




- @lemonzjk
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
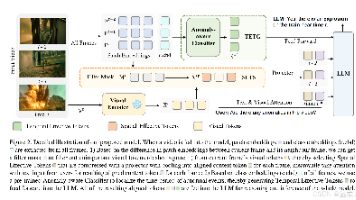
这篇论文的主要创新是提出了一种新的多模态大语言模型(VA-GPT),通过空间有效令牌选择(SETS)和时间有效令牌生成(TETG)模块,提升了视频异常检测的空间和时间定位能力。主要还是以前的方法确实没有这种去选择有效token的,相当于过滤掉了冗余的信息,并给模型一些最有用的信息。
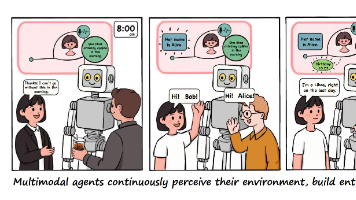
这篇论文的创新是提出 M3-Agent,把视频/音频流转成“实体中心”的情节记忆+语义记忆,并用RL训练的多轮检索-推理控制器在记忆上迭代推理(模型生成问题去查询,优于单轮RAG),并以 M3-Bench 长视频跨模态基准验证其有效性。
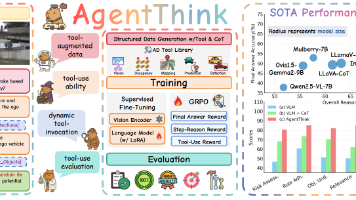
这篇论文的创新点是 首次将动态的工具调用与链式推理统一到自动驾驶视觉语言模型中,通过结构化数据(构建微调数据)、两阶段训练(SFT+GRPO)和专门的工具使用评估显著提升了推理一致性、可解释性和决策准确性。
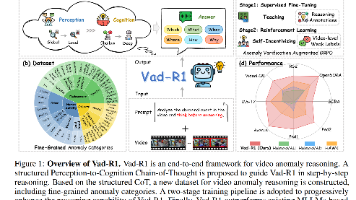
针对传统视频异常检测仅能判断“有无”而缺乏因果推理的局限,提出视频异常推理(VAR)任务,并构建端到端框架 Vad-R1。框架引入感知-认知四阶段 Chain-of-Thought,引导模型由全局场景逐步聚焦至异常本质;同时发布 8 k+ 视频组成的 Vad-Reasoning 数据集,其中 1.8 k 样本含高质量推理链用于监督微调,其余 6 k+ 样本仅具弱标签。为利用弱标注强化推理可靠性,设
