




- @kof820
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文探讨了从SEO(搜索引擎优化)到GEO(生成式引擎优化)的范式转移。随着生成式AI搜索的崛起,传统基于关键词排名的SEO逻辑被颠覆,GEO更注重让内容被AI识别、信任并引用。文章分析了GEO的技术原理(RAG管线)和实操方法,如结构化内容、引用权威实体、部署Schema数据等。同时指出GEO可能被滥用于"AI投毒"等黑产问题。作者认为,GEO是将内容分发升级为"让AI理解并信任你的信息"的过程

Anthropic发布两款新AI模型:面向公众的Claude Fable 5和受限制的Claude Mythos 5。Fable 5在软件工程、知识工作、视觉理解等方面有显著提升,但加入了严格的安全机制,5%的敏感请求会降级处理。Mythos 5是能力更强的未约束版本,仅限安全研究机构使用。Fable 5已开放给付费用户试用,6月23日起正式收费。此次发布采用"能力拆分"策略,在模型性能和安全性之
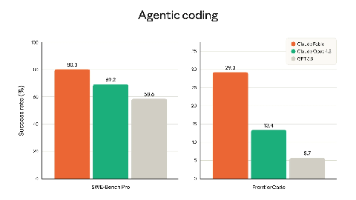
Anthropic发布两款新AI模型:面向公众的Claude Fable 5和受限制的Claude Mythos 5。Fable 5在软件工程、知识工作、视觉理解等方面有显著提升,但加入了严格的安全机制,5%的敏感请求会降级处理。Mythos 5是能力更强的未约束版本,仅限安全研究机构使用。Fable 5已开放给付费用户试用,6月23日起正式收费。此次发布采用"能力拆分"策略,在模型性能和安全性之
国内AI厂商推出编程订阅套餐横向对比:MiniMax最低29元/月,阿里云百炼首月7.9元;智谱GLM编程能力突出,149元/月;火山引擎支持6款模型,首月8.91元。建议预算有限选MiniMax或阿里云,追求编程能力选智谱GLM,多模型需求选火山引擎/阿里云。数据截至2026年2-3月,建议购买前核实最新价格。

拖动滑块验证是一种常见的人机验证技术,用于区分真实用户和自动化程序(如机器人)。其核心原理不仅在于用户是否能将滑块移动到正确位置,还包括对拖动行为的轨迹、速度、加速度等特征的分析。滑块验证的核心是通过行为特征(而非仅位置正确性)区分人机。其技术结合了计算机视觉、行为分析和机器学习,未来可能进一步引入生物特征(如压力感应)以提高安全性。

http://pan.baidu.com/netdisk/beinvited?invite_code=be71291c3844b684d4b165787fe2a28bhttp://pan.baidu.com/netdisk/beinvited?invite_code=a3b7c5edacfbc505e93591cd07b90a45http://pan.baidu.com
使用OSS(阿里云开放云存储)存储文件时,为了保证文件的安全性和唯一性,文件名全部sha1加密过了。但是这样的话,当用户下载文件时,文件名会是一堆加密串(如:651a53c4ea021589c00e26b5d0d50b96dfafb2d7.doc),如何才能让用户下载文件时是原名(如:周伯通招聘.doc)?靠谱的方法有两种:1. 上传文件至OSS时设置HTTP的Content-Di
**NotebookLM**:AI 研究助手,基于上传资料生成播客、简报等,零门槛。**Google AI Studio**:AI 开发平台,用自然语言创建和部署应用,适合开发者。前者帮你理解资料,后者帮你创造应用。

今年年初 OpenClaw(曾用名 Clawdbot 后改名 Moltbot)就很火,没想到过了个春节更火了。火爆程度很像去年春节后的 DeepSeek。不敢在自己工作电脑上直接安装(权限太大,风险太高),本篇指南将带你从零开始在本地搭建并初始化 OpenClaw。
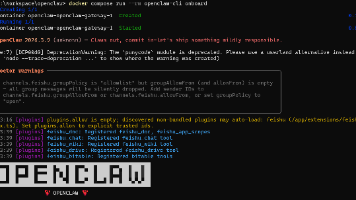
今年年初 OpenClaw(曾用名 Clawdbot 后改名 Moltbot)就很火,没想到过了个春节更火了。火爆程度很像去年春节后的 DeepSeek。不敢在自己工作电脑上直接安装(权限太大,风险太高),本篇指南将带你从零开始在本地搭建并初始化 OpenClaw。