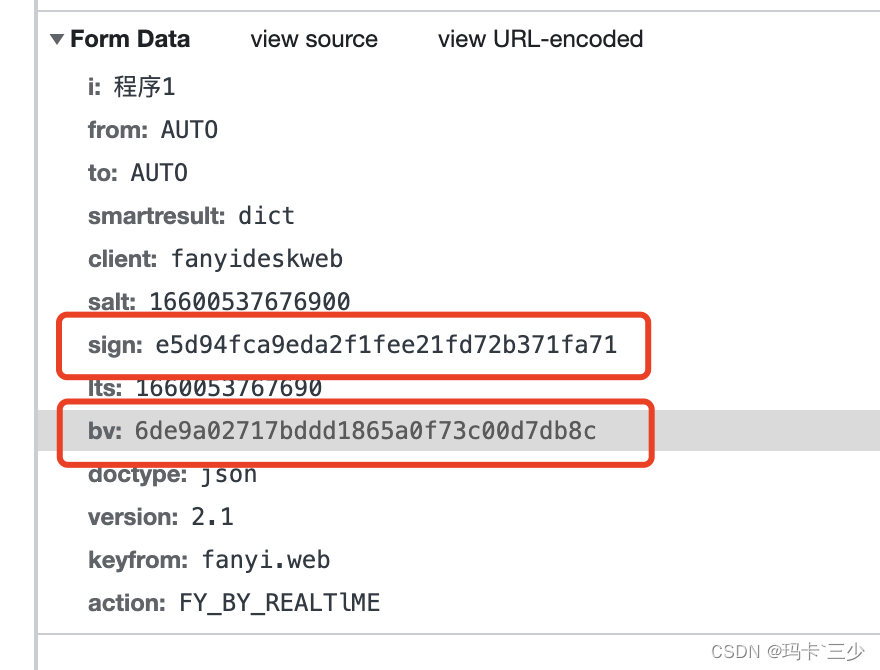
在web项目中跨域请求api时,api登录成功后需要向域名中设置cookie实现域名的共享,但是登录接口返回成功,也设置的set-cookie,实际却无法设置到cookie中…当然只开启这个参数也不行,还需要后端配合其他配置,上面的《Cors跨域(二):实现跨域Cookie共享的三要素》文章中详细说明了服务端的配置,这里就不重复了;我的问题主要原因是前端需要在Axois中开启。上面这个参数默认是关

大家好,举例上次分享js逆向案例已经有一个月了,在这期间每次在快要揭秘出来时、整理文章的时发现某乎的加密又又又更新了、、、,导致近期长时间没有更新文章了。同时也收到了很多童鞋的催更,这里说一下哈,并不是我忘记了,或者懈怠了,只是一直在从头逆向某乎而已、、、为了继续更新逆向100例,我决定先暂停某乎的文章输出,等稳定了在案例一下,不然今天扣的代码明天又不能用了、、、,还是先分享其他平台的案例吧,这里
大家好,应同学们私信要求,出一篇关于微博博主已发布的内容脚本可视化的案例,于是整理了一下,仅供学习参考。

如果数据是来自服务端API接口,当你按上图操作翻页时,右侧空白面板处会出现请求记录,此时页面数据就是通过接口返回的;如果像上面这种,翻页操作之后还是空白,说明数据不是通过接口返回的。对于一个目标网站,该如何快速判定页面上的数据来源?首先你需要简单web调试能力,对大多数开发者来说都chrome浏览器应该是不二选择,当然我选中的也是。爱学习的小伙伴,本次案例的完整源码,已上传微信公众号“一个努力奔跑