对视频异常检测领域的一些论文的性能的整理

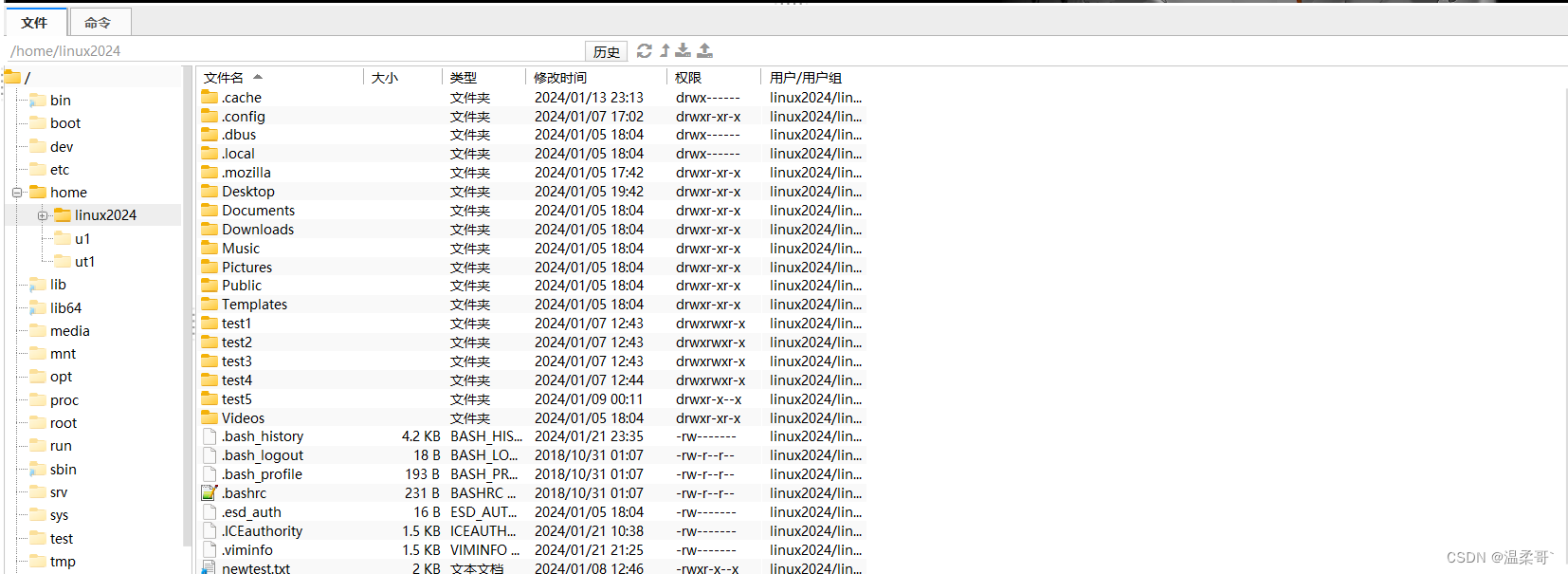
注意:我们是通过linux2024用户登录的FinalShell,所以我们不能访问root的文件夹,如果想要拥有最大权限,请使用root用户登录FinalShell。注意:会下载到和我们FianlShell一样的文件中(默认下载到桌面的:fsdownload文件夹中)还有一点,rz的上传速度要比直接往FinalShell中拖动来上传要慢很多,所以我们平常。,然后选择要上传的文件即可,会上传到当前工
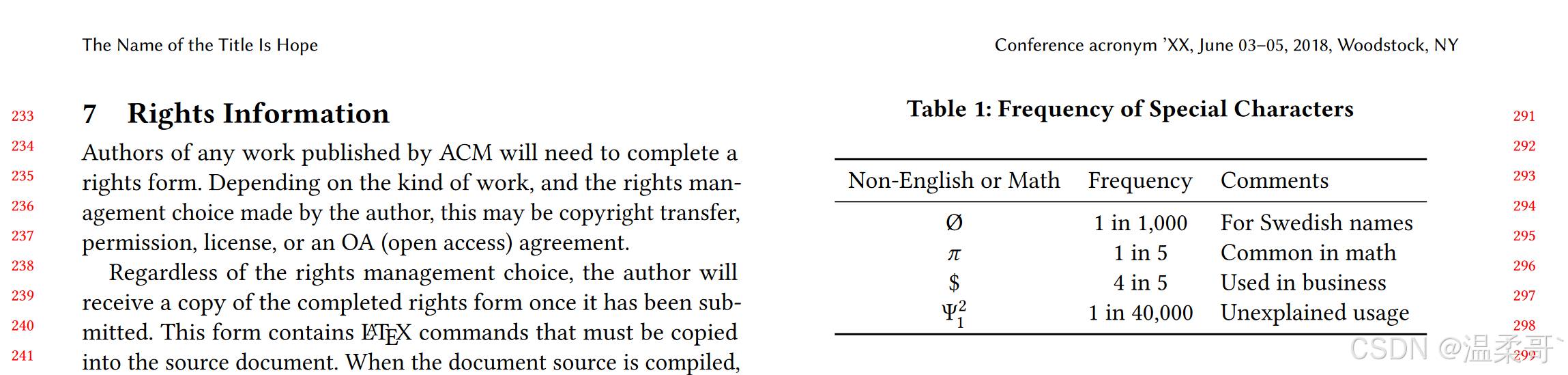
本文介绍了 ACM 文章的排版模板 “acmart” 的使用方法,涵盖了文档结构、格式化规则、数学公式、图像、表格、引用格式以及多语言支持等内容。文章详细说明了如何正确使用 $\LaTeX$ 进行章节划分、插入图表、编写数学公式,并遵循 ACM 期刊和会议论文的格式要求。此外,还包括了 SIGCHI 扩展摘要的特殊格式、附录的使用、致谢部分的编写,以及参考文献的管理方式。本文提供了具体的代码示例和
这篇论文提出了一种新型的视频异常检测方法,称为AnyAnomaly。该方法通过零-shot的方式,利用大规模视觉语言模型(LVLM)和上下文感知的视觉问答(VQA)技术,解决了传统视频异常检测方法在多种环境下泛化能力不足的问题。AnyAnomaly不需要额外的训练数据,用户可以通过自定义异常事件的文本描述来检测视频中的异常,适用于各种不同的视频环境。实验表明,AnyAnomaly在多个标准数据集上