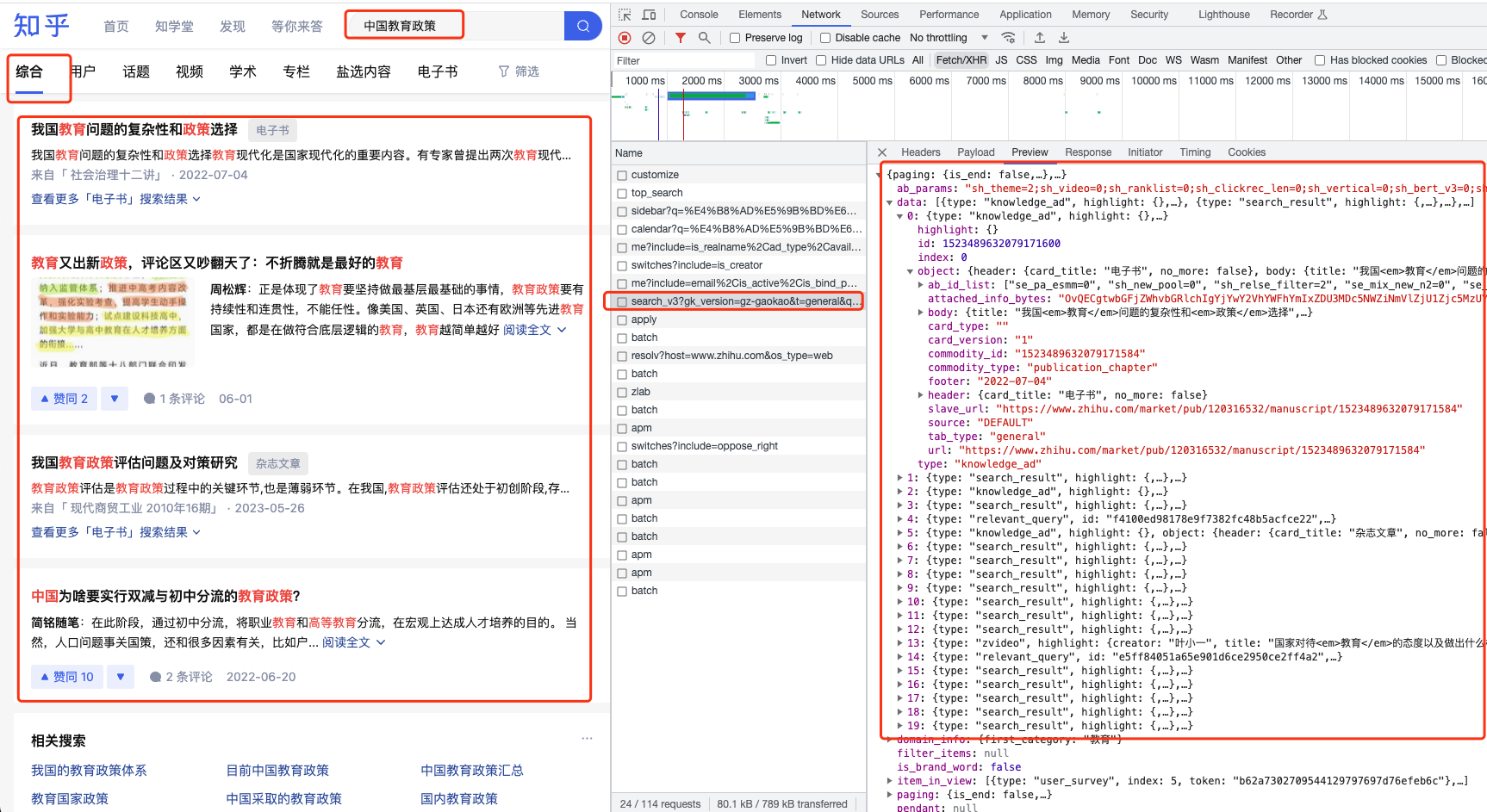
根据输入的任意关键词,整理出关键词相关话题,并收集符合条件话题的id、话题链接;如下图:1.综合搜索tab栏展示结果比较全面,但该栏数据包含小说、视频,因此拿到结果需要过滤;2.只保存三种类型的文章作后续分析:话题、专栏、严选内容;3.数据保存格式 *.csv;
Scrapy框架Jd实战练习,效果简直666呀!快来围观!
webpack官网中的一句原话是这样说的:本质上,webpack是一个现代JavaScript应用程序的静态模块打包器(module bundler)。当 webpack处理应用程序时,它会递归地构建一个依赖关系图(dependencygraph),其中包含应用程序需要的每个模块,然后将所有这些模块打包成一个或多个 bundle。正如上面描述的一样,这个东西就是一款现代化的前端模块打包工具而已!!